Downloaded 32 times

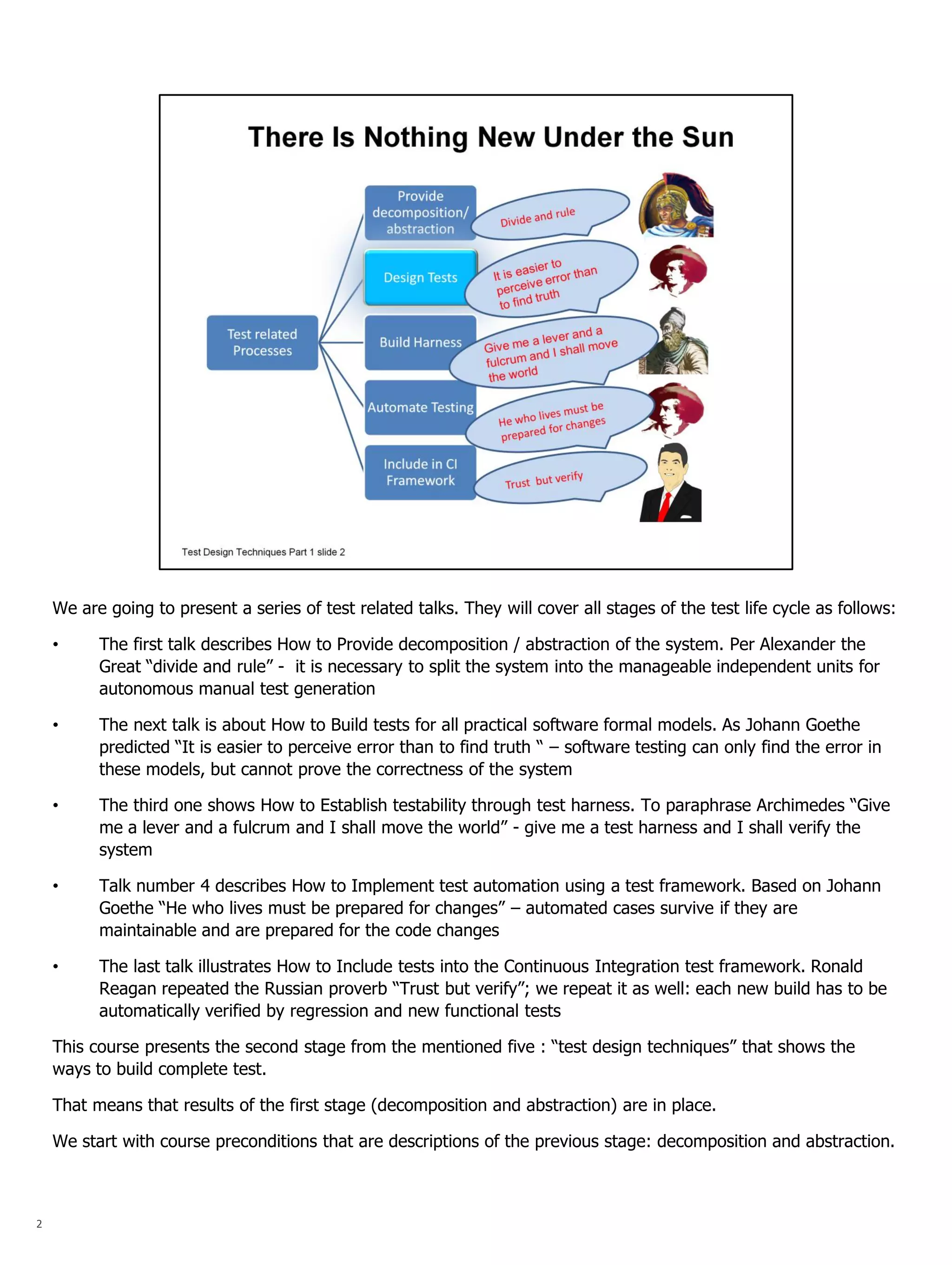










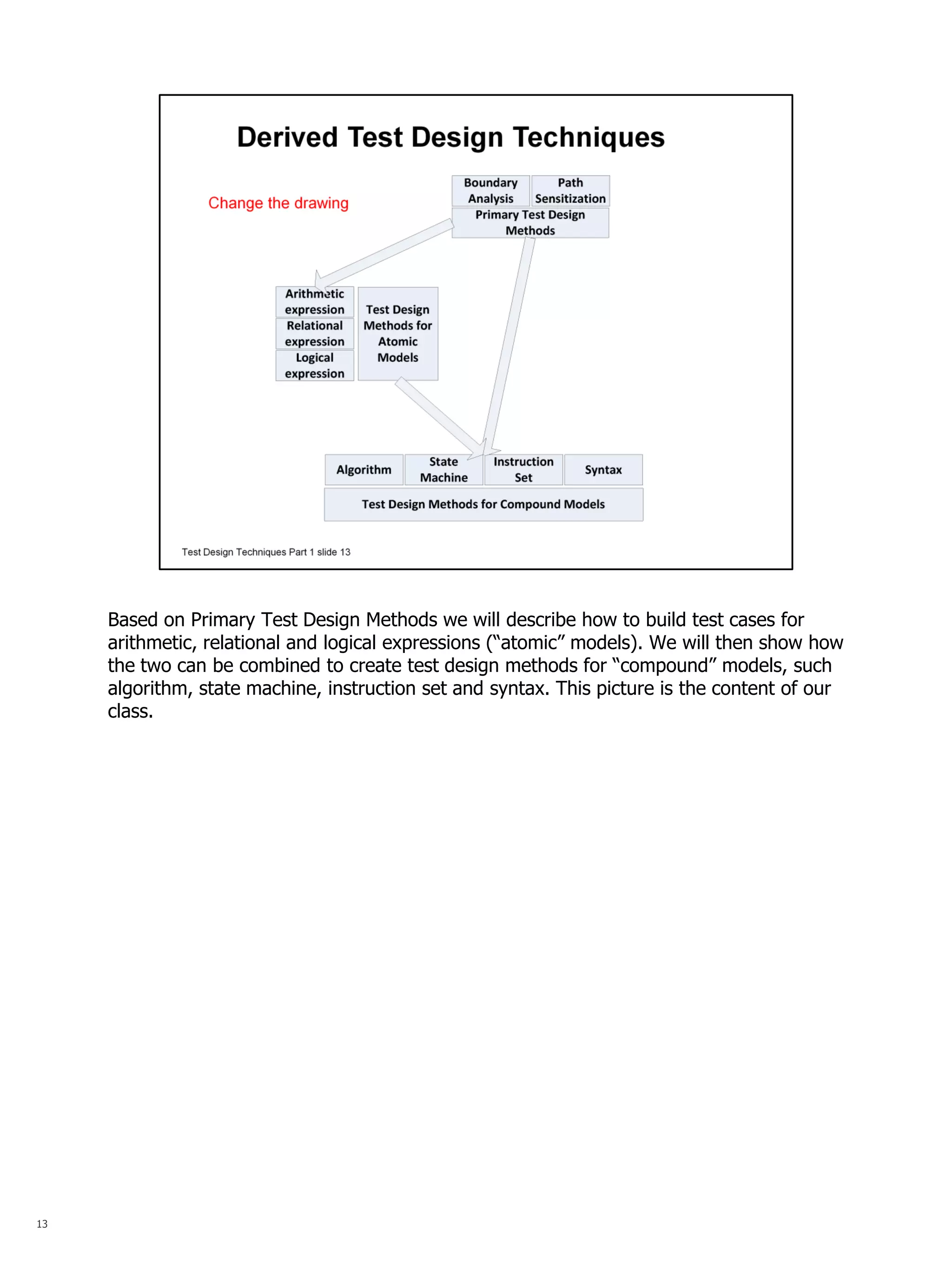










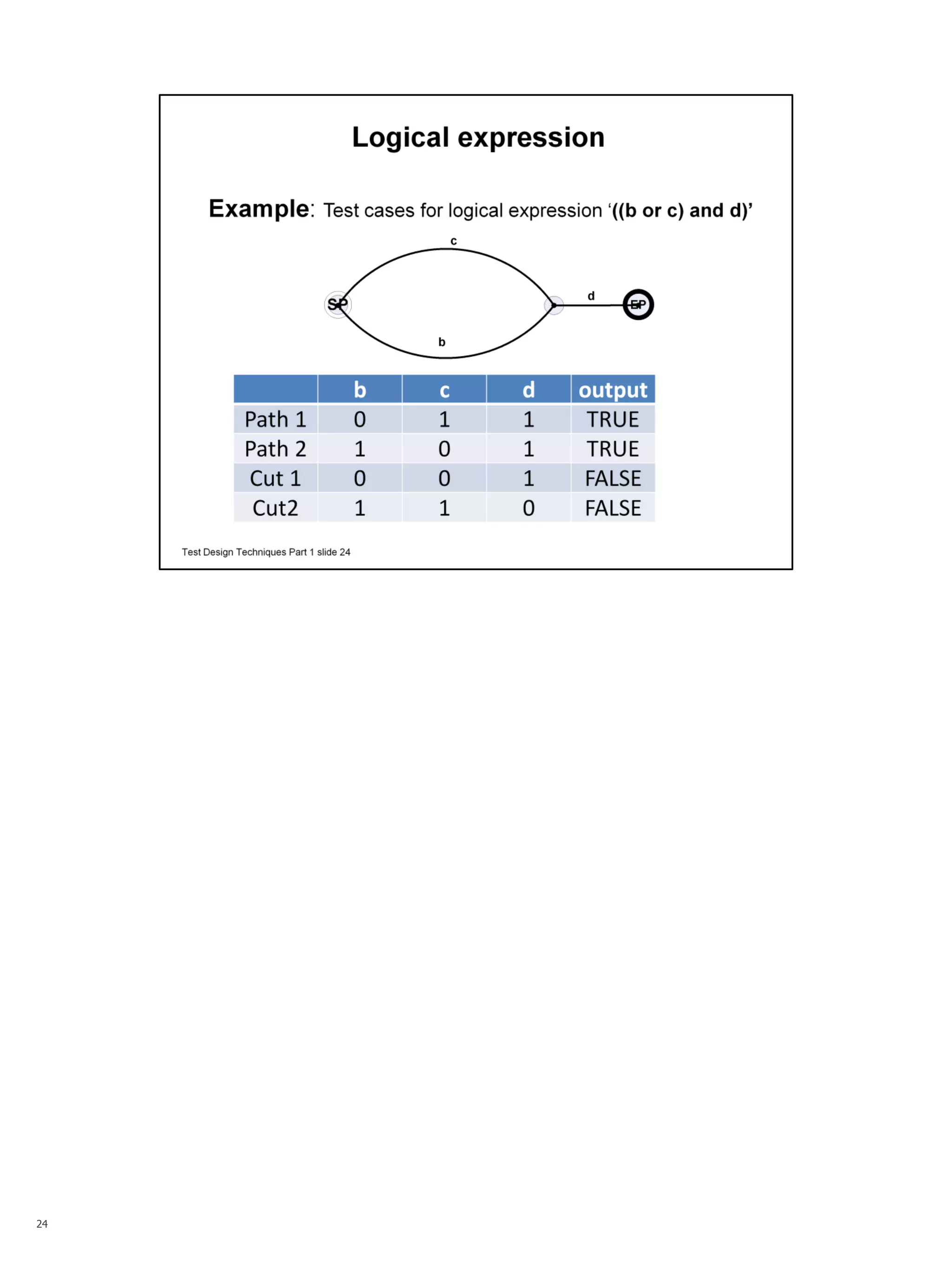

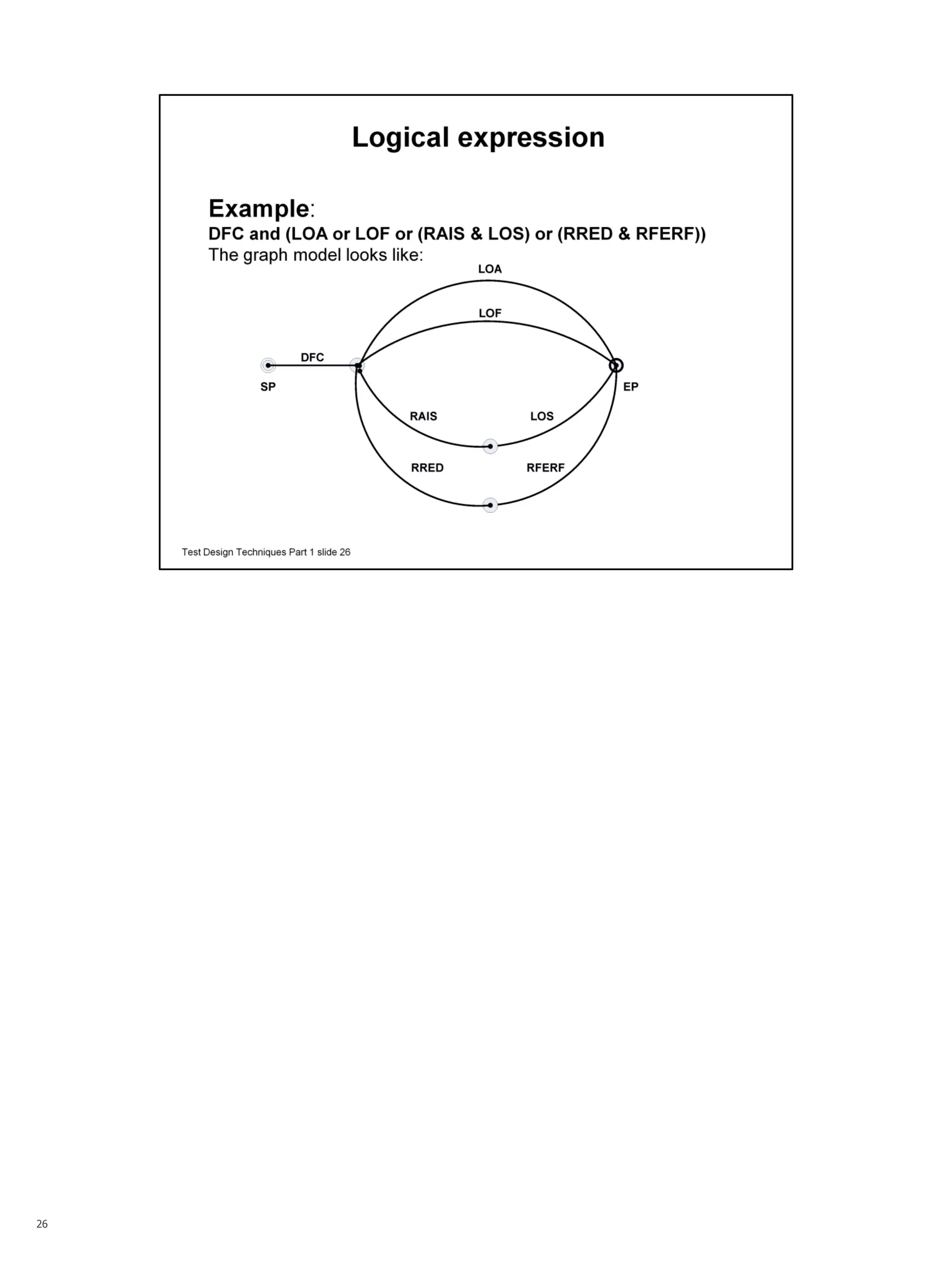






















The document summarizes a series of talks on software testing. The talks will cover the different stages of the test life cycle, including: decomposing the system into independent units; building tests for formal models; establishing testability through test harnesses; automating tests using frameworks; and including tests in continuous integration. The document then provides more details about the second talk on building tests for formal models and describes the use of formal models in test design techniques.






















































































