Downloaded 19 times


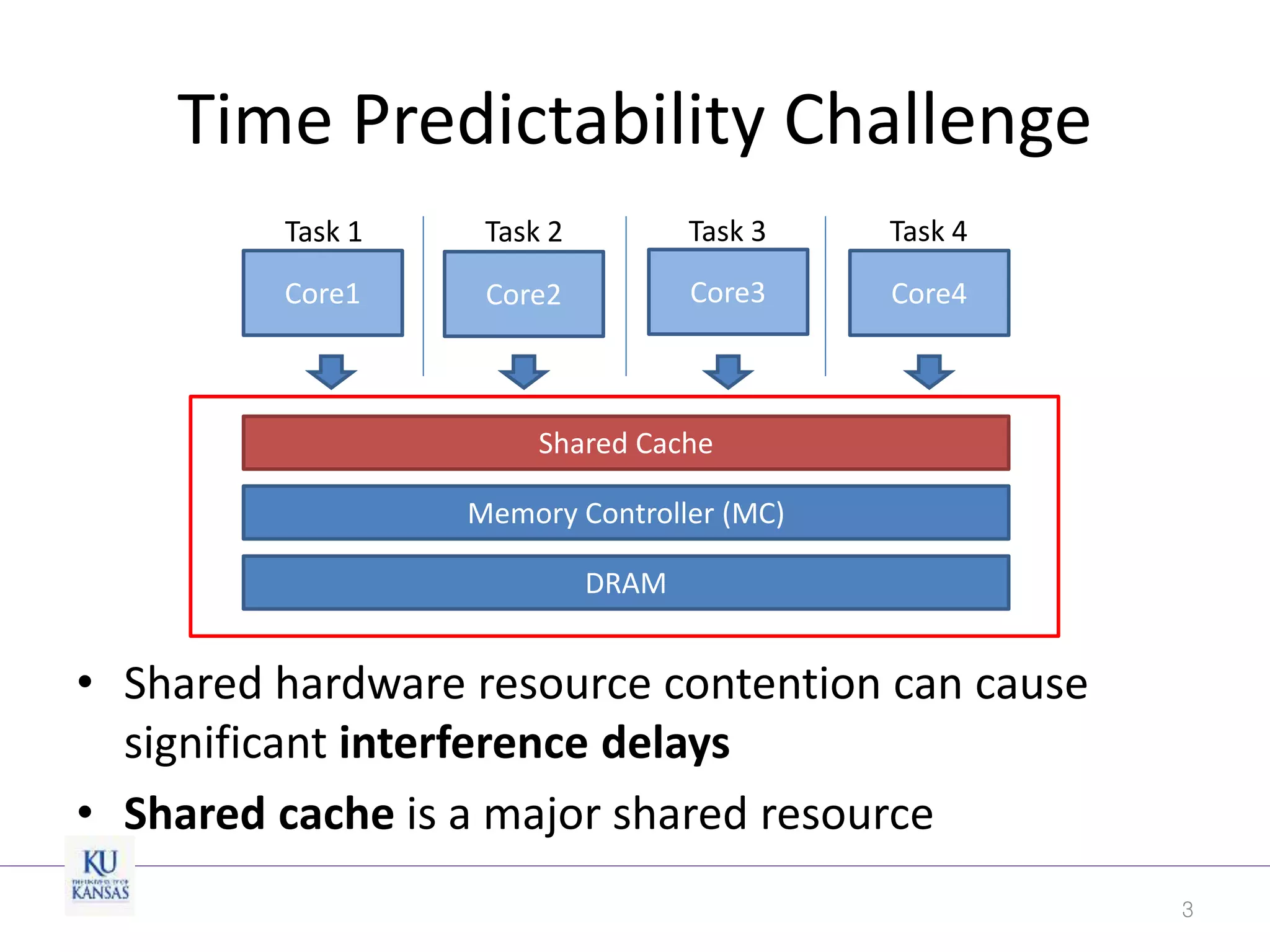



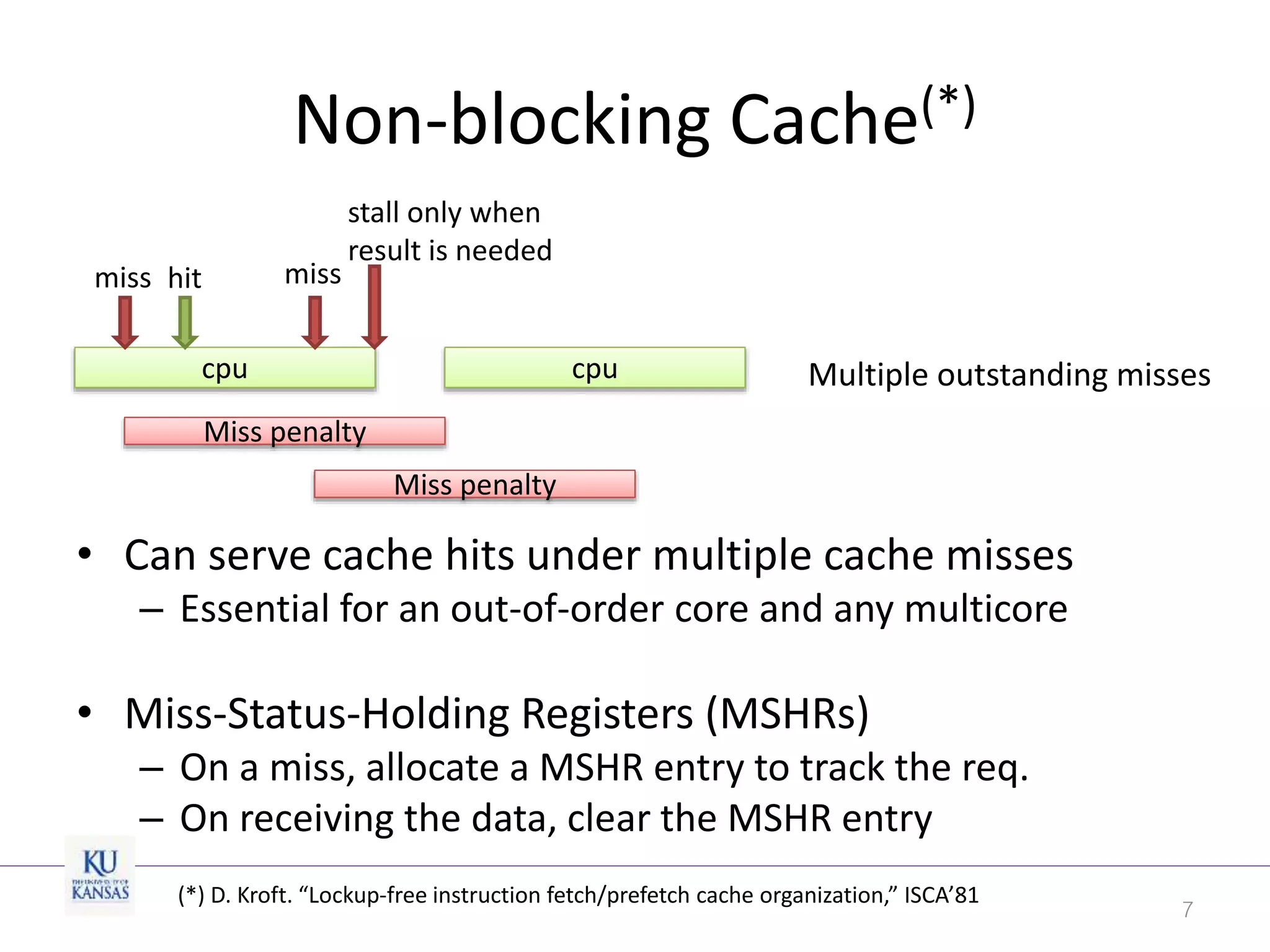



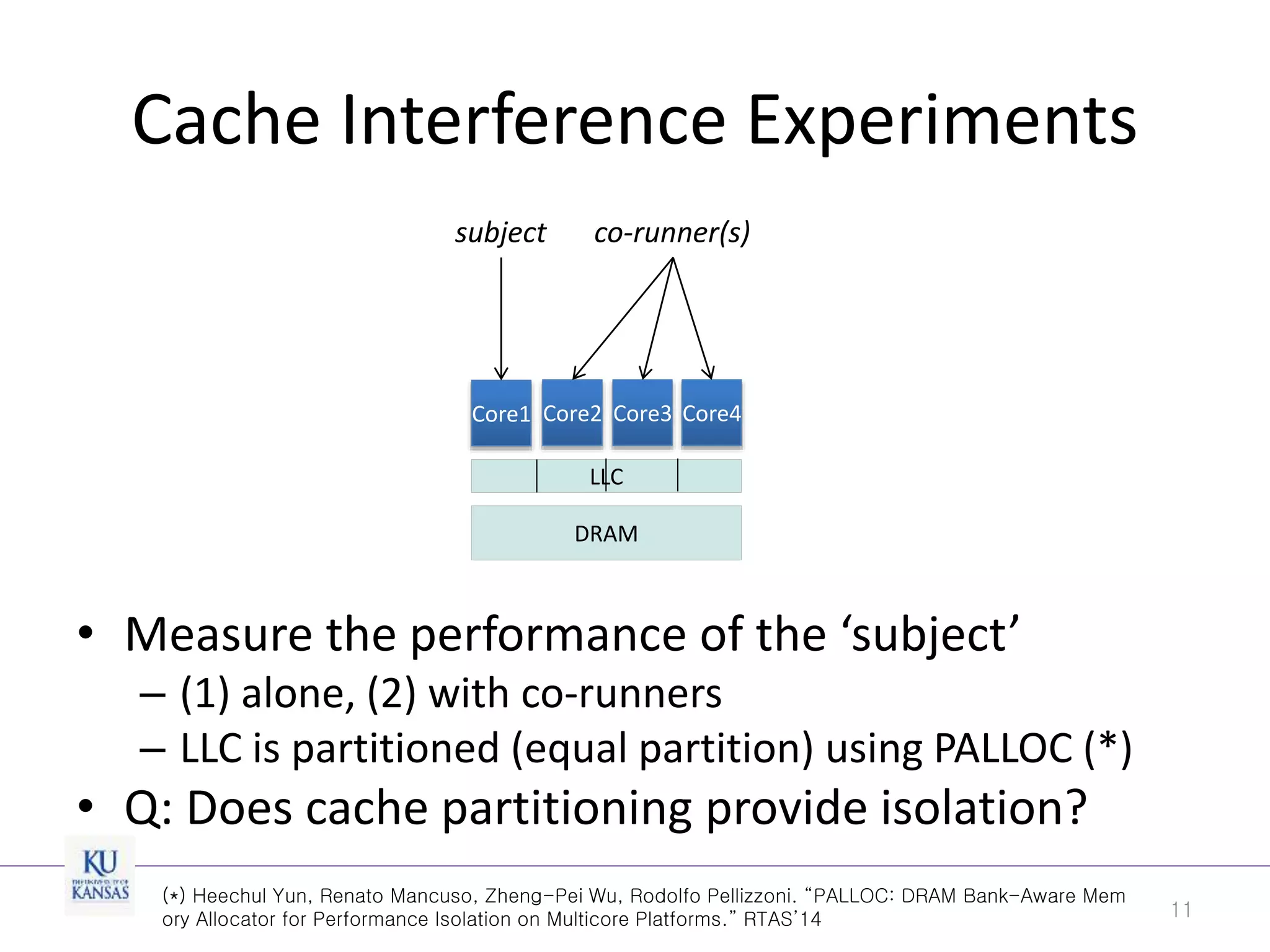

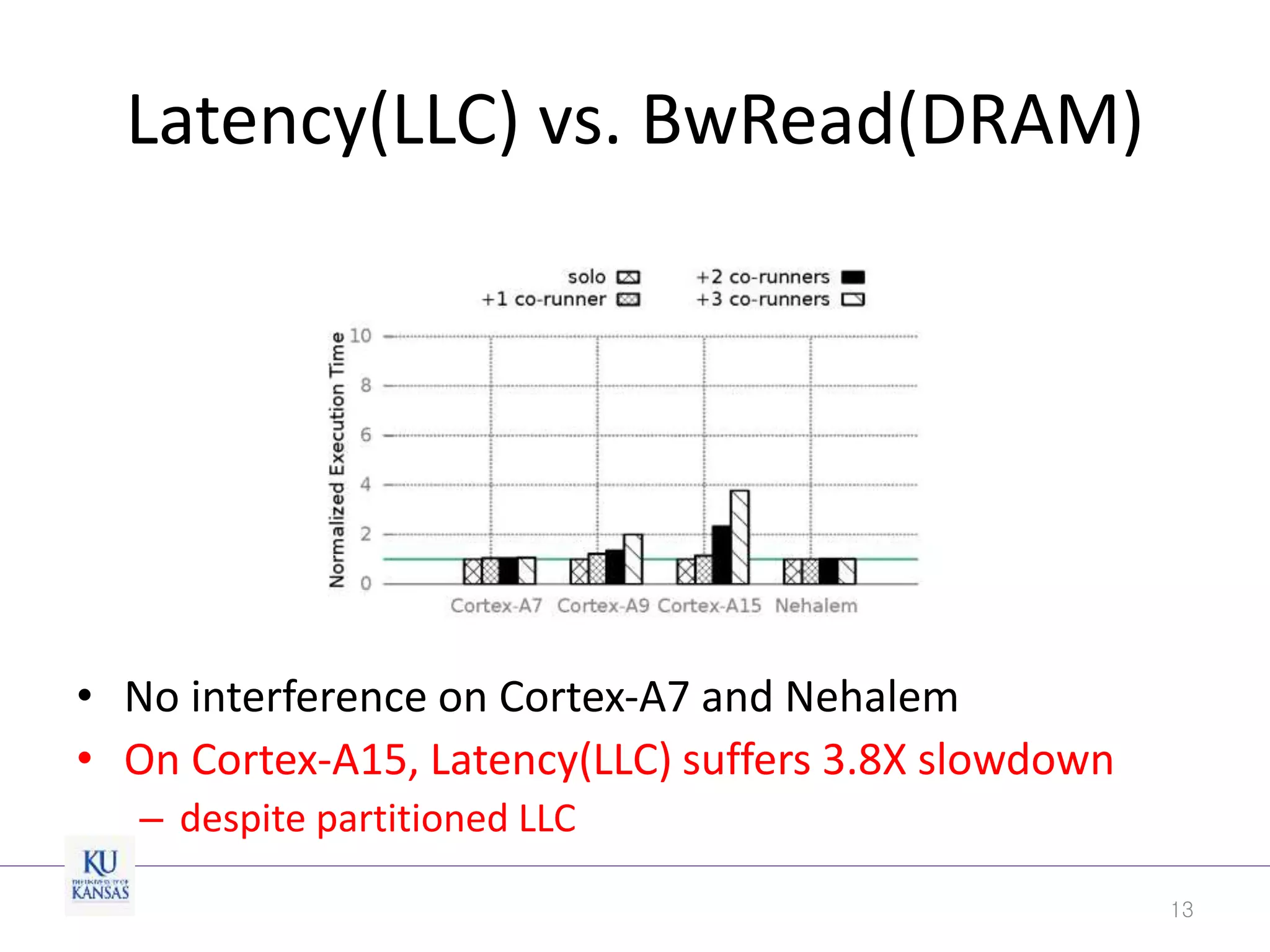
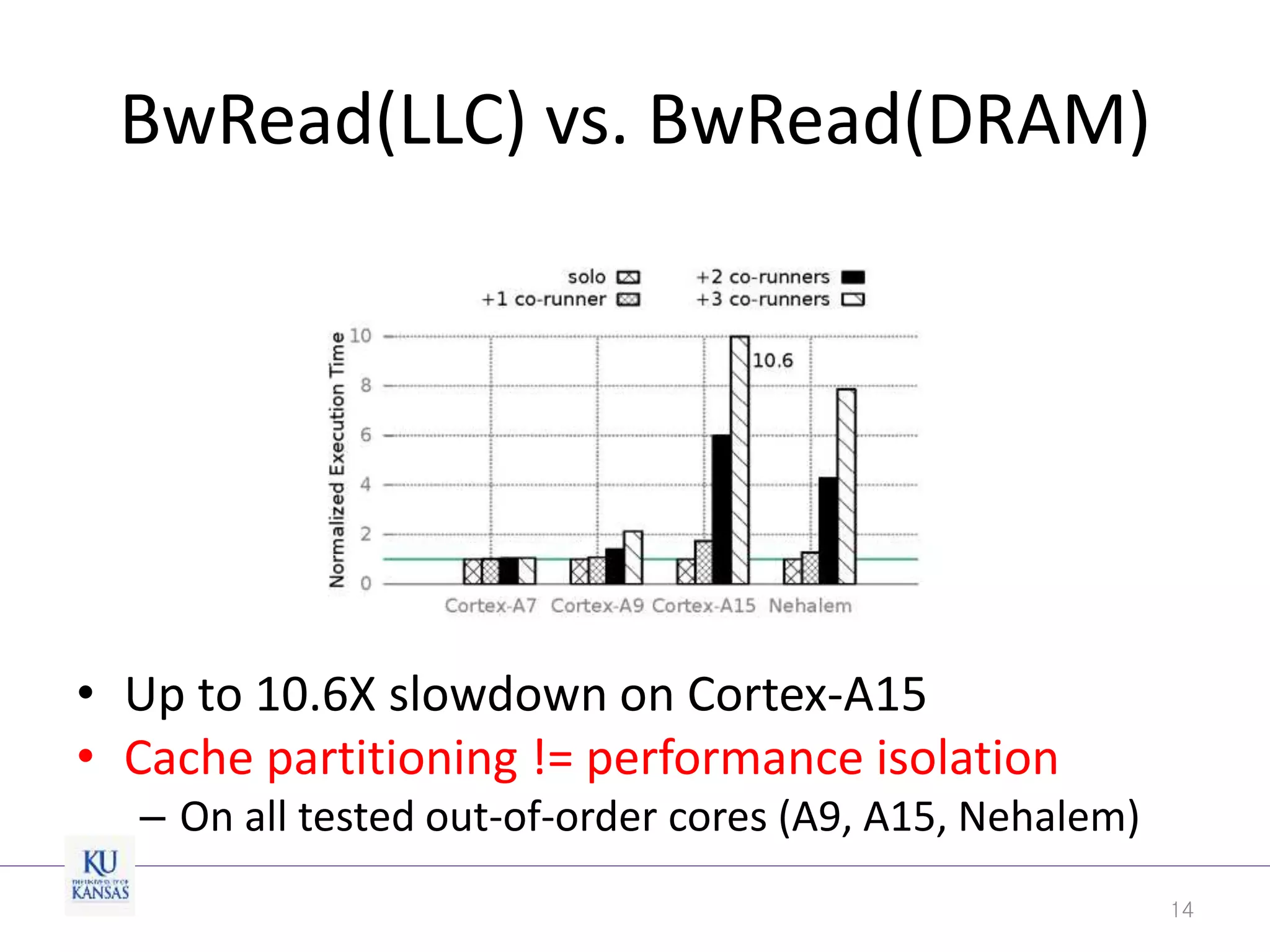
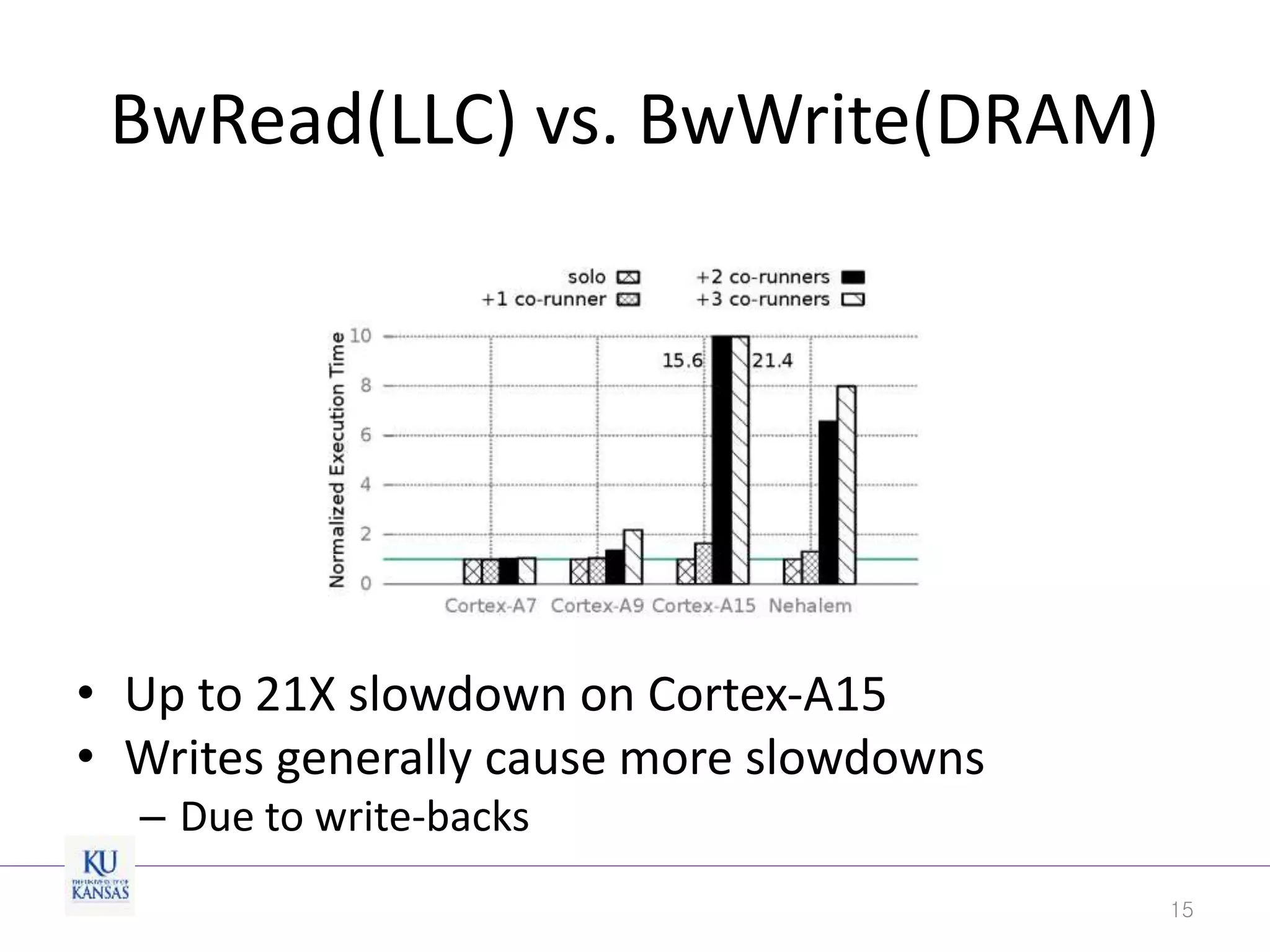
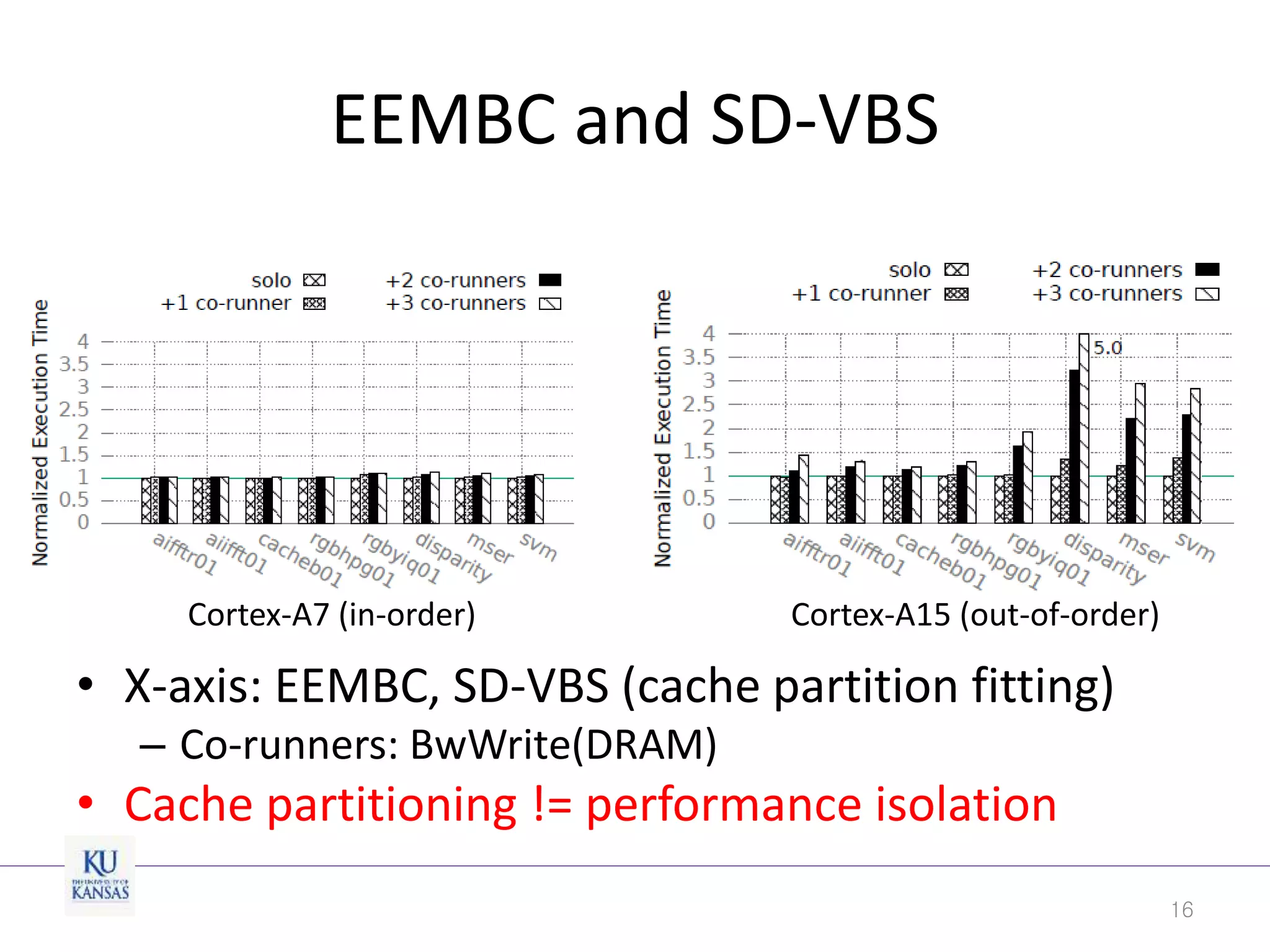


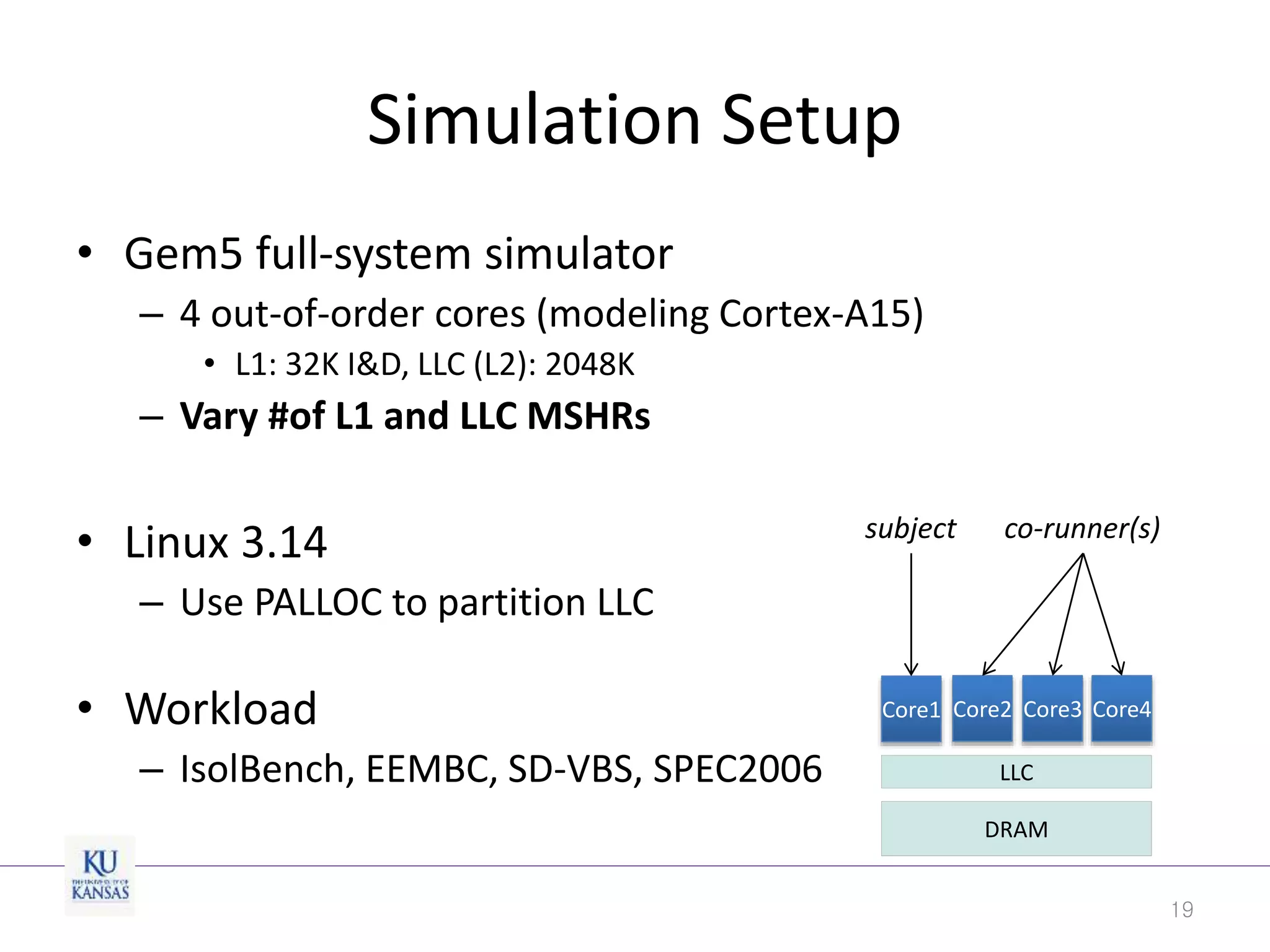
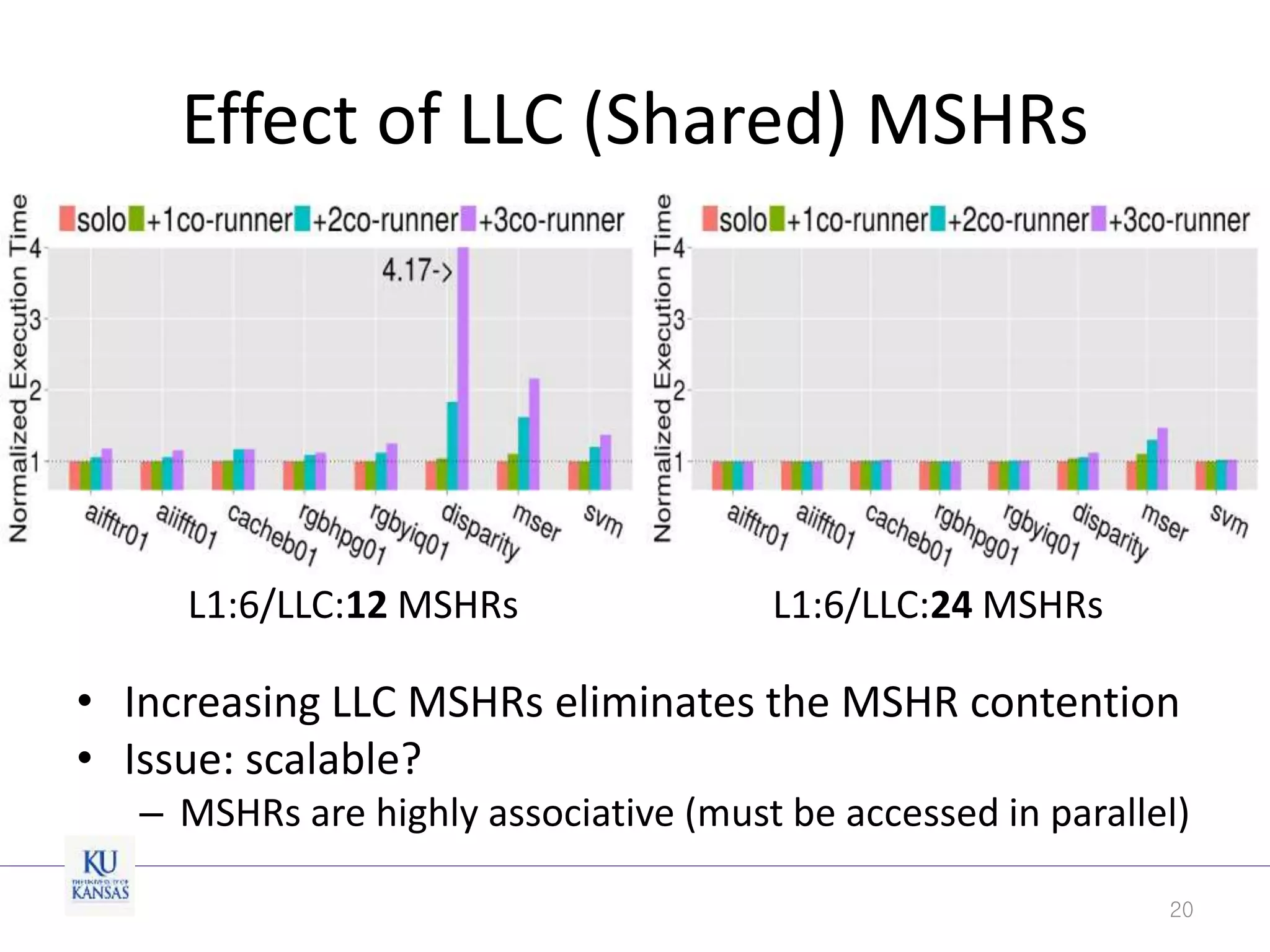
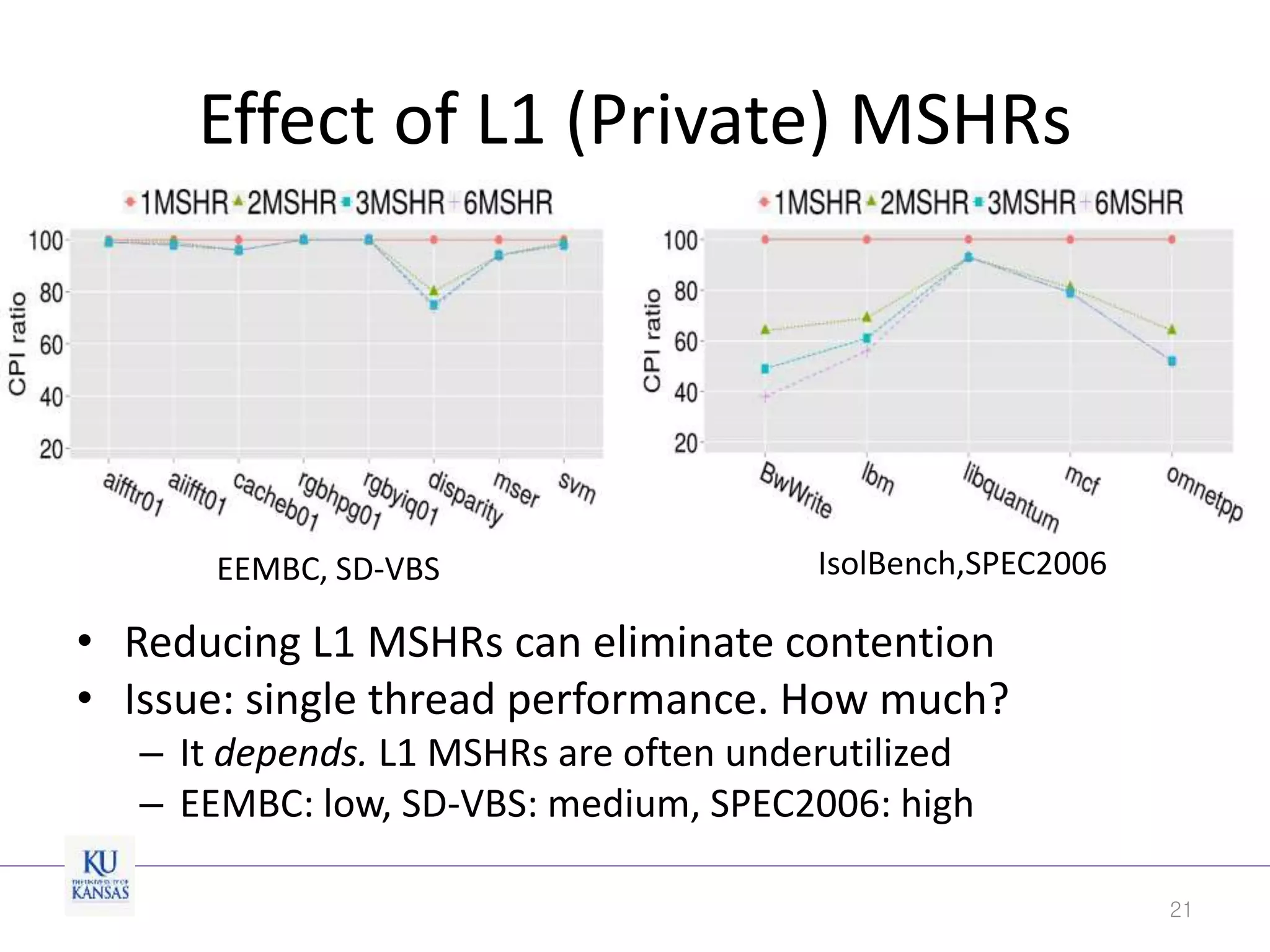
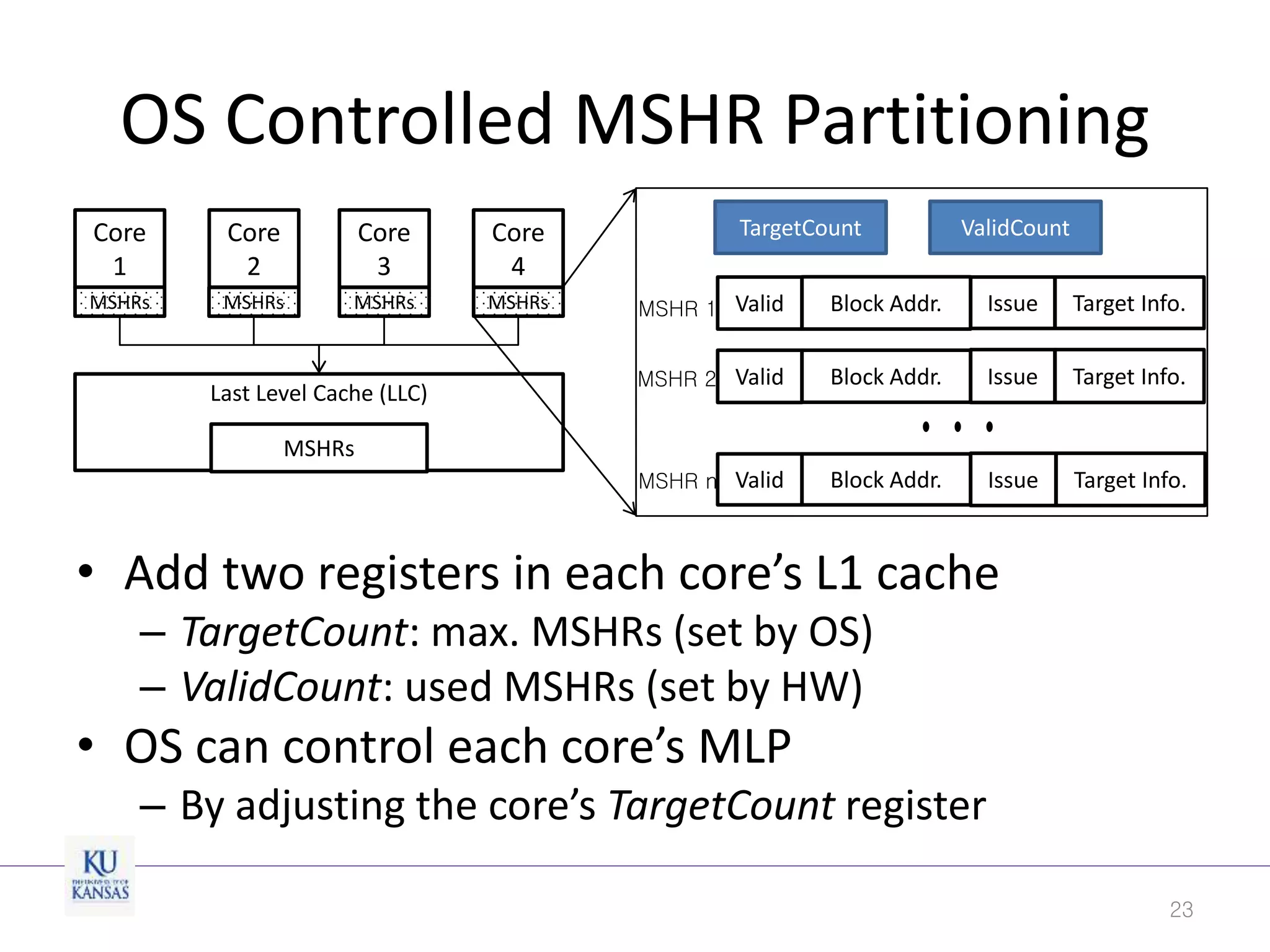

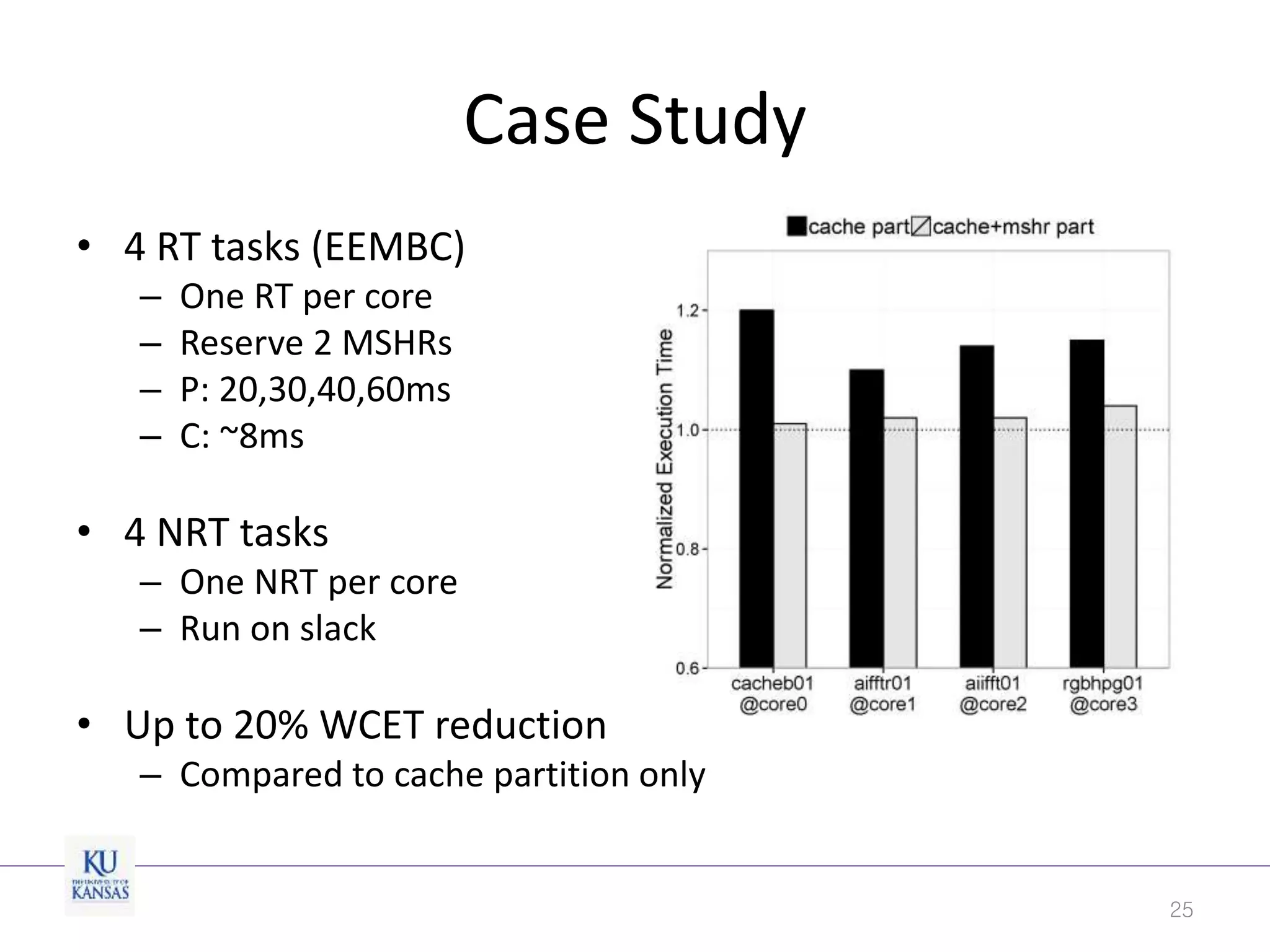

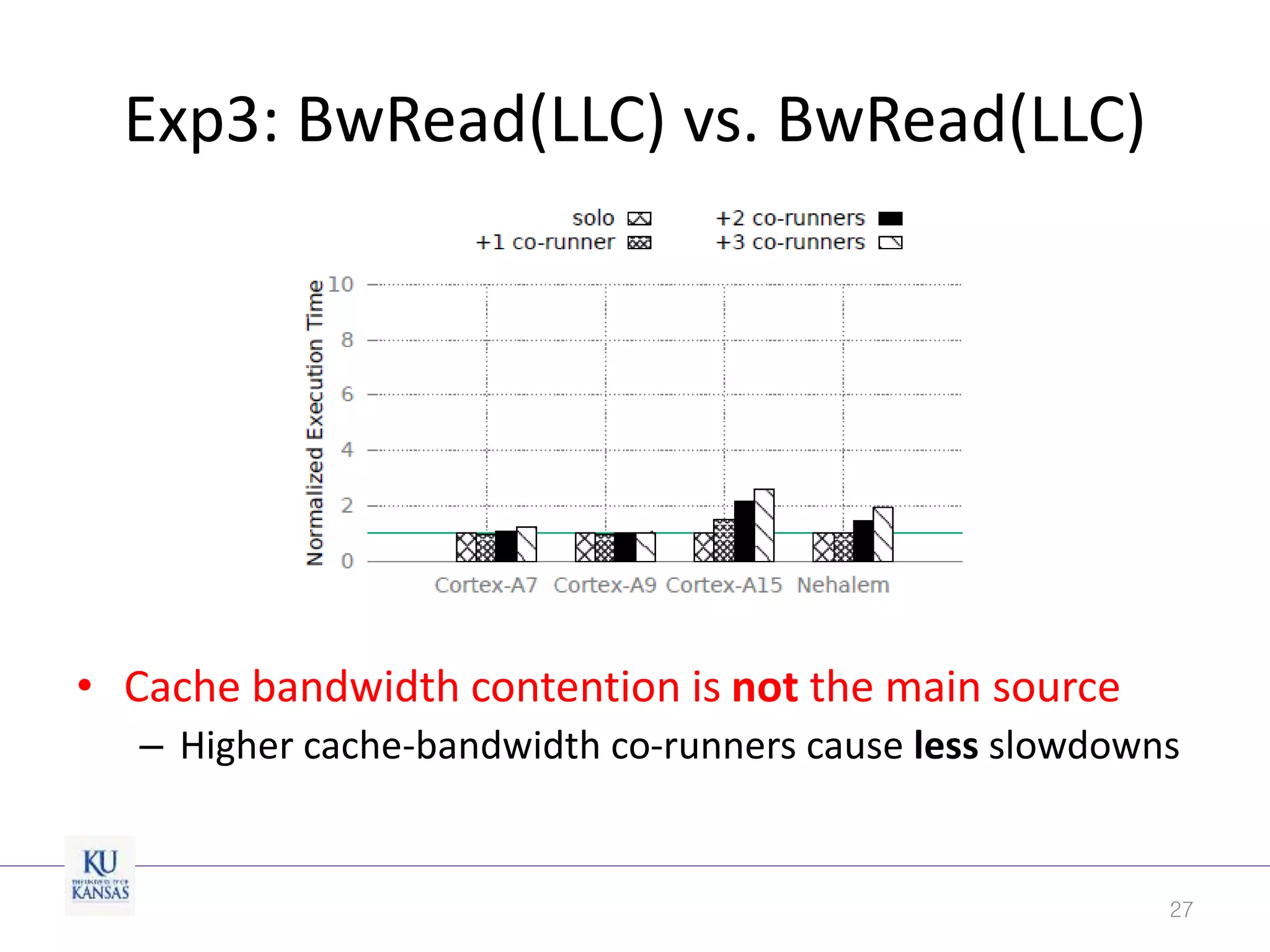
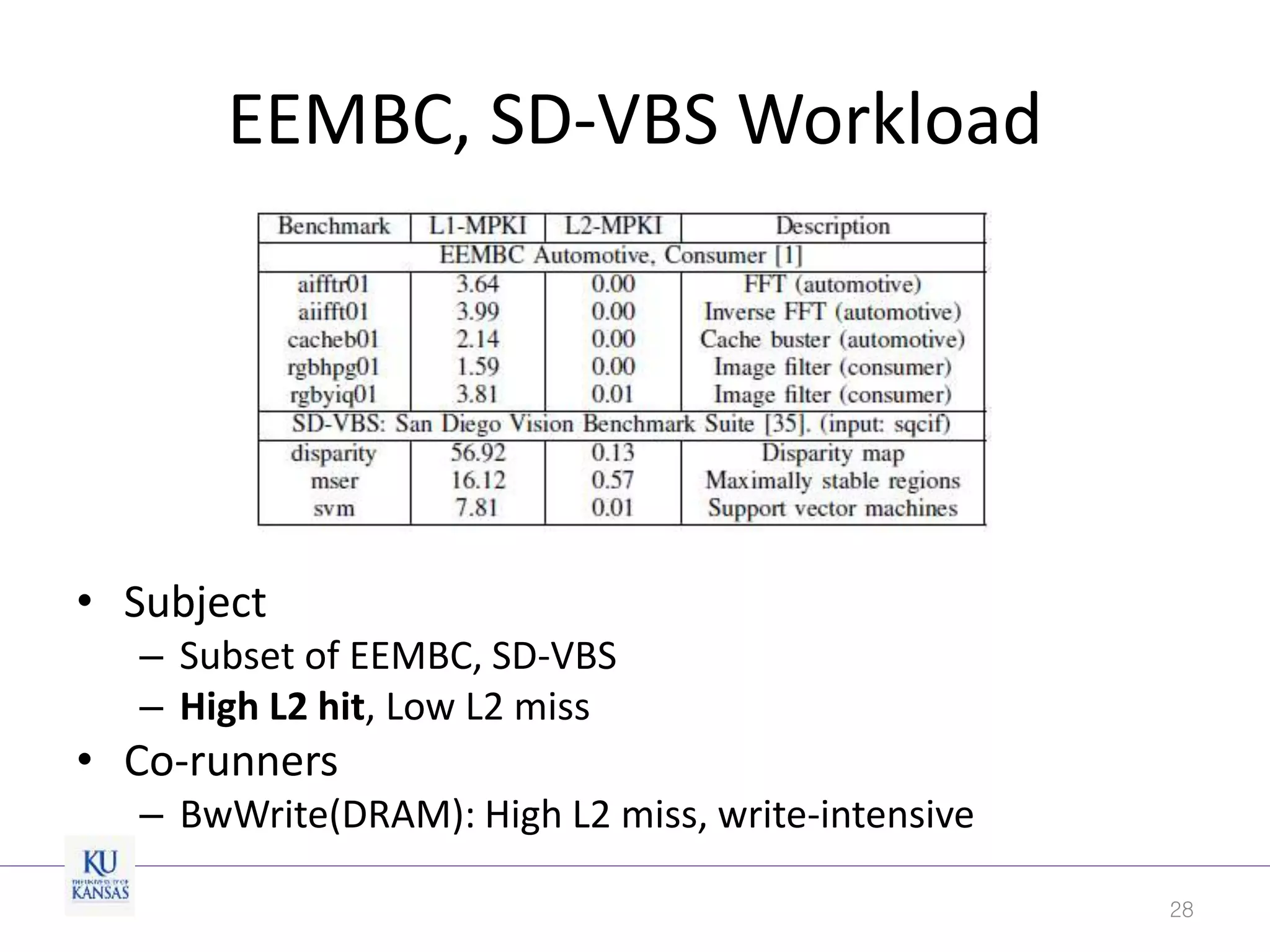

This document discusses the limitations of cache partitioning for performance isolation in multicore real-time systems, revealing that contention for miss-status-holding registers can negate the benefits of partitioning. Through experiments on various multicore architectures, it was found that cache partitioning does not ensure performance isolation under several conditions, particularly in out-of-order cores. The authors propose an OS/architecture collaborative solution to enhance cache performance isolation by managing MSHR resources more effectively.











































![An Overview of [Linux] Kernel Lock Improvements -- Linuxcon NA 2014](https://cdn.slidesharecdn.com/ss_thumbnails/linuxcon-2014-locking-final-140826225054-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)























