Download as PDF, PPTX


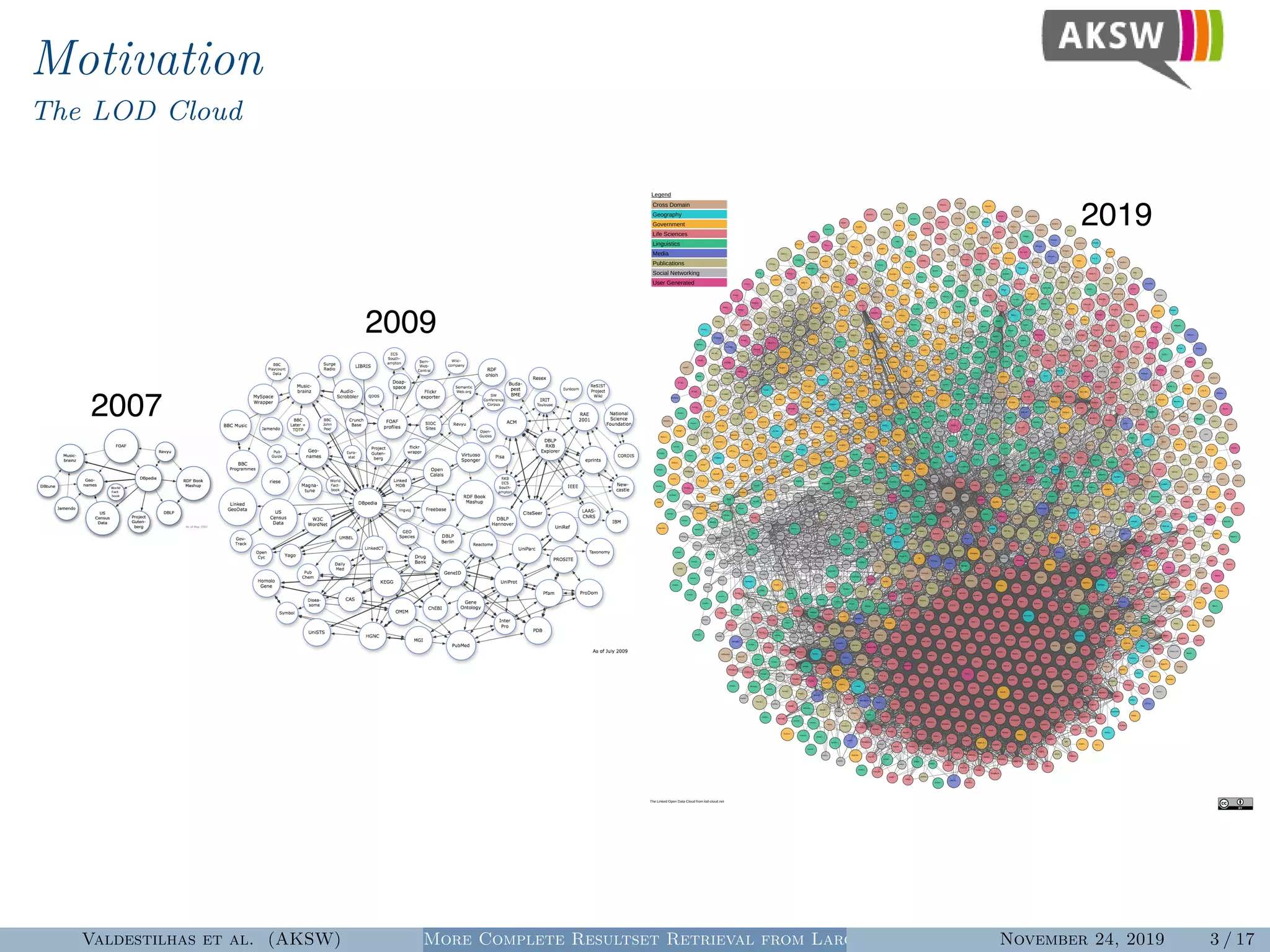
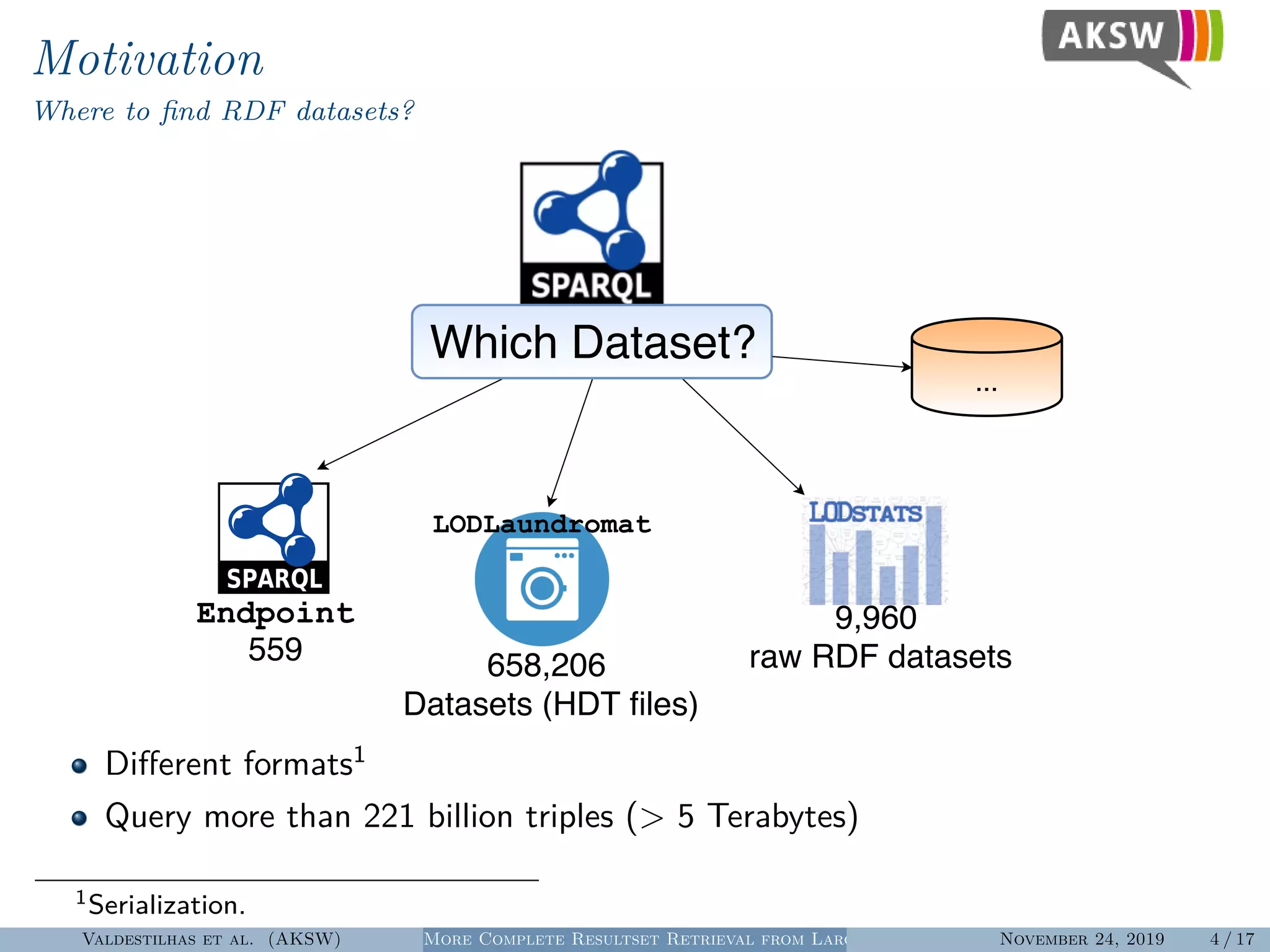


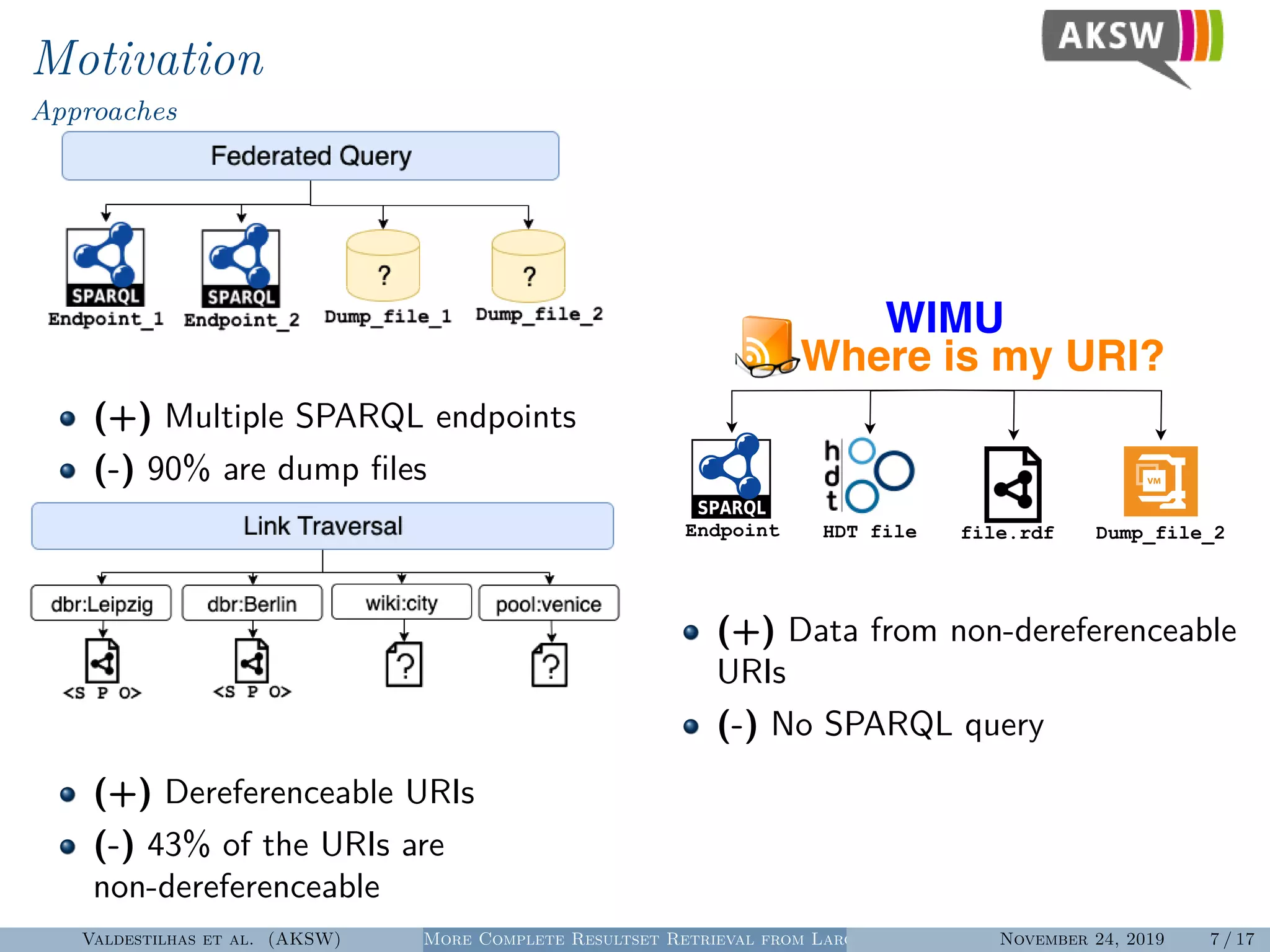

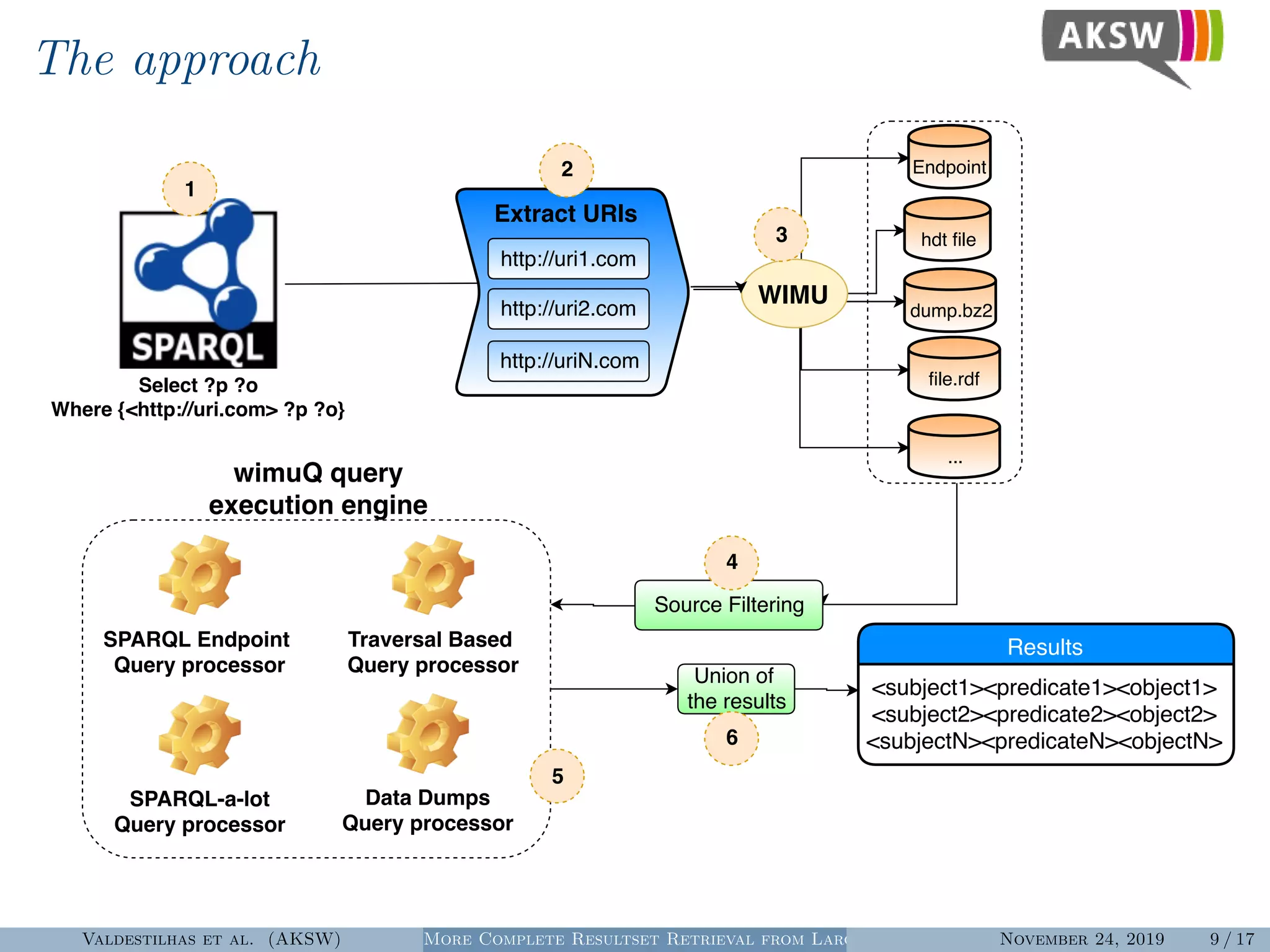
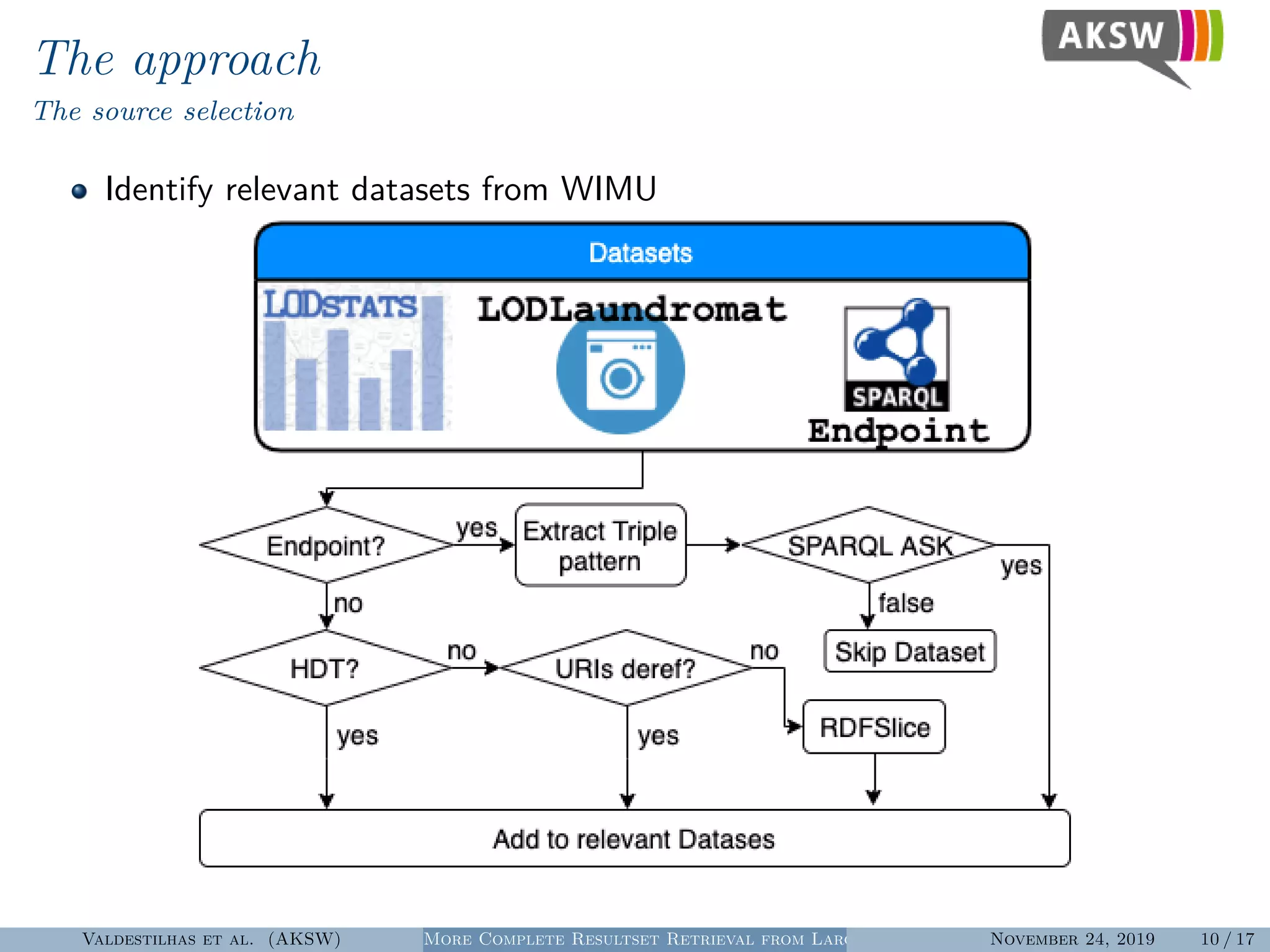


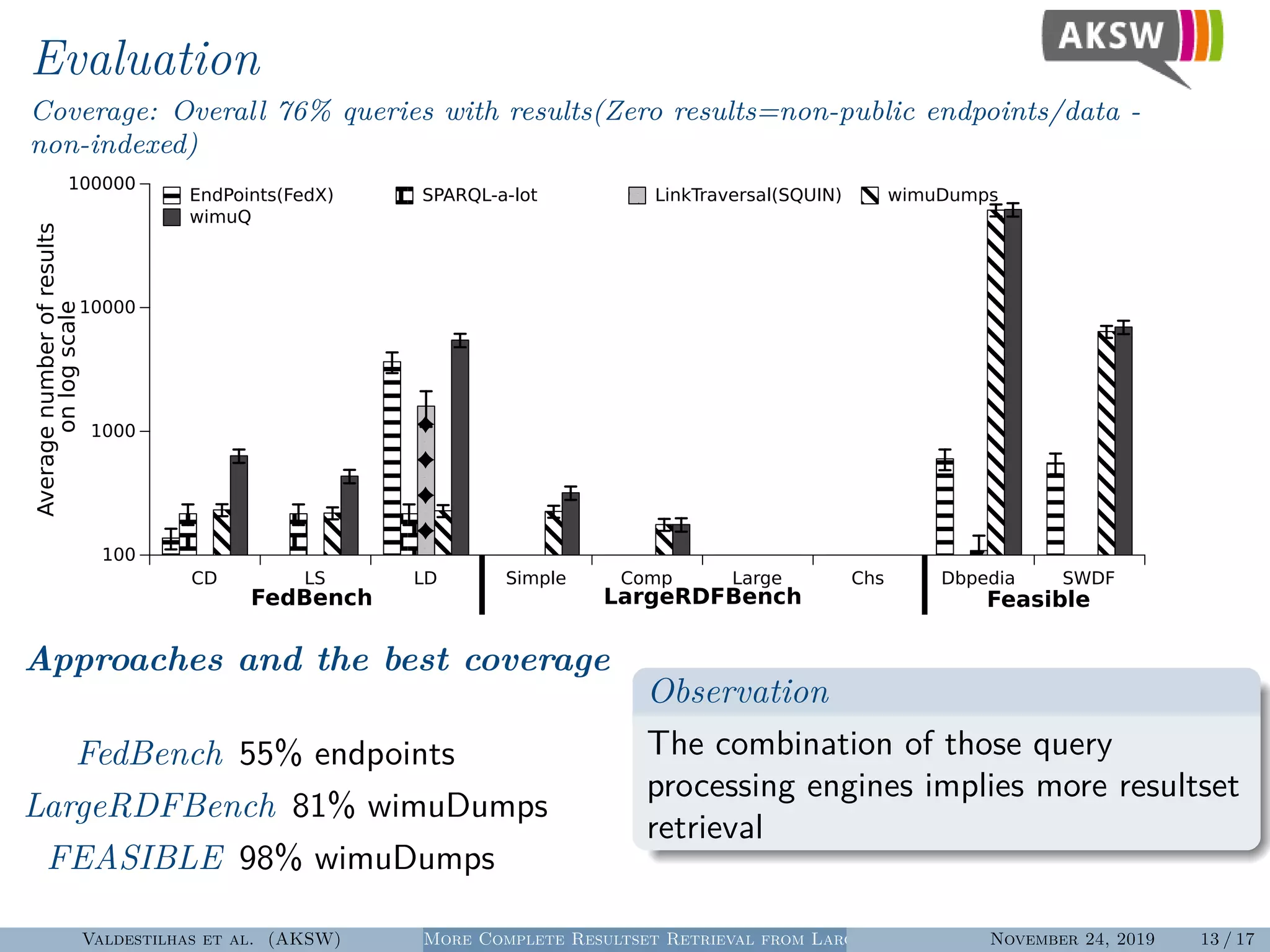
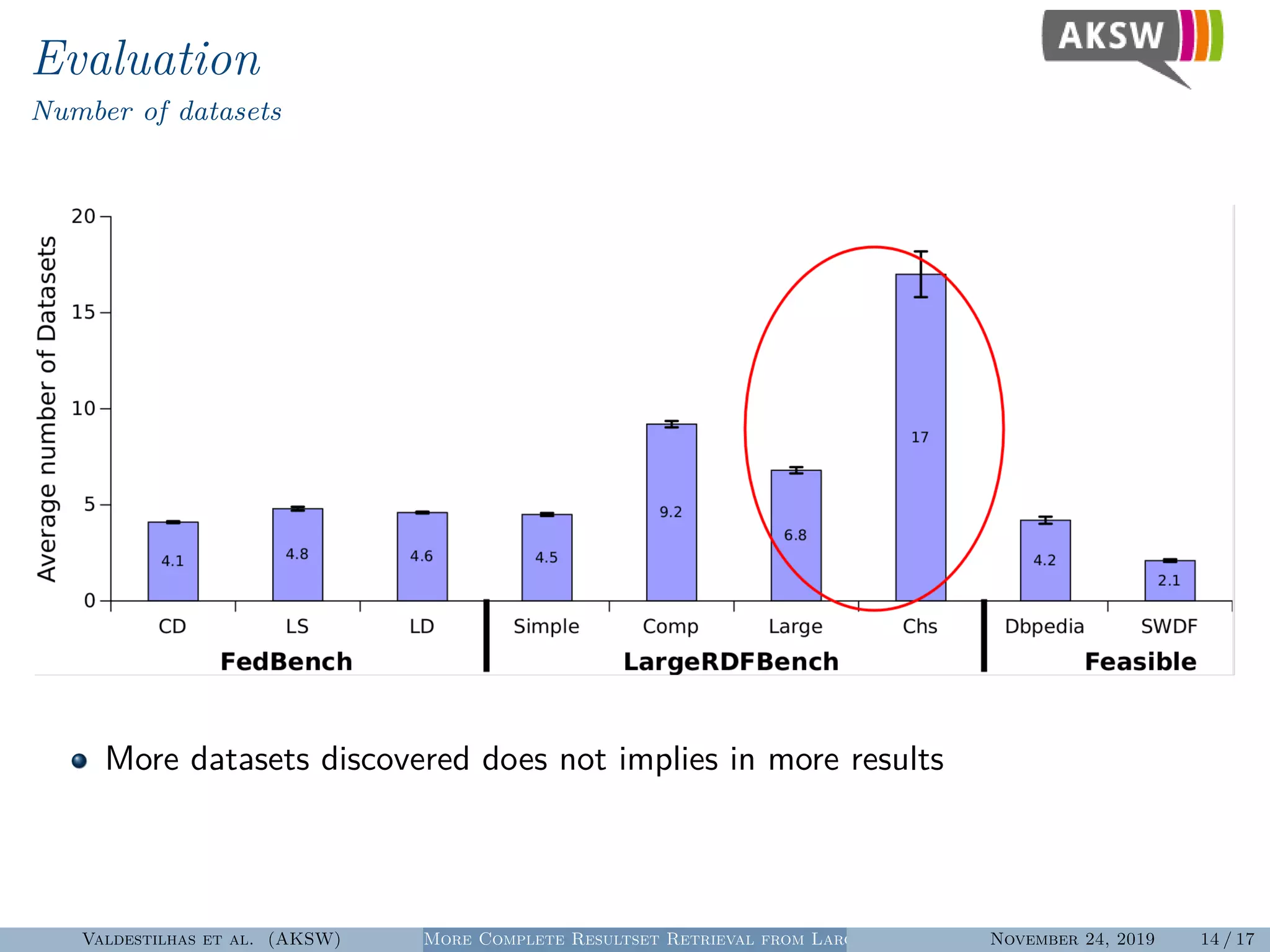
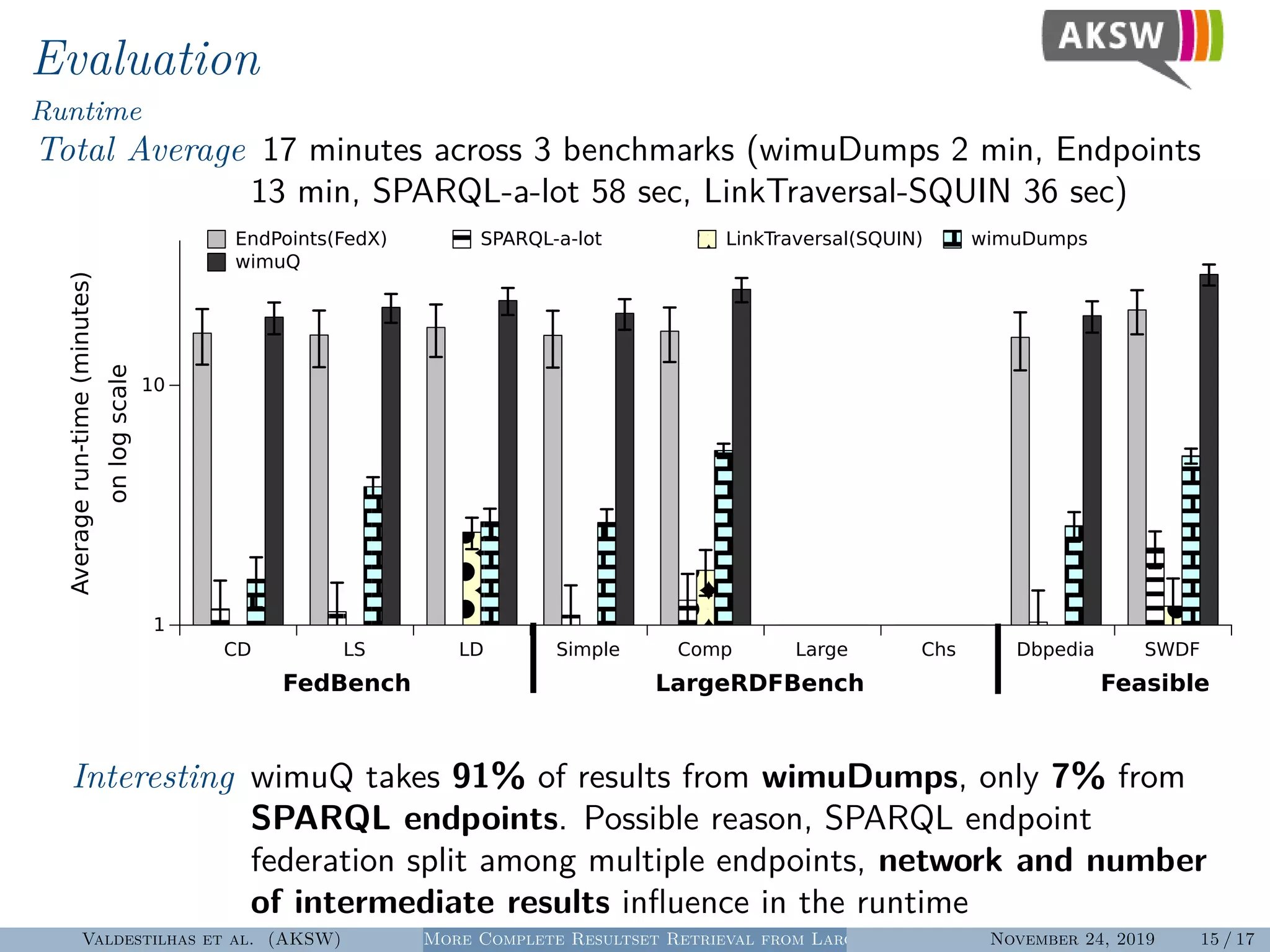



The document presents a hybrid SPARQL query processing engine designed to improve resultset retrieval from large heterogeneous RDF sources. It evaluates the effectiveness of various methods, including data collection from multiple SPARQL endpoints and RDF dumps, achieving better coverage and runtime metrics. The results indicate that the hybrid approach enhances data retrieval, with plans for future work to expand the URI index and analyze dataset similarities.















































































