Downloaded 41 times



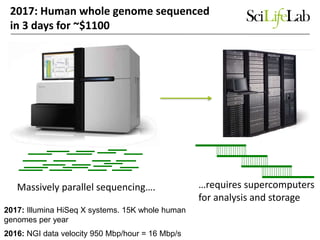
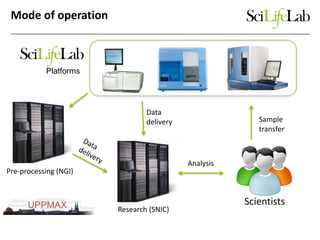
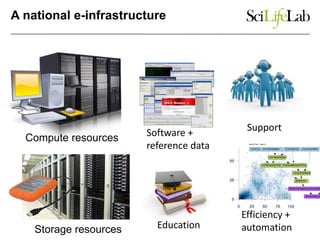

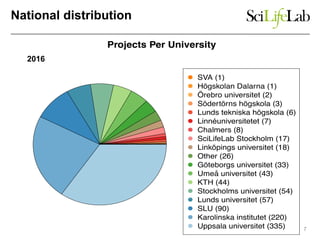
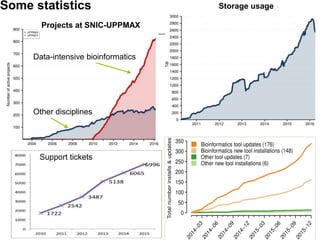


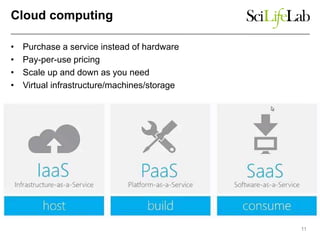




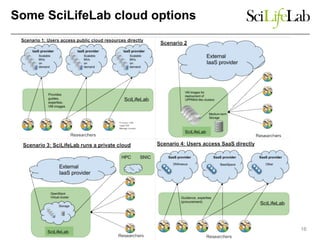
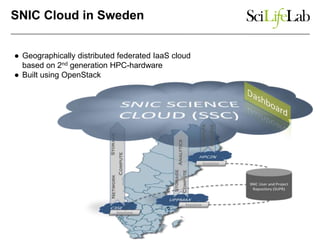
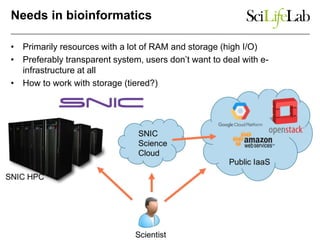
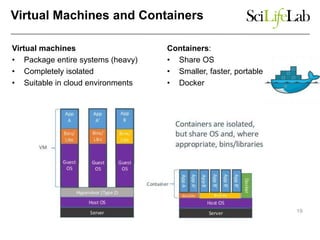

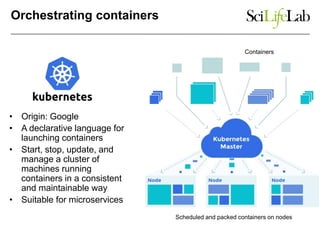
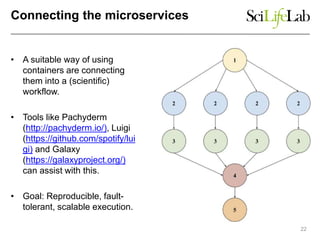
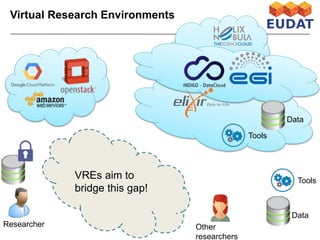
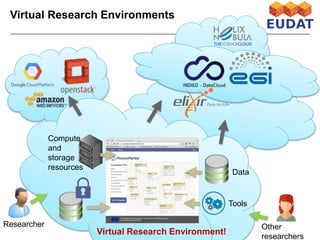



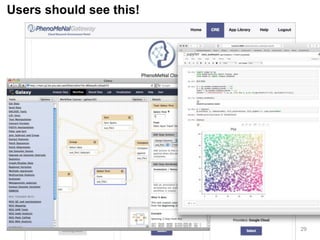
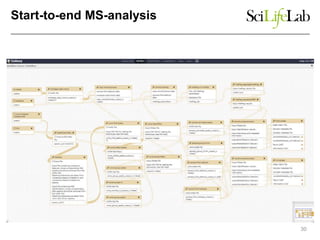
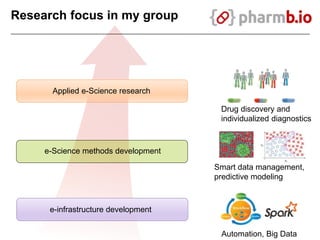
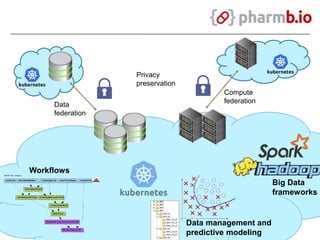
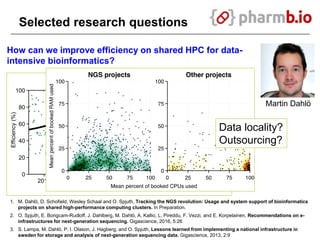
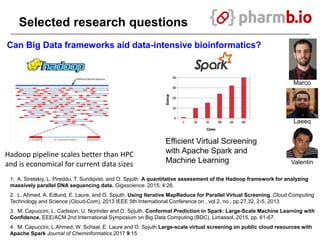
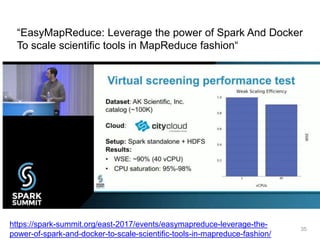



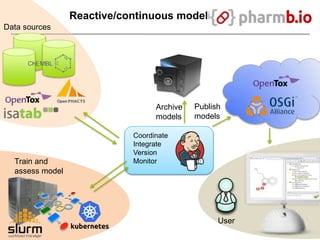

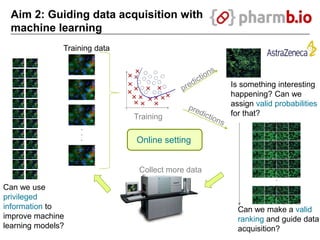
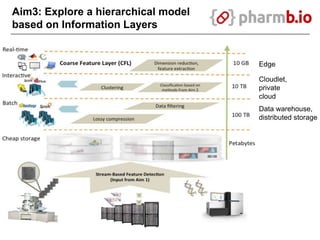



The document discusses data-intensive bioinformatics and challenges with analyzing large genomic datasets on high performance computing (HPC) resources. It summarizes that storage is the biggest challenge as sequencing projects generate very large amounts of data and users do not clean up data. The strategies discussed to address this include assessing costs of storage and analysis upfront, limiting project lifetimes, moving to tiered storage, and improving efficiency. It also discusses using cloud computing resources through virtual clusters and containers to enable flexible, on-demand access and pay-per-use pricing models. Scientific workflows and microservices approaches are presented as ways to automate and orchestrate large-scale genomic analyses on distributed computing resources.


































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)












