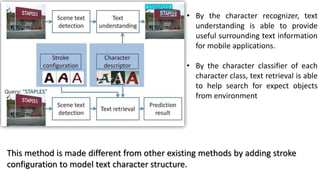
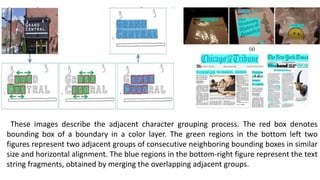
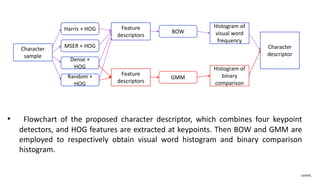
The document presents a method for scene text detection and recognition aimed at extracting text from natural scenes despite diverse backgrounds and fonts. It details a two-step process of text detection and recognition, employing character descriptors and stroke configuration maps to enhance accuracy. The method, designed for mobile applications, utilizes color decomposition and boundary clustering algorithms for text detection and involves character classification for effective text retrieval.