Downloaded 10 times





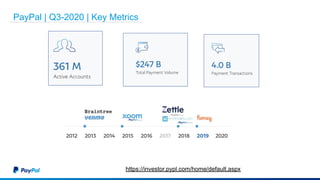
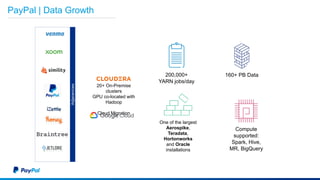
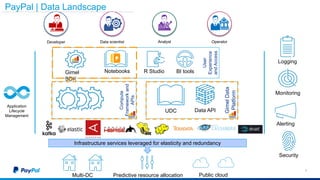


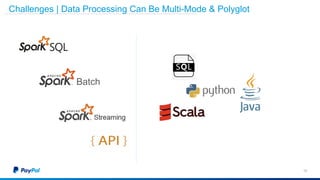
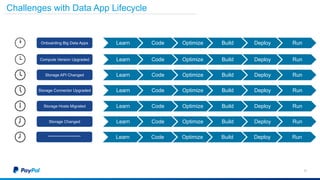

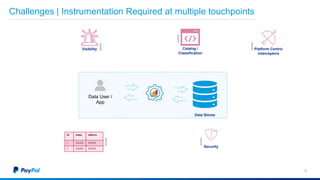
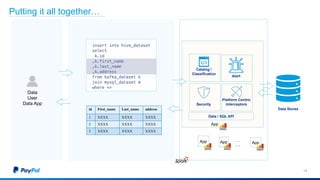
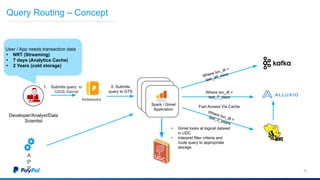


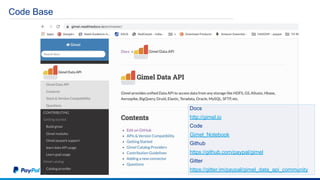









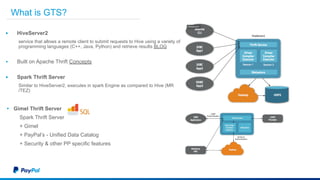
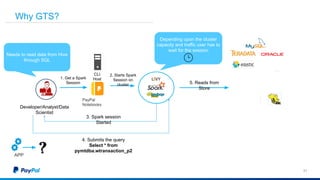
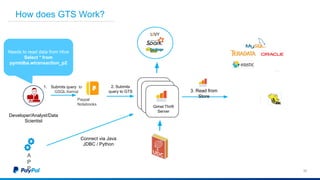

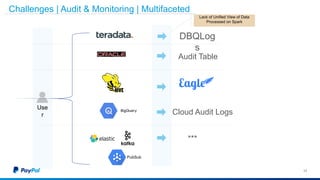
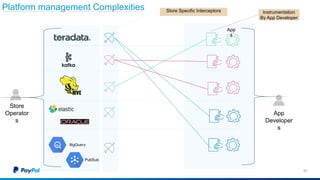
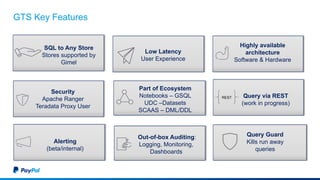

The document discusses Gimel, a big data framework developed by PayPal, which aims to streamline data access and simplify the data application lifecycle. It highlights the challenges faced in data processing and access, proposing solutions through a unified data API and catalog that can handle multiple storage backends. The document also outlines future enhancements for Gimel, including expanded cloud support and optimization strategies.























































































