Download as PDF, PPTX



![About Me
3
Work [ed | s] @
Committer &
PPMC on
Father of 2
Co-Chair for
Apache Airflow](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-3-320.jpg)
![4
[ | ] @
& PPMC Apache Airflow](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-4-320.jpg)













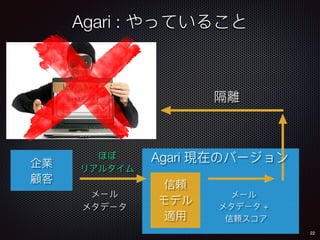


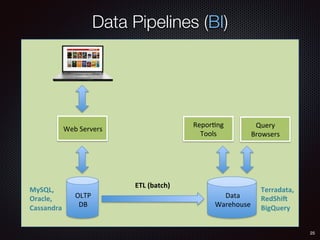
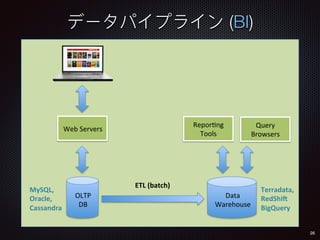
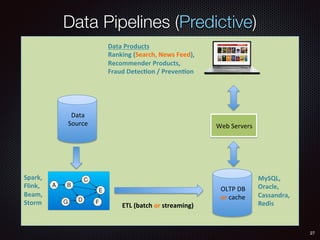
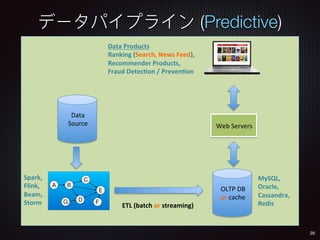

















































![136
Avro Schema Example
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-136-320.jpg)
![137
Avro
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-137-320.jpg)
![138
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
complex type (record)
Avro Schema Example](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-138-320.jpg)
![139
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
complex type (record)
Avro](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-139-320.jpg)
![140
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
complex type (record)
Schema name : User
Avro Schema Example](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-140-320.jpg)
![141
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
complex type (record)
Schema name : User
Avro](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-141-320.jpg)
![142
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
complex type (record)
Schema name : User
3 fields in the record: 1 required, 2
optional
Avro Schema Example](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-142-320.jpg)
![143
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
complex type (record)
Schema name : User
3
1 2
Avro](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-143-320.jpg)
![144
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
Data
x 1,000,000,000
Avro Schema Data File Example
Schema
Data
0.0001 %
99.999 %
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-144-320.jpg)
![145
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
Data
x 1,000,000,000
Avro
0.0001 %
99.999 %
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data
Data](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-145-320.jpg)
![146
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
Binary Data block
Avro Schema Streaming Example
Schema
Data
99 %
1 %
Data](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-146-320.jpg)
![147
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
Binary Data block
Avro
99 %
1 %
Data](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-147-320.jpg)
![148
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
Binary Data block
Avro Schema Streaming Example
Schema
Data
99 %
1 %
Data
OVERHEAD!!](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-148-320.jpg)
![149
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
Binary Data block
Avro
99 %
1 %
Data
!!](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-149-320.jpg)
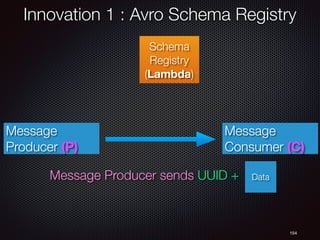
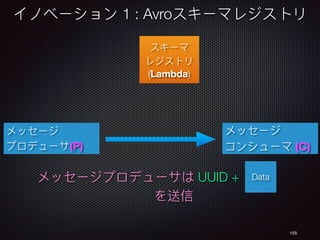
![150
Schema
Registry
(Lambda)
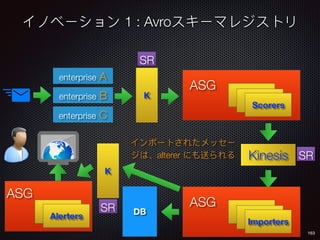
Innovation 1 : Avro Schema Registry
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
register_schema
Message
Producer (P)](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-150-320.jpg)
![151
(Lambda)
1 : Avro
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
register_schema
(P)](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-151-320.jpg)


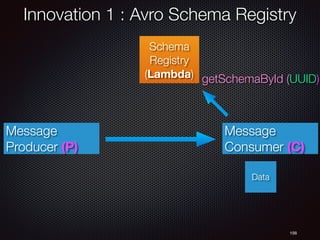
![158
Schema
Registry
(Lambda)
Innovation 1 : Avro Schema Registry
Message
Producer (P)
Data
Message
Consumer (C)
getSchemaById (UUID)
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-158-320.jpg)
![159
(Lambda)
1 : Avro
(P) (C)
getSchemaById (UUID)
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-159-320.jpg)
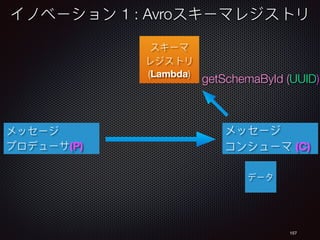
![160
Schema
Registry
(Lambda)
Innovation 1 : Avro Schema Registry
Message
Producer (P)
Message
Consumer (C)
getSchemaById (UUID)
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
Message Consumers
• download & cache the schema
• then decode the data](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-160-320.jpg)
![161
(Lambda)
1 : Avro
(P) (C)
getSchemaById (UUID)
{"namespace": "agari",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
• &
•](https://image.slidesharecdn.com/cndpv6ja-161104072537/85/Cloud-Native-Data-Pipelines-in-Eng-Japanese-QCon-Tokyo-161-320.jpg)
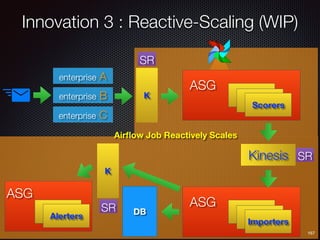
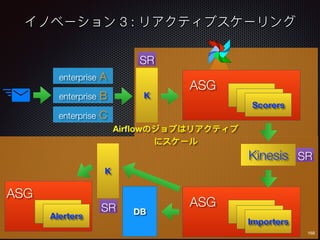
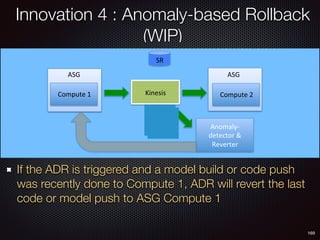
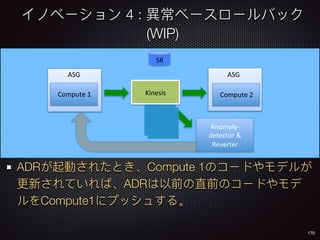







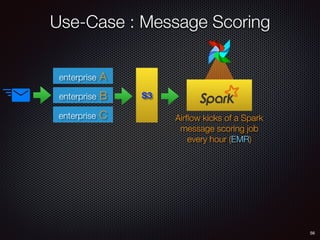
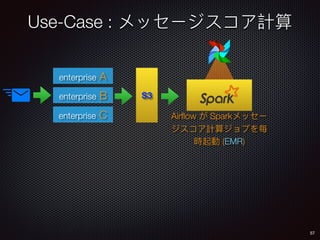
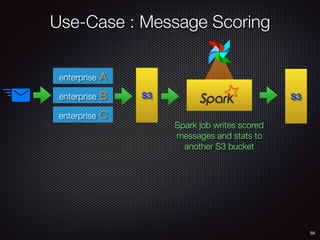
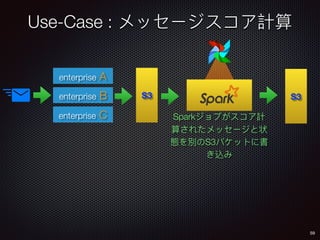
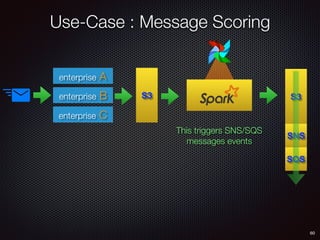
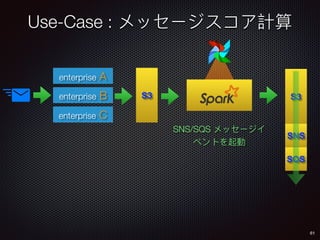
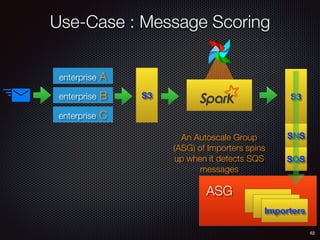
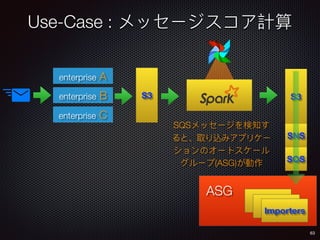
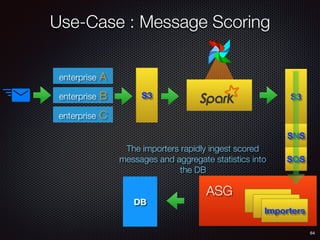
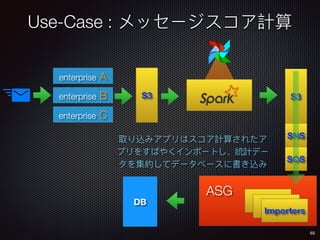
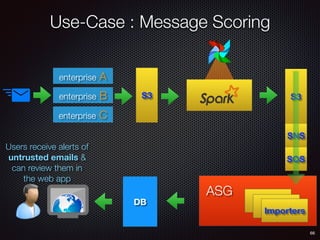
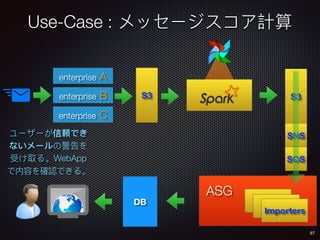
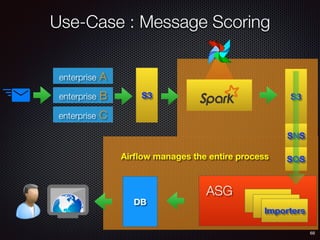
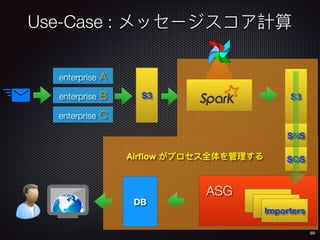
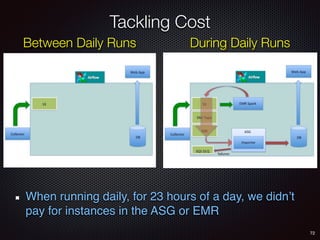
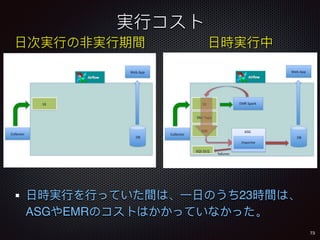
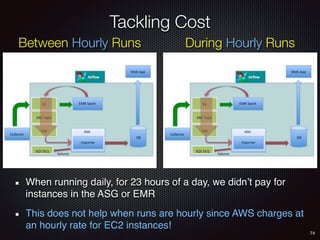
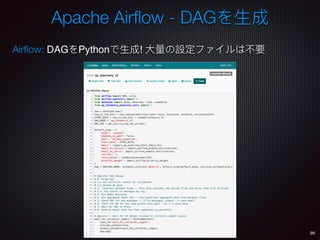
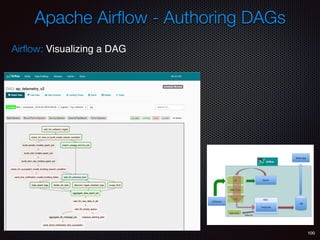
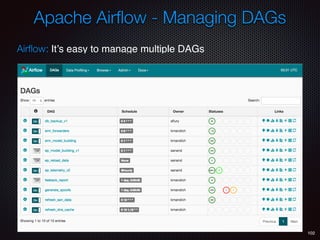
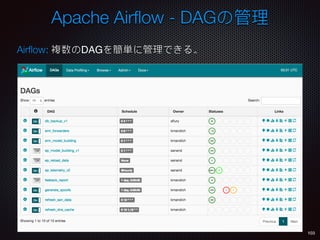
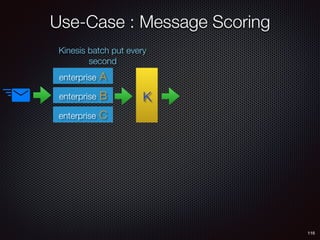
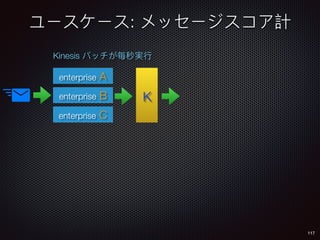
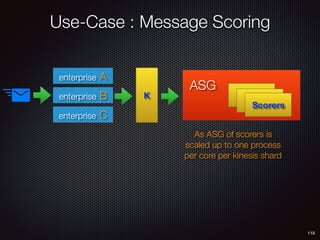
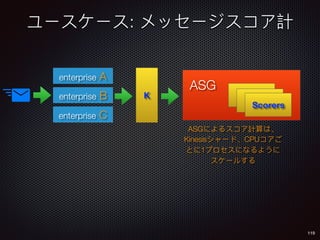
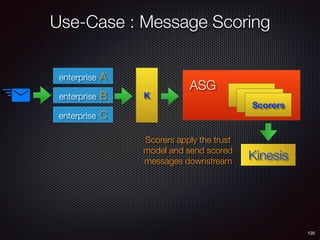
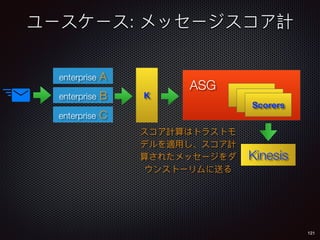
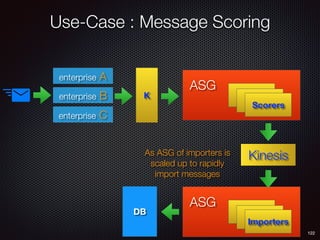
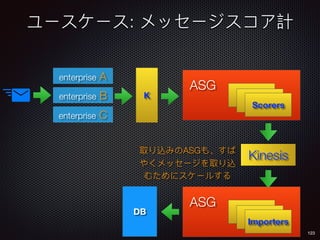
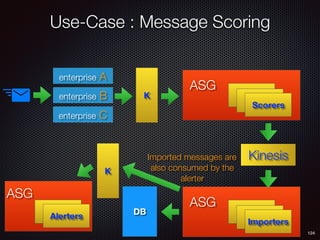
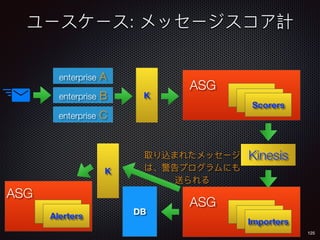
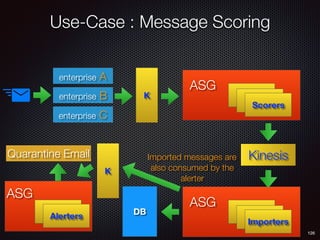
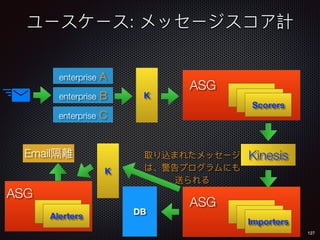
Sid Anand discusses cloud-native data pipelines, highlighting the need for big data companies to build large-scale pipelines that can run in the public cloud. The presentation covers key architectural components, including batch and near-real-time processing, and emphasizes the importance of operability, correctness, and cost efficiency in designing data pipelines. Additionally, he explores how tools like Apache Airflow facilitate workflow management in analytics use cases, particularly for message scoring in organizations.


































































































