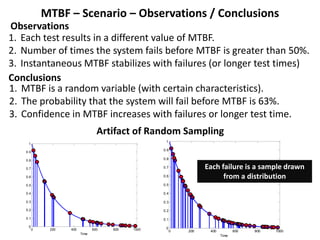
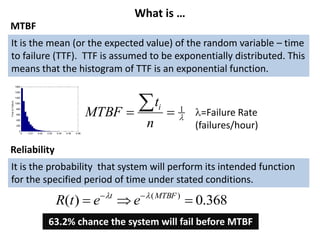
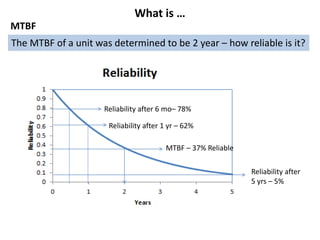
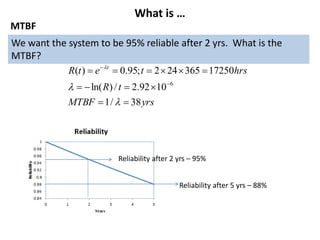
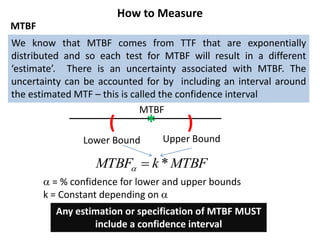
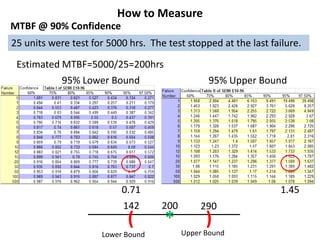
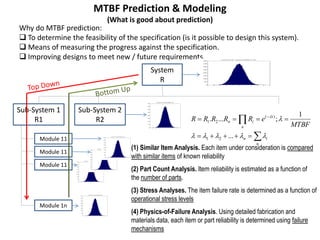
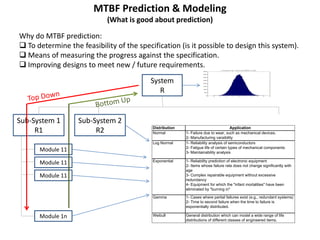
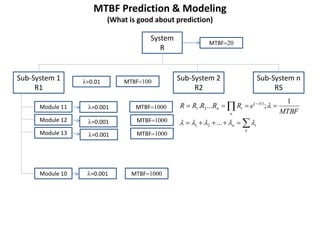
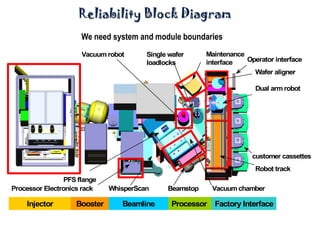
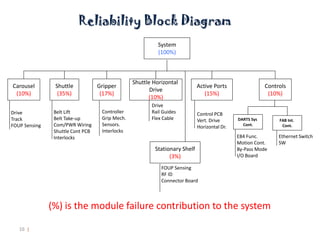
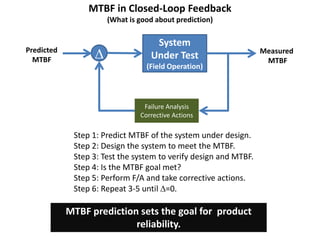
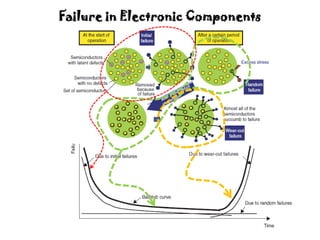
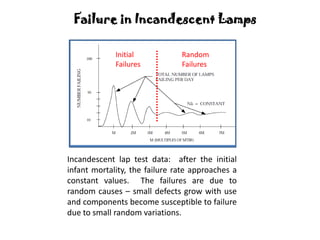
The document discusses MTBF (mean time between failures), including how to calculate, predict, and test it. It addresses common misconceptions about MTBF and describes a two-day training plan that covers the basics of MTBF as well as how to analyze MTBF reports and predictions. The training provides answers to questions and considers reliability modeling techniques to estimate component and system-level MTBF.