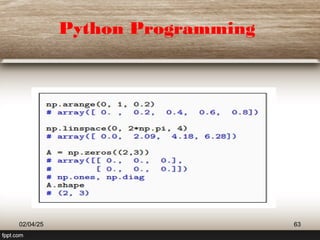
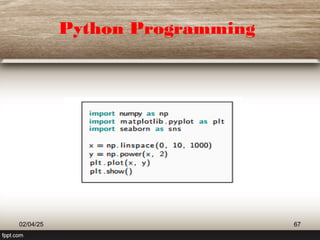
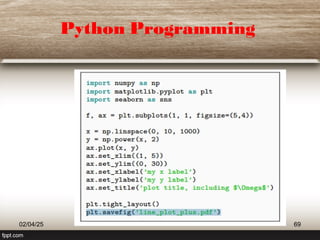
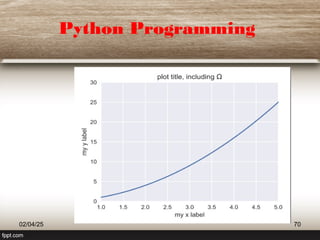
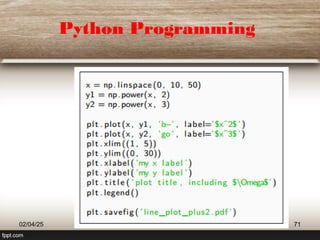
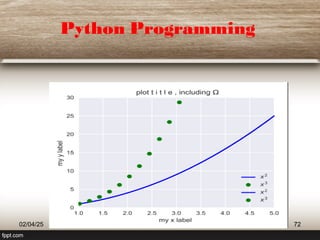
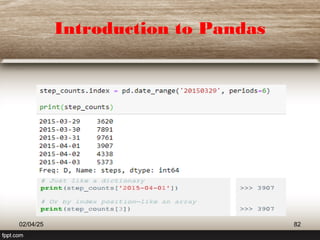
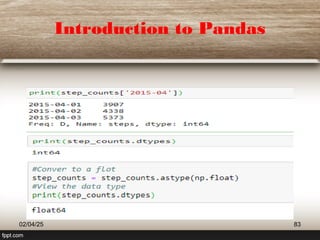
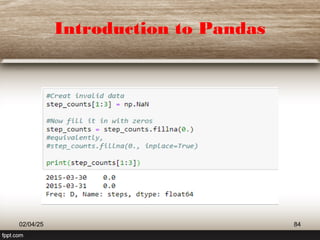
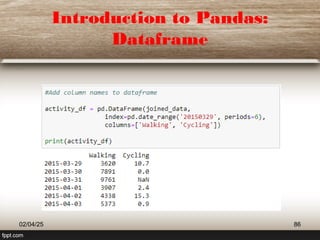
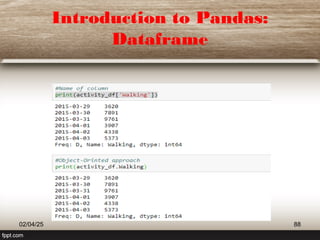
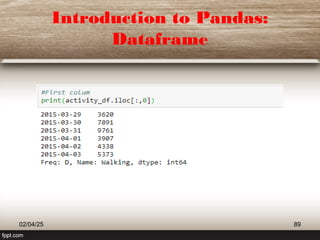
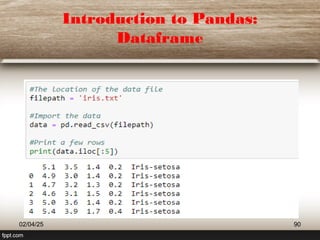
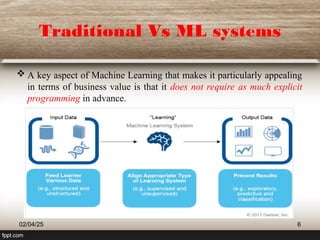
This document provides a comprehensive overview of machine learning (ML) concepts, focusing on the k-nearest neighbors (KNN) algorithm. It discusses the importance of data quality, the distinctions between supervised and unsupervised learning, and outlines the process of developing ML applications. Additionally, it highlights the use of Python in ML and the steps involved in data collection and preparation.





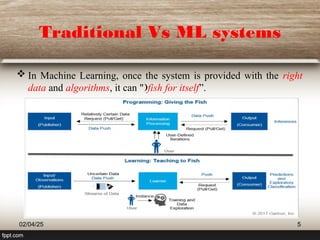











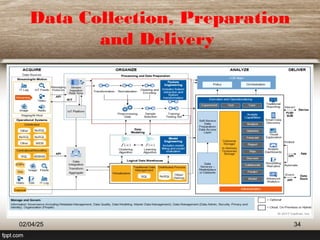
![Machine Learning Systems and
Data
Having a clear dataset is not always enough.
Features with large magnitudes can dominate features with small
magnitudes during the training.
Example: Age [0-100], salary [6,000 – 20,000] – Scaling and
Standardization
Data imbalance:
02/04/25 23
No Classes Number
1 Cat 5000
2 Dog 5000
3 Tiger 150
4 Cow 25
Leave as it is.
Under sampling (if all classes are
equally important) [5000 – 25]
Over sampling (if all classes are
equally important) [25-5000]](https://image.slidesharecdn.com/lecture-2classificationmachinelearningbasicandknn-250204120222-75fe7764/85/Lecture-2-Classification-Machine-Learning-Basic-and-kNN-ppt-23-320.jpg)














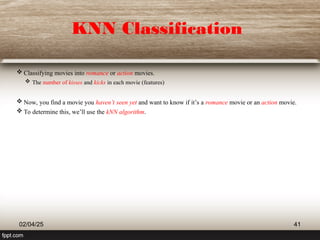

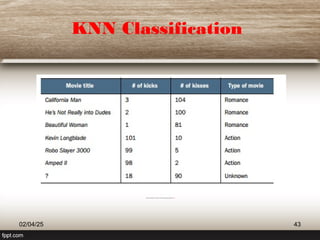







![K-Nearest Neighbors Bias
Preference Bias?
Our believe about what makes a good hypothesis.
Locality: near points are similar (distance function / domain)
Smoothness: averaging
All features matter equally.
Best practices for Data preparation
Rescale data: normalizing the data to the range [0, 1] is a good idea.
Address missing data: excluded or imputed the missing values.
Lower dimensionality: KNN is suitable for lower dimensional data.
02/04/25 54](https://image.slidesharecdn.com/lecture-2classificationmachinelearningbasicandknn-250204120222-75fe7764/85/Lecture-2-Classification-Machine-Learning-Basic-and-kNN-ppt-54-320.jpg)

![Some Other Issues
What is needed to select a KNN model?
How to measure closeness of neighbors.
Correct value for K.
d(x, q) = Euclidian, Manhattan, weighted etc…
The choice of the distance function matters.
K value:
K = n (the average of all data / no need of query)
K = n (weighted average) [Locally weighted regression]
02/04/25 56](https://image.slidesharecdn.com/lecture-2classificationmachinelearningbasicandknn-250204120222-75fe7764/85/Lecture-2-Classification-Machine-Learning-Basic-and-kNN-ppt-56-320.jpg)