Download to read offline


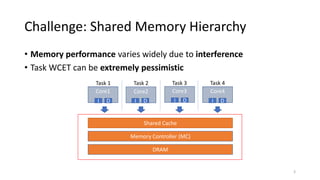





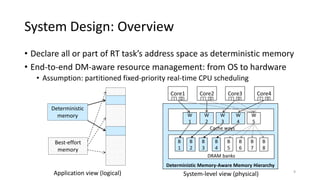
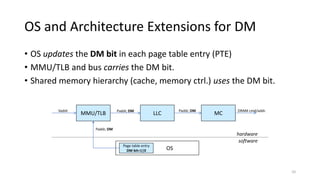










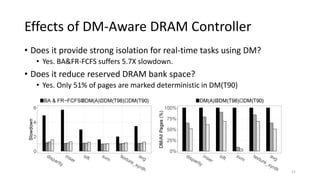




The document discusses a new deterministic memory abstraction for multicore systems, aimed at improving performance and predictability in real-time applications. It addresses challenges related to shared memory hierarchies and aims to provide bounded worst-case timing for memory operations, allowing for optimized resource management strategies. The proposed approach is implemented in Linux and evaluated through simulation, demonstrating significant improvements in cache isolation and space utilization.









































































