Downloaded 14 times




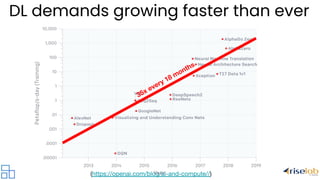
































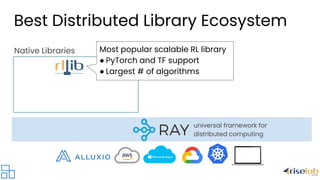



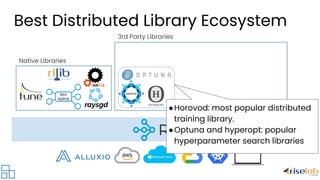
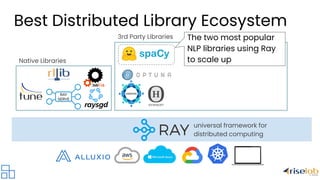













The document discusses the evolution and current challenges of distributed computing, highlighting the increasing demand driven by deep learning and the limitations posed by the end of Moore's Law. It emphasizes that the shift towards AI-centric applications necessitates a move to distributed systems for scalability and integration with existing workloads. The document also presents Ray as a universal framework for distributed computing, promoting its ecosystem of libraries and tools for scalable machine learning and AI applications.






































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)
















