Download as PDF, PPTX










![(2) we implement an object-oriented model used to represent natural text in
Smalltalk;
(3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
(4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
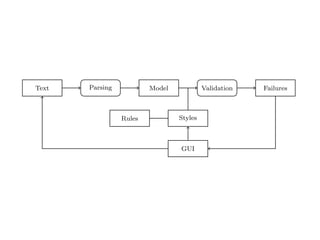
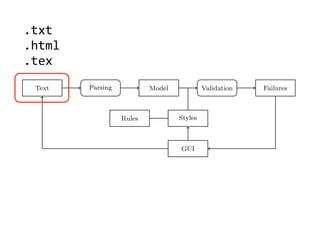
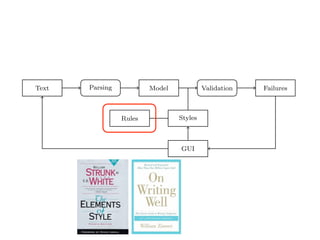
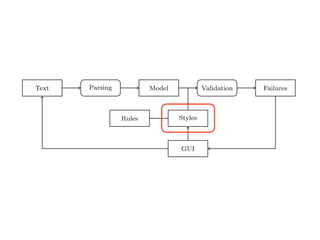
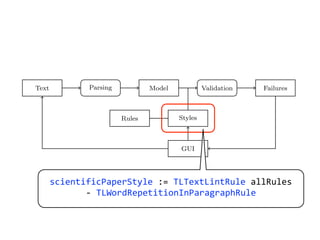
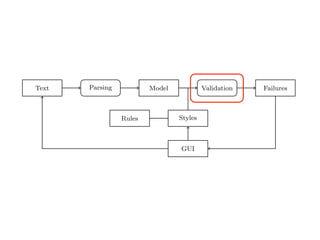
Text Parsing Model Validation Failures
Rules Styles
GUI
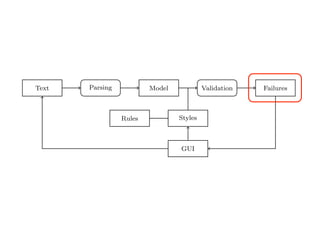
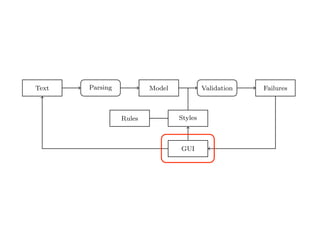
Fig. 2. Data Flow through TextLint.
Figure 2 gives an overview of the architecture of TextLint. Section 2 introduces
the natural text model of TextLint and Section 3 details how text documents
are parsed and the model is composed. Section 4 presents the rules which
model the stylistic checks. Section 5 describes how stylistic rules are defined in
· The Markup models LATEX or HTML commands depending on the filetype
of the input.
All document elements answer the message text which returns a plain string
representation of the modeled text entity ignoring markup tokens. Furthermore
all elements know their source interval in the document. The relationship among
the elements in the model are depicted in Figure 3.
Element
text()
interval()
Document Paragraph Sentence Phrase
1 * 1 * 1 *
SyntacticElement
text()
interval()
Word Punctuation Whitespace Markup
1
*
1
*
Fig. 3. The TextLint model and the relationships between its classes.
3 From Strings to Objects
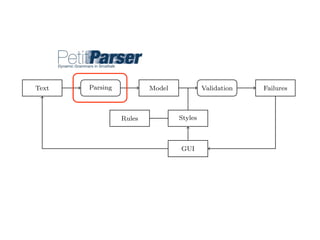
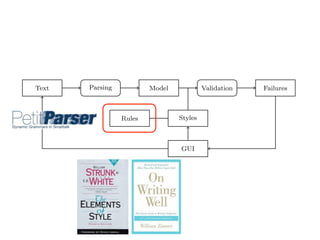
To build the high-level document model from the flat input string we use
PetitParser [7]. PetitParser is a framework targeted at parsing formal languages
(e.g., programming languages), but we employ it in this project to parse natural
4](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-18-320.jpg)
![raries: For parsing natural languages we use PetitParser [7], a flexible
rsing framework that makes it easy to define parsers and to dynamically
use, compose, transform and extend grammars. Furthermore, we use Glamour
, an engine for scripting browsers. Glamour reifies the notion of a browser
d defines the flow of data between different user interface widgets.
he contributions of this paper are:
1) we apply ideas from program checking to the domain of natural language;
2) we implement an object-oriented model used to represent natural text in
Smalltalk;
3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
Text Parsing Model Validation Failures
Rules Styles
GUI
representation of the modeled text entity ignoring markup tokens. Furthermore
all elements know their source interval in the document. The relationship among
the elements in the model are depicted in Figure 3.
Element
text()
interval()
Document Paragraph Sentence Phrase
1 * 1 * 1 *
SyntacticElement
text()
interval()
Word Punctuation Whitespace Markup
1
*
1
*
Fig. 3. The TextLint model and the relationships between its classes.](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-19-320.jpg)
![raries: For parsing natural languages we use PetitParser [7], a flexible
rsing framework that makes it easy to define parsers and to dynamically
use, compose, transform and extend grammars. Furthermore, we use Glamour
, an engine for scripting browsers. Glamour reifies the notion of a browser
d defines the flow of data between different user interface widgets.
he contributions of this paper are:
1) we apply ideas from program checking to the domain of natural language;
2) we implement an object-oriented model used to represent natural text in
Smalltalk;
3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
Text Parsing Model Validation Failures
Rules Styles
GUI
representation of the modeled text entity ignoring markup tokens. Furthermore
all elements know their source interval in the document. The relationship among
the elements in the model are depicted in Figure 3.
Element
text()
interval()
Document Paragraph Sentence Phrase
1 * 1 * 1 *
SyntacticElement
text()
interval()
Word Punctuation Whitespace Markup
1
*
1
*
Fig. 3. The TextLint model and the relationships between its classes.](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-20-320.jpg)
![raries: For parsing natural languages we use PetitParser [7], a flexible
rsing framework that makes it easy to define parsers and to dynamically
use, compose, transform and extend grammars. Furthermore, we use Glamour
, an engine for scripting browsers. Glamour reifies the notion of a browser
d defines the flow of data between different user interface widgets.
he contributions of this paper are:
1) we apply ideas from program checking to the domain of natural language;
2) we implement an object-oriented model used to represent natural text in
Smalltalk;
3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
Text Parsing Model Validation Failures
Rules Styles
GUI
representation of the modeled text entity ignoring markup tokens. Furthermore
all elements know their source interval in the document. The relationship among
the elements in the model are depicted in Figure 3.
Element
text()
interval()
Document Paragraph Sentence Phrase
1 * 1 * 1 *
SyntacticElement
text()
interval()
Word Punctuation Whitespace Markup
1
*
1
*
Fig. 3. The TextLint model and the relationships between its classes.](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-21-320.jpg)
![Other Language Models
raries: For parsing natural languages we use PetitParser [7], a flexible
rsing framework that makes it easy to define parsers and to dynamically
use, compose, transform and extend grammars. Furthermore, we use Glamour
, an engine for scripting browsers. Glamour reifies the notion of a browser
d defines the flow of data between different user interface widgets.
he contributions of this paper are:
1) we apply ideas from program checking to the domain of natural language;
2) we implement an object-oriented model used to represent natural text in
Smalltalk;
3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
Text Parsing Model Validation Failures
Rules Styles
GUI
representation of the modeled text entity ignoring markup tokens. Furthermore
all elements know their source interval in the document. The relationship among
the elements in the model are depicted in Figure 3.
Element
text()
interval()
Document Paragraph Sentence Phrase
1 * 1 * 1 *
SyntacticElement
text()
interval()
Word Punctuation Whitespace Markup
1
*
1
*
Fig. 3. The TextLint model and the relationships between its classes.](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-22-320.jpg)
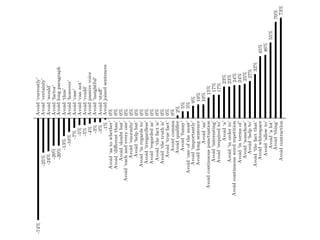
![Avoid "a lot"
Avoid "a"
Avoid "allow to"
Avoid "an"
Avoid "as to whether"
Avoid "can not"
Avoid "case"
Avoid "certainly"
Avoid "could"
Avoid "currently"
Avoid "different than"
Avoid "doubt but"
Avoid "each and every one"
Avoid "enormity"
Avoid "factor"
Avoid "funny"
Avoid "help but"
Avoid "help to"
Avoid "however"
Avoid "importantly"
Avoid "in order to"
Avoid "in regards to"
Avoid "in terms of"
Avoid "insightful"
Avoid "interesting"
Avoid "irregardless"
Avoid "one of the most"
Avoid "regarded as"
Avoid "required to"
Avoid "somehow"
Avoid "stuff"
Avoid "the fact is"
Avoid "the fact that"
Avoid "the truth is"
Avoid "thing"
Avoid "thus"
Avoid "true fact"
Avoid "would"
Avoid comma
Avoid connectors repetition
Avoid continuous punctuation
Avoid continuous word repetition
Avoid contraction
Avoid joined sentences
Avoid long paragraph
Avoid long sentence
Avoid passive voice
Avoid qualifier
Avoid whitespace
Avoid word repetition
raries: For parsing natural languages we use PetitParser [7], a flexible
rsing framework that makes it easy to define parsers and to dynamically
use, compose, transform and extend grammars. Furthermore, we use Glamour
, an engine for scripting browsers. Glamour reifies the notion of a browser
d defines the flow of data between different user interface widgets.
he contributions of this paper are:
1) we apply ideas from program checking to the domain of natural language;
2) we implement an object-oriented model used to represent natural text in
Smalltalk;
3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
Text Parsing Model Validation Failures
Rules Styles
GUI](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-25-320.jpg)
![Avoid "a lot"
Avoid "a"
Avoid "allow to"
Avoid "an"
Avoid "as to whether"
Avoid "can not"
Avoid "case"
Avoid "certainly"
Avoid "could"
Avoid "currently"
Avoid "different than"
Avoid "doubt but"
Avoid "each and every one"
Avoid "enormity"
Avoid "factor"
Avoid "funny"
Avoid "help but"
Avoid "help to"
Avoid "however"
Avoid "importantly"
Avoid "in order to"
Avoid "in regards to"
Avoid "in terms of"
Avoid "insightful"
Avoid "interesting"
Avoid "irregardless"
Avoid "one of the most"
Avoid "regarded as"
Avoid "required to"
Avoid "somehow"
Avoid "stuff"
Avoid "the fact is"
Avoid "the fact that"
Avoid "the truth is"
Avoid "thing"
Avoid "thus"
Avoid "true fact"
Avoid "would"
Avoid comma
Avoid connectors repetition
Avoid continuous punctuation
Avoid continuous word repetition
Avoid contraction
Avoid joined sentences
Avoid long paragraph
Avoid long sentence
Avoid passive voice
Avoid qualifier
Avoid whitespace
Avoid word repetition
raries: For parsing natural languages we use PetitParser [7], a flexible
rsing framework that makes it easy to define parsers and to dynamically
use, compose, transform and extend grammars. Furthermore, we use Glamour
, an engine for scripting browsers. Glamour reifies the notion of a browser
d defines the flow of data between different user interface widgets.
he contributions of this paper are:
1) we apply ideas from program checking to the domain of natural language;
2) we implement an object-oriented model used to represent natural text in
Smalltalk;
3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
Text Parsing Model Validation Failures
Rules Styles
GUI
(self
word:
‘somehow’)](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-26-320.jpg)
![Avoid "a lot"
Avoid "a"
Avoid "allow to"
Avoid "an"
Avoid "as to whether"
Avoid "can not"
Avoid "case"
Avoid "certainly"
Avoid "could"
Avoid "currently"
Avoid "different than"
Avoid "doubt but"
Avoid "each and every one"
Avoid "enormity"
Avoid "factor"
Avoid "funny"
Avoid "help but"
Avoid "help to"
Avoid "however"
Avoid "importantly"
Avoid "in order to"
Avoid "in regards to"
Avoid "in terms of"
Avoid "insightful"
Avoid "interesting"
Avoid "irregardless"
Avoid "one of the most"
Avoid "regarded as"
Avoid "required to"
Avoid "somehow"
Avoid "stuff"
Avoid "the fact is"
Avoid "the fact that"
Avoid "the truth is"
Avoid "thing"
Avoid "thus"
Avoid "true fact"
Avoid "would"
Avoid comma
Avoid connectors repetition
Avoid continuous punctuation
Avoid continuous word repetition
Avoid contraction
Avoid joined sentences
Avoid long paragraph
Avoid long sentence
Avoid passive voice
Avoid qualifier
Avoid whitespace
Avoid word repetition
raries: For parsing natural languages we use PetitParser [7], a flexible
rsing framework that makes it easy to define parsers and to dynamically
use, compose, transform and extend grammars. Furthermore, we use Glamour
, an engine for scripting browsers. Glamour reifies the notion of a browser
d defines the flow of data between different user interface widgets.
he contributions of this paper are:
1) we apply ideas from program checking to the domain of natural language;
2) we implement an object-oriented model used to represent natural text in
Smalltalk;
3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
Text Parsing Model Validation Failures
Rules Styles
GUI
(self
punctuation)
,
(self
punctuation)](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-27-320.jpg)
![Avoid "a lot"
Avoid "a"
Avoid "allow to"
Avoid "an"
Avoid "as to whether"
Avoid "can not"
Avoid "case"
Avoid "certainly"
Avoid "could"
Avoid "currently"
Avoid "different than"
Avoid "doubt but"
Avoid "each and every one"
Avoid "enormity"
Avoid "factor"
Avoid "funny"
Avoid "help but"
Avoid "help to"
Avoid "however"
Avoid "importantly"
Avoid "in order to"
Avoid "in regards to"
Avoid "in terms of"
Avoid "insightful"
Avoid "interesting"
Avoid "irregardless"
Avoid "one of the most"
Avoid "regarded as"
Avoid "required to"
Avoid "somehow"
Avoid "stuff"
Avoid "the fact is"
Avoid "the fact that"
Avoid "the truth is"
Avoid "thing"
Avoid "thus"
Avoid "true fact"
Avoid "would"
Avoid comma
Avoid connectors repetition
Avoid continuous punctuation
Avoid continuous word repetition
Avoid contraction
Avoid joined sentences
Avoid long paragraph
Avoid long sentence
Avoid passive voice
Avoid qualifier
Avoid whitespace
Avoid word repetition
raries: For parsing natural languages we use PetitParser [7], a flexible
rsing framework that makes it easy to define parsers and to dynamically
use, compose, transform and extend grammars. Furthermore, we use Glamour
, an engine for scripting browsers. Glamour reifies the notion of a browser
d defines the flow of data between different user interface widgets.
he contributions of this paper are:
1) we apply ideas from program checking to the domain of natural language;
2) we implement an object-oriented model used to represent natural text in
Smalltalk;
3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
Text Parsing Model Validation Failures
Rules Styles
GUI
(self
wordIn:
#('am'
'are'
'were'
'being'
...
))
,
(self
separator
star)
,
((self
wordSatisfying:
[
:value
|
value
endsWith:
'ed'
])
/
(self
wordIn:
#('awoken'
'been'
'born'
'beat'
...
)))](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-28-320.jpg)
![raries: For parsing natural languages we use PetitParser [7], a flexible
rsing framework that makes it easy to define parsers and to dynamically
use, compose, transform and extend grammars. Furthermore, we use Glamour
, an engine for scripting browsers. Glamour reifies the notion of a browser
d defines the flow of data between different user interface widgets.
he contributions of this paper are:
1) we apply ideas from program checking to the domain of natural language;
2) we implement an object-oriented model used to represent natural text in
Smalltalk;
3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
Text Parsing Model Validation Failures
Rules Styles
GUI](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-34-320.jpg)
![raries: For parsing natural languages we use PetitParser [7], a flexible
rsing framework that makes it easy to define parsers and to dynamically
use, compose, transform and extend grammars. Furthermore, we use Glamour
, an engine for scripting browsers. Glamour reifies the notion of a browser
d defines the flow of data between different user interface widgets.
he contributions of this paper are:
1) we apply ideas from program checking to the domain of natural language;
2) we implement an object-oriented model used to represent natural text in
Smalltalk;
3) we demonstrate a pattern matcher for the detection of style issues in
natural language; and
4) we demonstrate a graphical user interface that presents and explains the
problems detected by the tool.
Text Parsing Model Validation Failures
Rules Styles
GUI](https://image.slidesharecdn.com/textlint-101112140815-phpapp02/85/Natural-Language-Checking-with-Program-Checking-Tools-35-320.jpg)





The document presents a framework called Textlint, which implements an object-oriented model for representing natural text in Smalltalk and demonstrates a pattern matcher for detecting style issues in language. It details the architecture of Textlint, including text parsing, stylistic rule modeling, and the graphical user interface that explains detected issues. Key contributions include applying program checking ideas to natural language processing and providing a dynamic parsing framework using PetitParser.


















































































