Download as PDF, PPTX




![Copyright@ 2015 by SK Telecom All rights reserved.
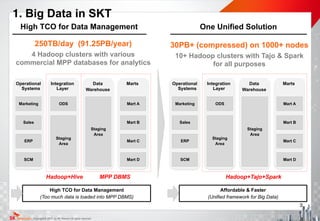
Tajo
- Fully Distributed
- Vector process
HDFS
Hadoop Cluster + Tajo
[ Legacy Approach (MR) ] [Tajo Approach ]
Process more data
on same clusters
with improved
processing speed
Response
Speed
Hadoop
Cluster
Query
Hadoop
Cluster
Query
Up to
10x min few
sec~min
+ Tajo
Try more queries
for analysis
with improved!
response speed
Hive
MapReduce
- Partially Distributed
- Sequential process
HDFS
Hadoop Cluster
Processing
Speed
High-speed SQL-on-Hadoop processing engine
• 3~5x improvement in processing speed to Hive under TPC-H procedure
• 80~100% response speed to Impala without data size limit
• Full ANSI-SQL support for easy RDBMS migration
3. SQL on Hadoop - TAJO
6](https://image.slidesharecdn.com/skthadoopicdefinal-160927121418/85/IEEE-International-Conference-on-Data-Engineering-2015-6-320.jpg)
![Copyright@ 2015 by SK Telecom All rights reserved.
7
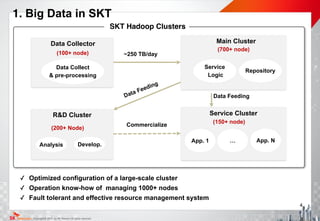
3. SQL on Hadoop - TAJO
SQL Support
▪ ANSI SQL support
▪ Partition Type
▪ Meta Store
Service Stability
▪ High Availability
▪ Resource Manager
▪ Fair Scheduler
Performance
▪ High-speed processing
▪ Shuffling
▪ Dynamic Query Optimizer
▪ Query Rewriting
System Integration
▪ BI Connector
▪ Proxy Support
▪ Tajo-R
Function Support
▪ Analytic Function
▪ Hive Function
[ Tajo Features ]
[ Performance Comparison ]
[ Apache Top-Level Project ]](https://image.slidesharecdn.com/skthadoopicdefinal-160927121418/85/IEEE-International-Conference-on-Data-Engineering-2015-7-320.jpg)
![Copyright@ 2015 by SK Telecom All rights reserved.
11
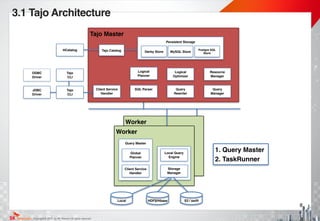
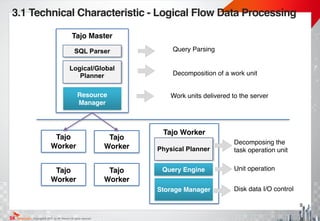
3.1 Technical Characteristic -Vectorized Query Engine
<Tuple at a time> <Vectorized engine>
- DB!
- 1 operation/record
- Vectorized data!
- 1 operation/vector
A[] = {a1, a2, a3, a4, a5, a6}!
B[] = {b1, b2, b3, b4, b5, b6}!
!
C[] = A[] + B[]
a1
a2
a3
a5
a4
a6
b1
b2
b3
b5
b4
b6
+
+
+
+
+
+
a1
a2
a3
a5
a4
a6
+
b1
b2
b3
b5
b4
b6](https://image.slidesharecdn.com/skthadoopicdefinal-160927121418/85/IEEE-International-Conference-on-Data-Engineering-2015-11-320.jpg)
![Copyright@ 2015 by SK Telecom All rights reserved.
13
Business Challenge
How SKT Hadoop DW Helped
[ SK Telecom ]
• Explosion of log data with LTE service
• Increase in types of data to be analyzed
• Insufficient DW capacity due to high cost
✓ 3x storage expansion under same price,
or 80% reduction in unit price
✓ Enabled Ad-hoc analysis of unstructured text
data sets for daily
✓ Hadoop DW could decrease contents-based
analysis process time from few hours to 20
minutes max.
4. Hadoop DW Commercialization Cases Telco
Category MPP DBMS Hadoop DW
Raw Data Size 0.5 TB/Day 4 TB/Day
Total ETL Time Average of 3 hours Average of 6 hours
DW Creation
!
30 minutes 40 minutes
Mart Creation 1 hour 1 hour 40 minutes
Report
Creation
1 hour 30 minutes 2 hours 4 minutes](https://image.slidesharecdn.com/skthadoopicdefinal-160927121418/85/IEEE-International-Conference-on-Data-Engineering-2015-13-320.jpg)
![Copyright@ 2015 by SK Telecom All rights reserved.
14
Business Challenge
[ Global Top-5 Semiconductor Player ]
• Collect immense amount of unstructured
measurement data while manufacturing
• RDMBS & BI are incapable for such data type
• Even data loading can take up to 20 min
How SKT Hadoop DW Helped
✓ Support for unstructured data through variable
column schema
✓ 100x increase in data processing capacity
✓ Decreased data loading time by 10x (2 min)
✓ Minimized user action for pivot/unpivot
4. Hadoop DW Commercialization Cases Manufacturer](https://image.slidesharecdn.com/skthadoopicdefinal-160927121418/85/IEEE-International-Conference-on-Data-Engineering-2015-14-320.jpg)


SK Telecom developed a Hadoop data warehouse (DW) solution to address the high costs and limitations of traditional DW systems for handling big data. The Hadoop DW provides a scalable architecture using Hadoop, Tajo and Spark to cost-effectively store and analyze over 30PB of data across 1000+ nodes. It offers SQL analytics through Tajo for faster querying and easier migration from RDBMS systems. The Hadoop DW has helped SK Telecom and other customers such as semiconductor manufacturers to more affordably store and process massive volumes of both structured and unstructured data for advanced analytics.

















































































