


































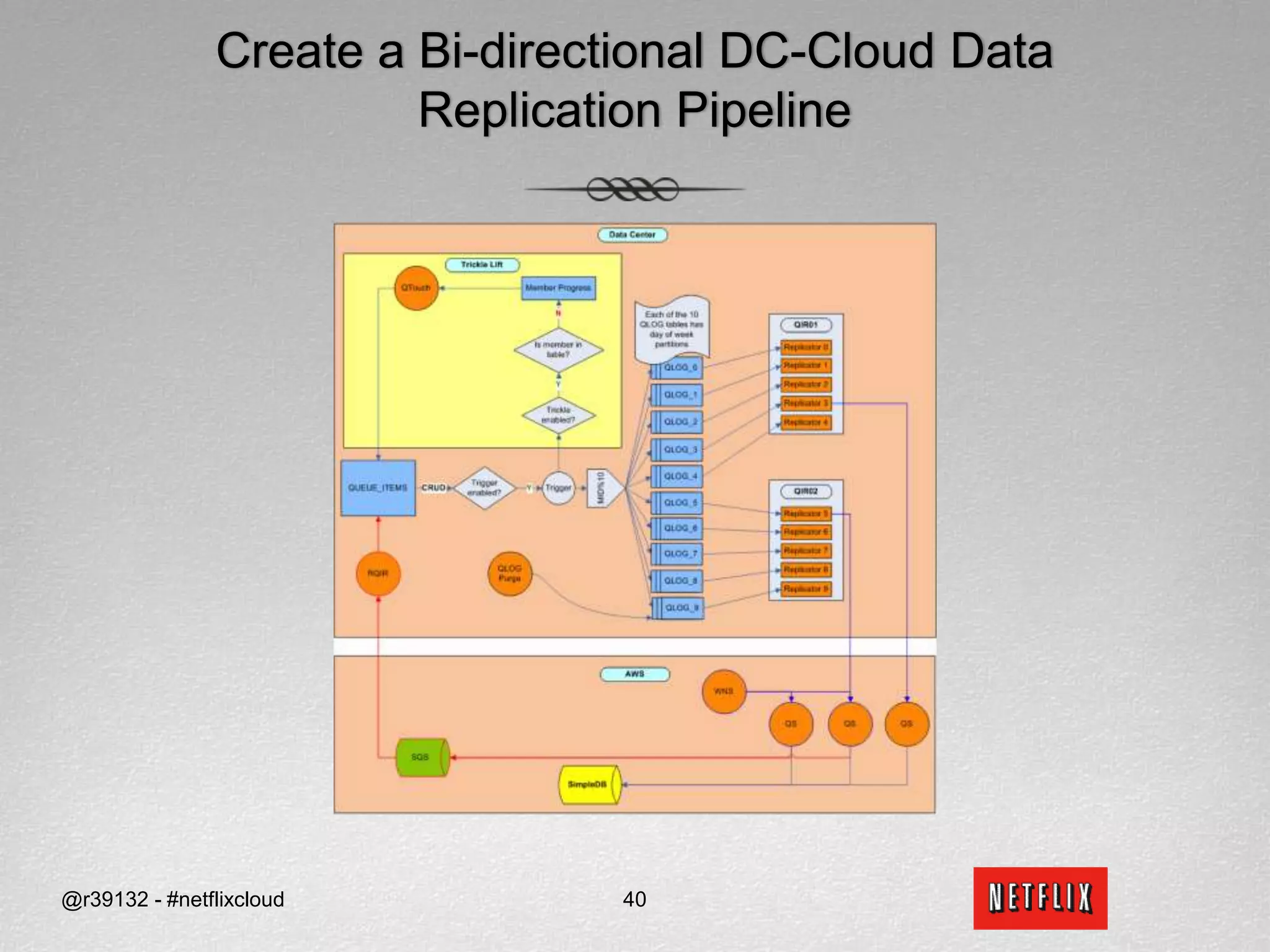





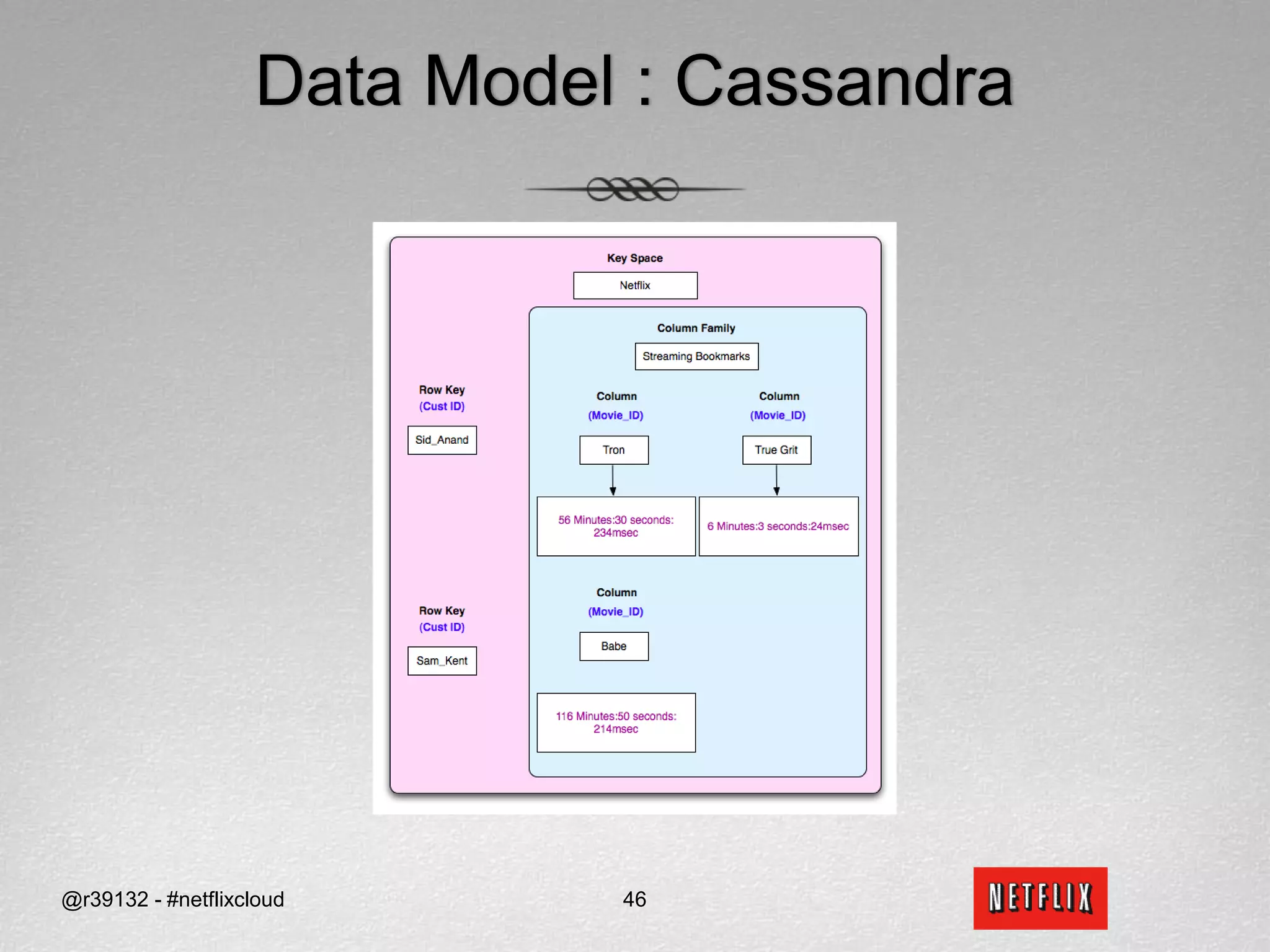
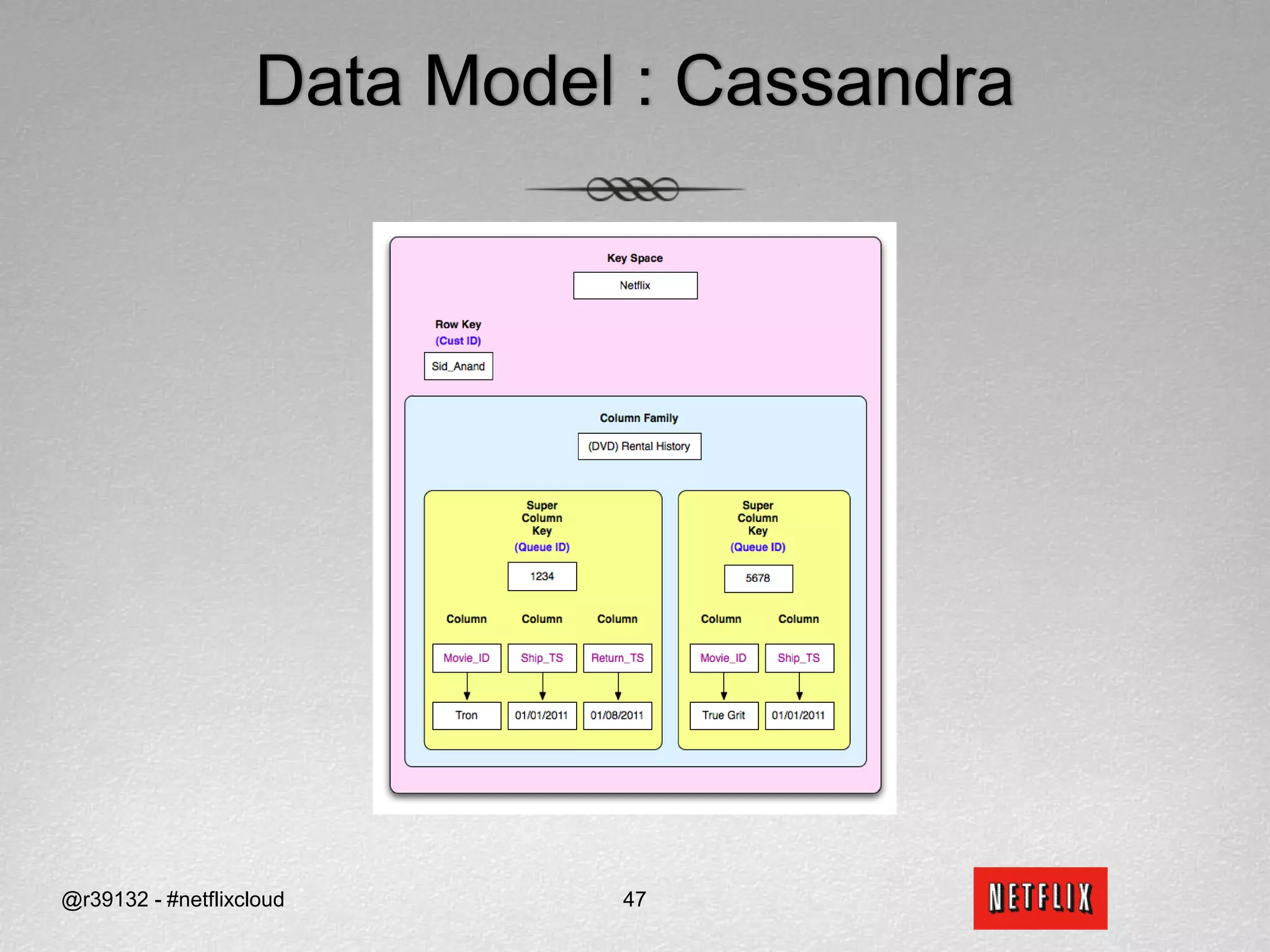




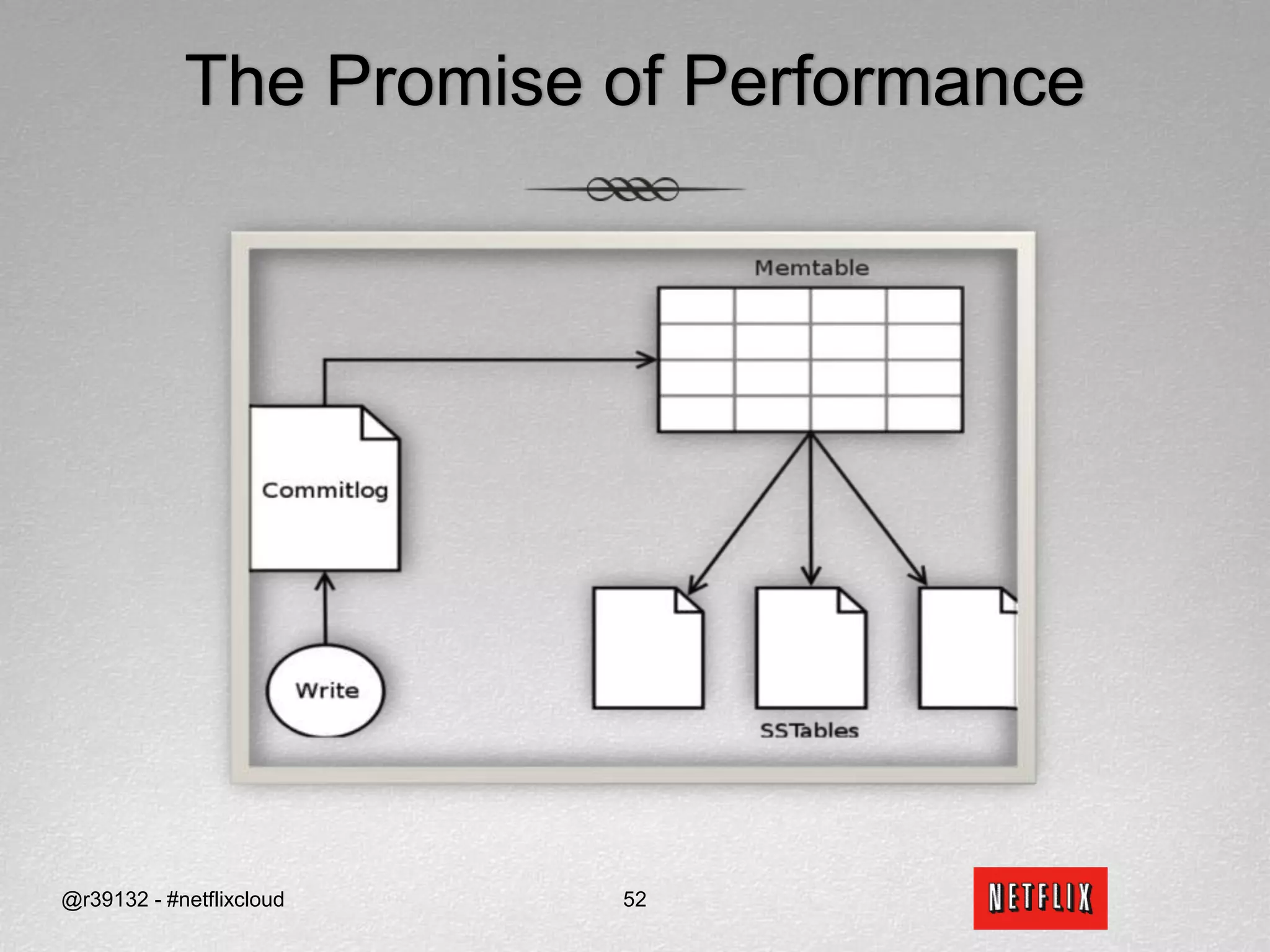






![APIs for ReadsReadsI want to continue watching Tron from where I left off (quorum reads)?datastore.get(“Netflix”, ”Sid_Anand”, Streaming Bookmarks Tron , ConsistencyLevel.QUORUM)When did the True Grit DVD get shipped and returned (fastest read)?datastore.get_slice(“Netflix”, ”Sid_Anand”, (DVD) Rental History 5678, [“Ship_TS”, “Return_TS”], ConsistencyLevel.ONE)How many DVD have been shipped to me (fastest read)?datastore.get_count(“Netflix”, ”Sid_Anand”, (DVD) Rental History, ConsistencyLevel.ONE)@r39132 - #netflixcloud49](https://image.slidesharecdn.com/svccgnosql2011v4-110218021733-phpapp01/75/Svccg-nosql-2011_v4-60-2048.jpg)






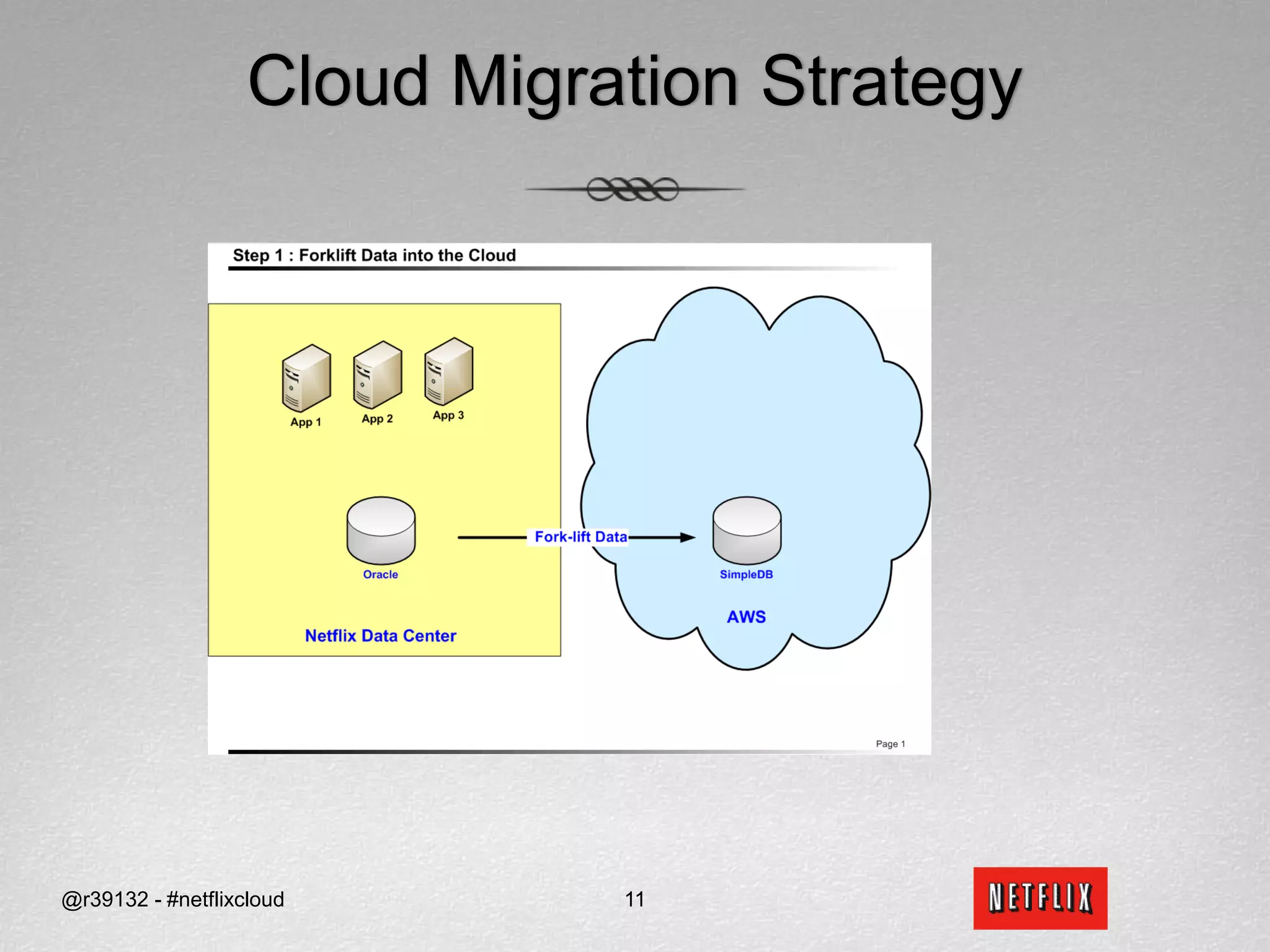
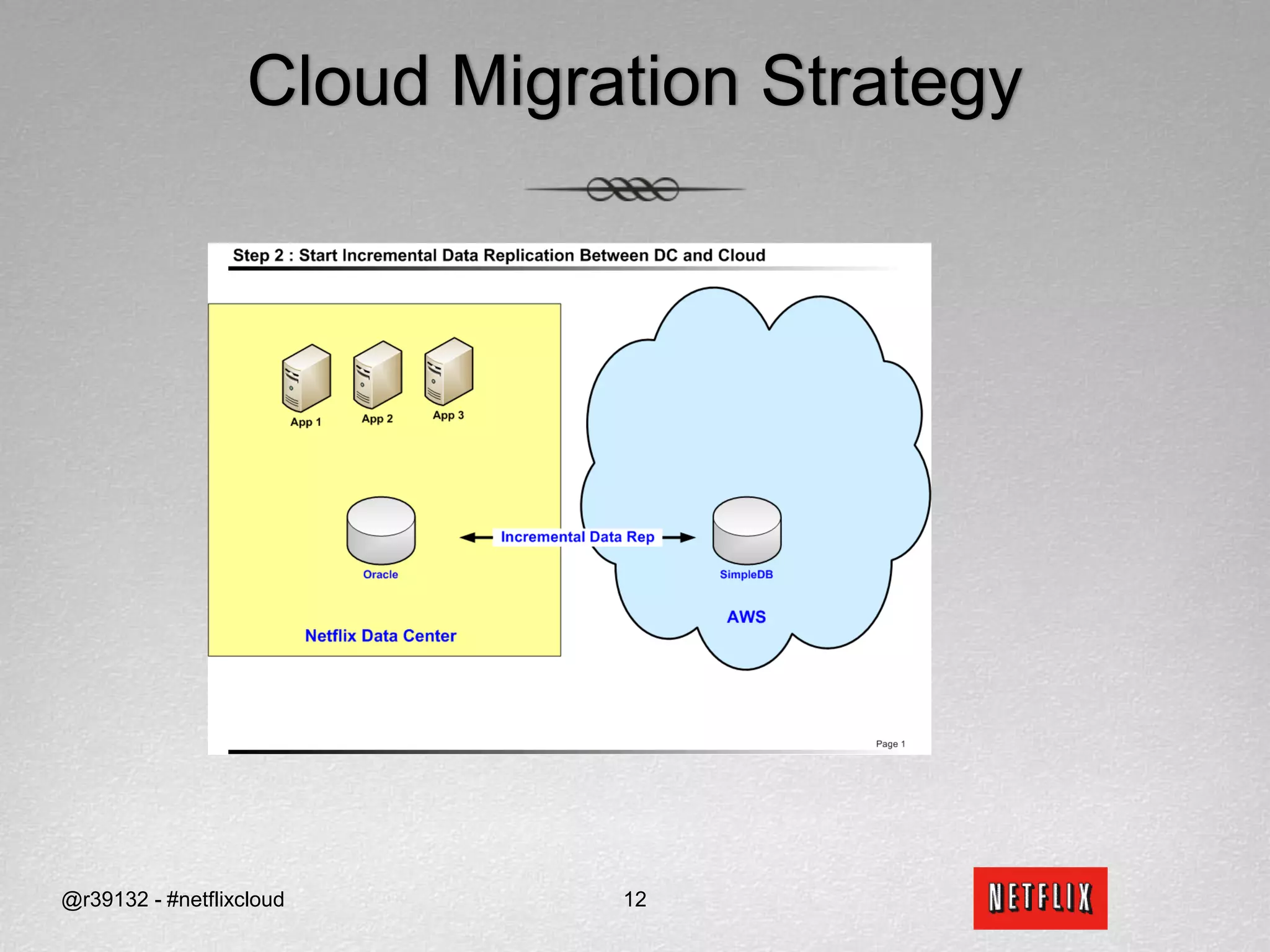
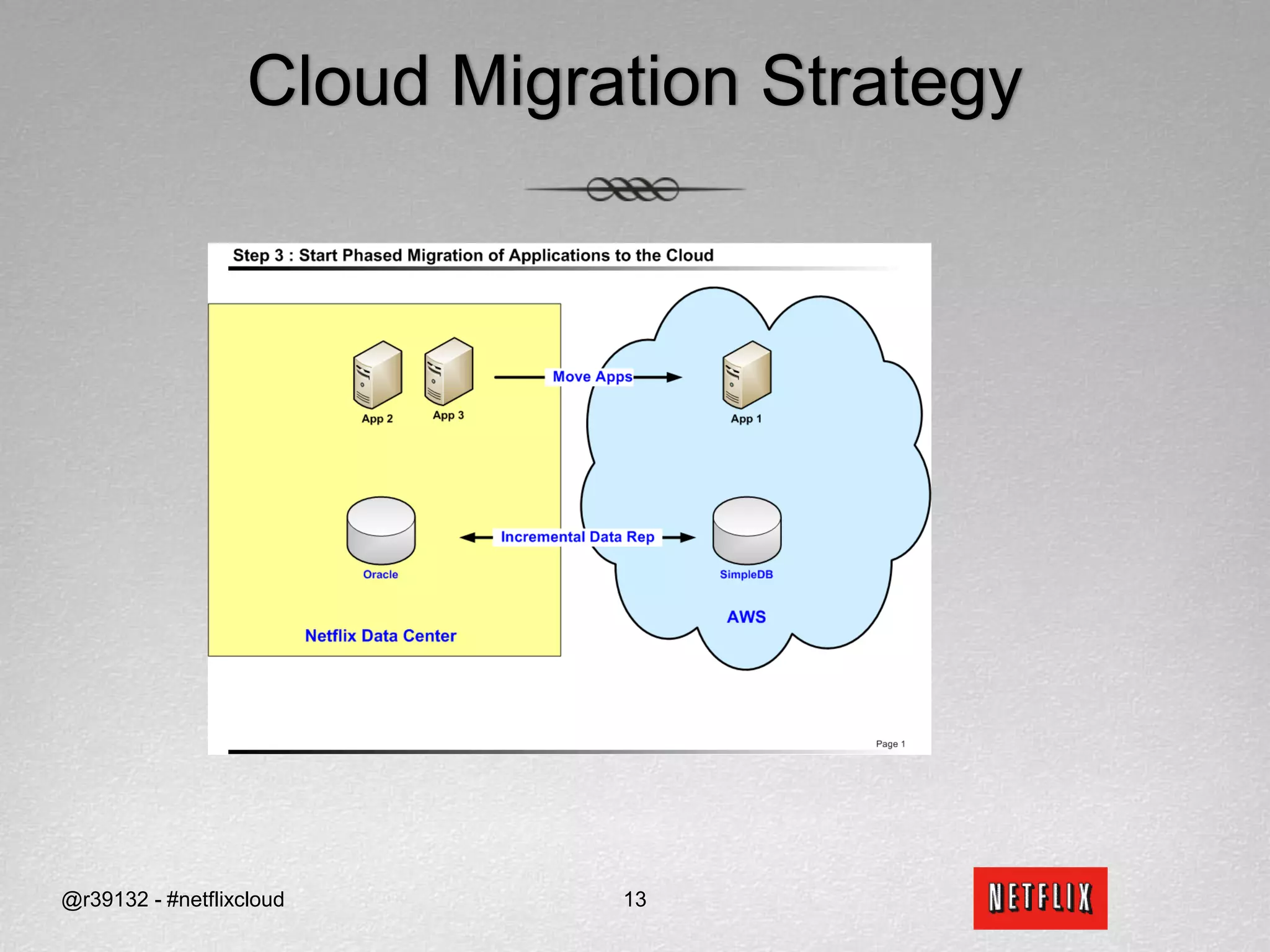
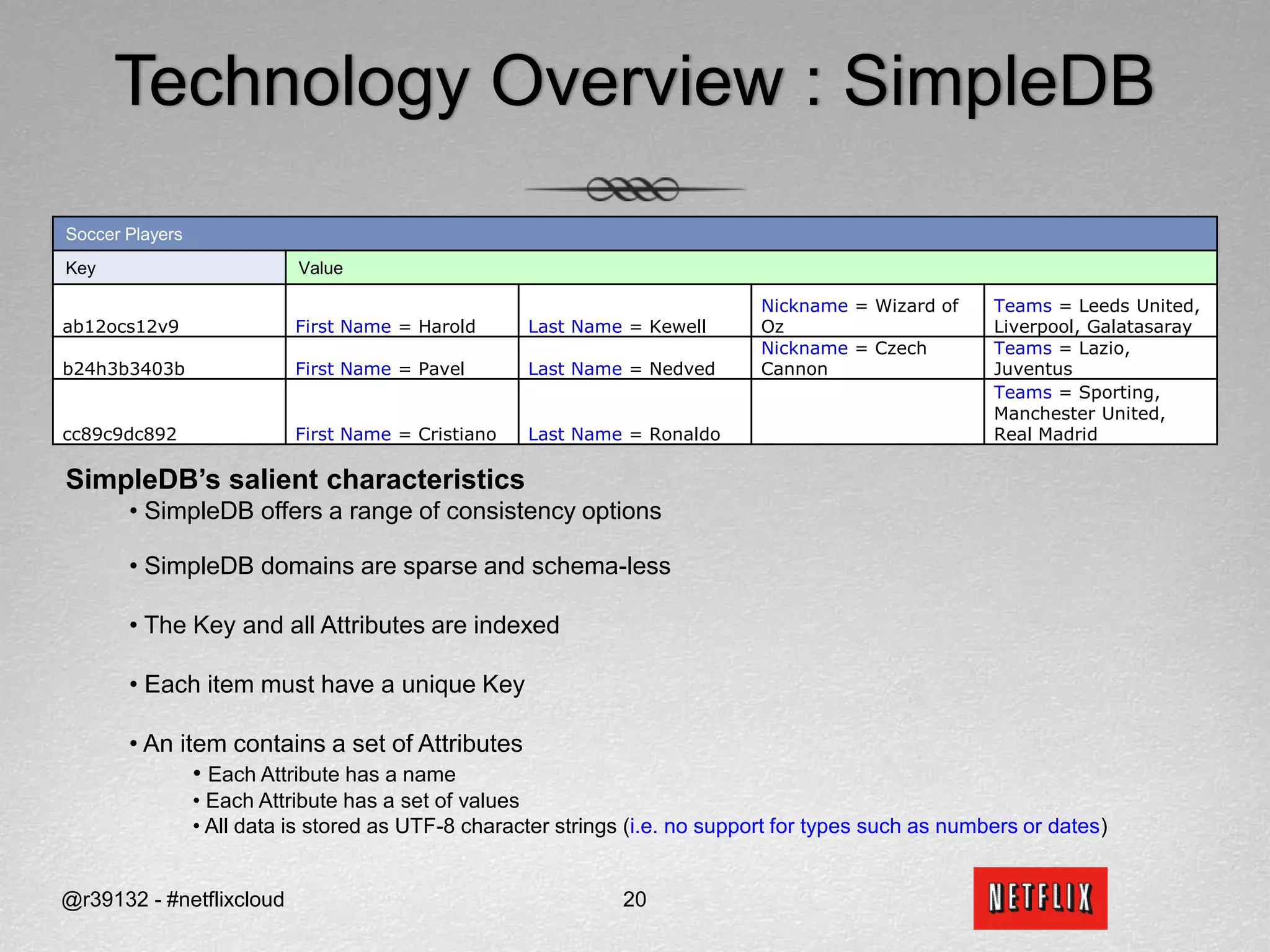
Netflix migrated to the cloud to avoid single points of failure and to focus on their core competencies. They chose Amazon Web Services and migrated non-sensitive data and applications to the cloud. Netflix picked SimpleDB and S3 as their data stores in the cloud. Migrating from an RDBMS required translating relational concepts like normalization to key-value stores and working around issues with SimpleDB like lack of data types and transactions.

![[오픈소스컨설팅] 아파치톰캣 운영가이드 v1.3](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsultingtomcatoperationguidev1-181113020525-thumbnail.jpg?width=640&height=640&fit=bounds)

































































