Download as PDF, PPTX
















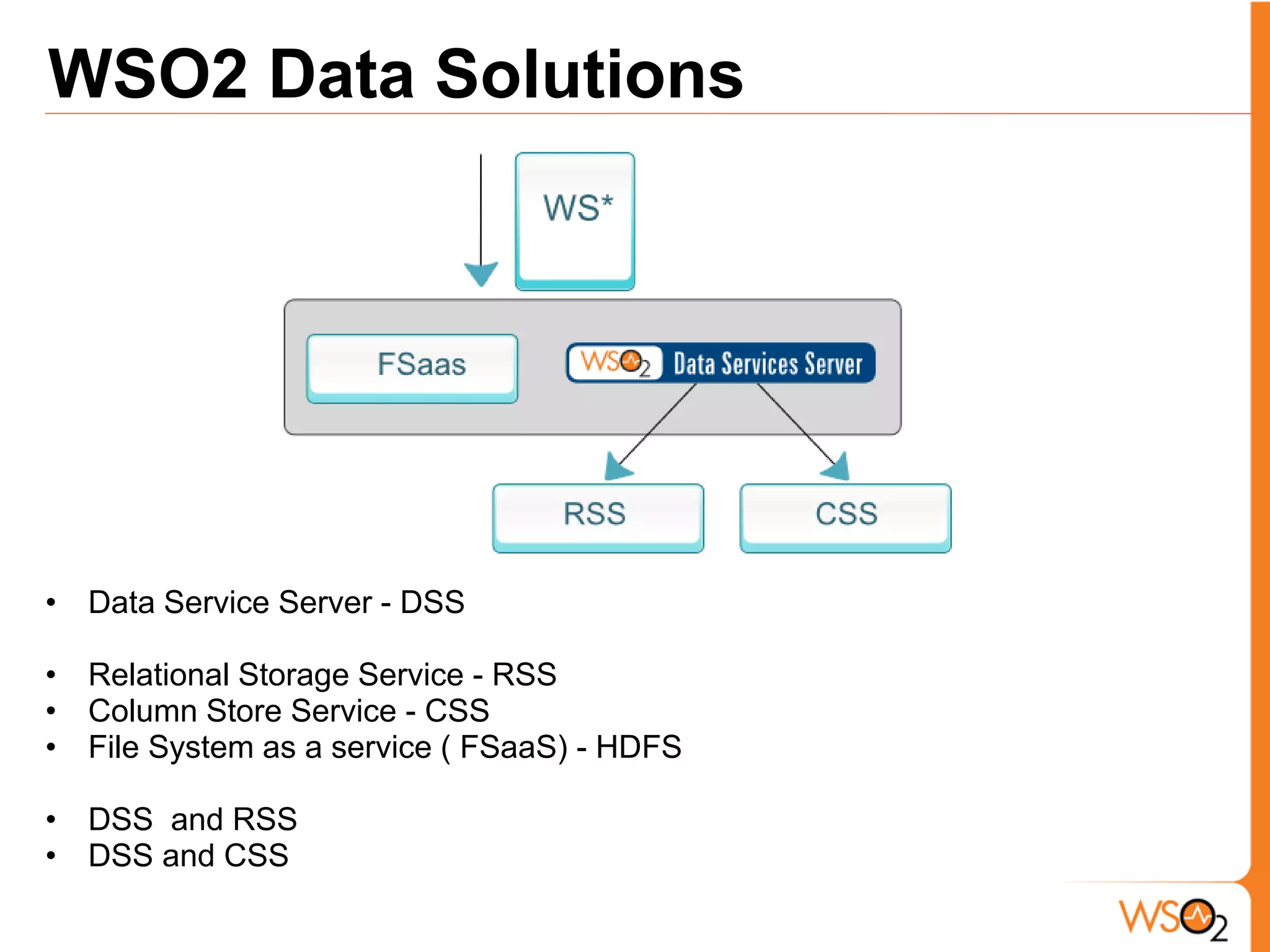
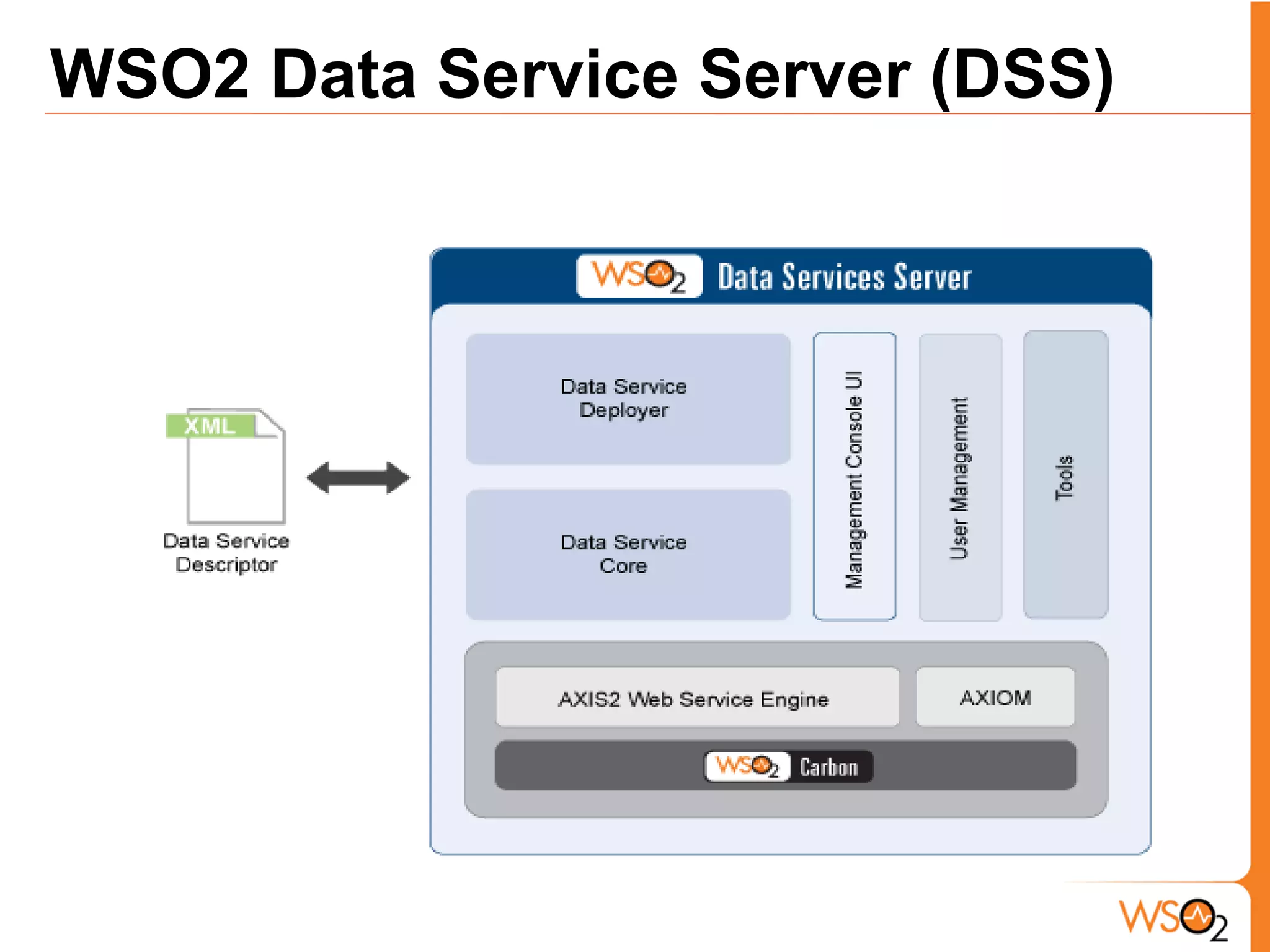



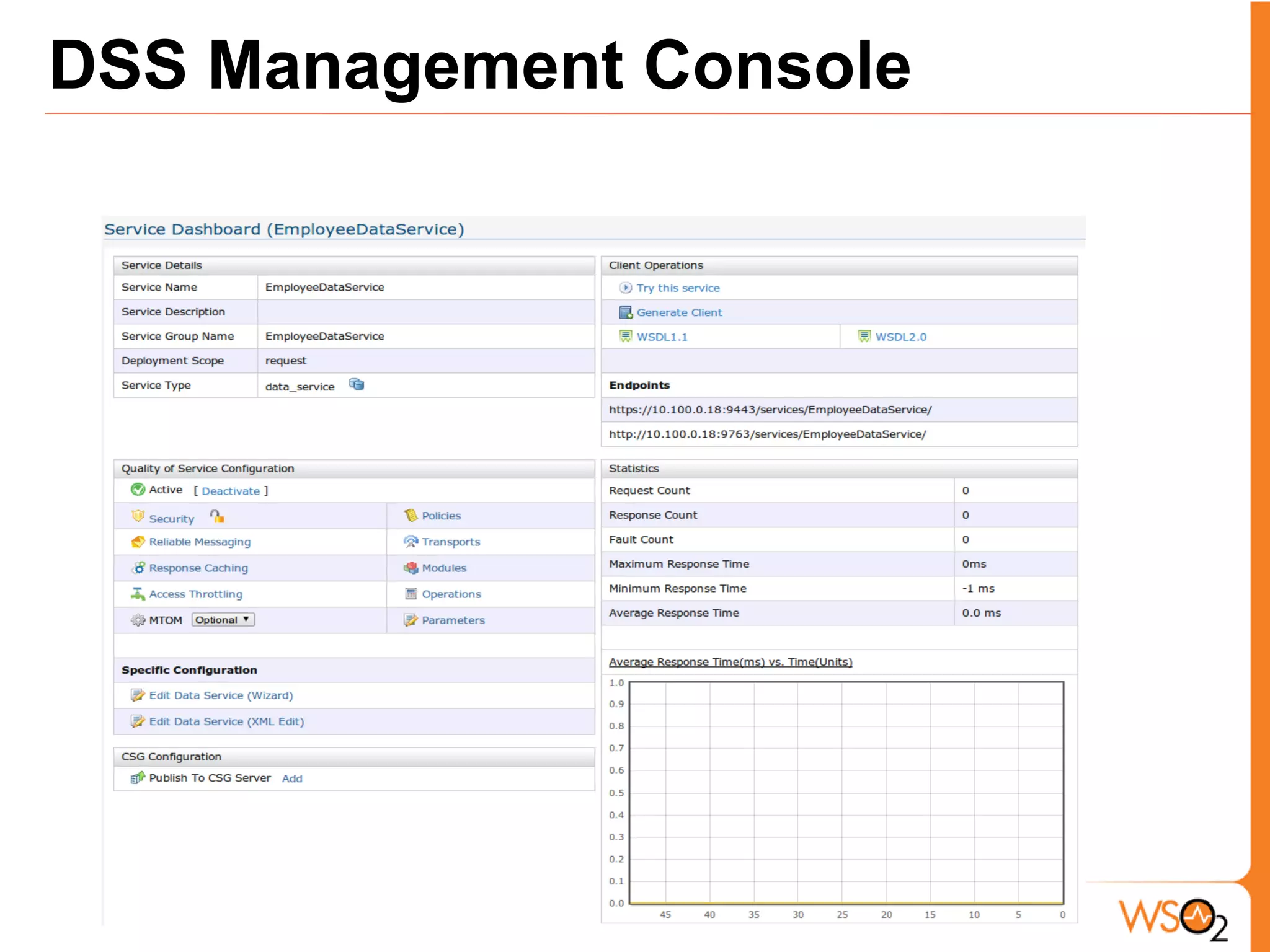
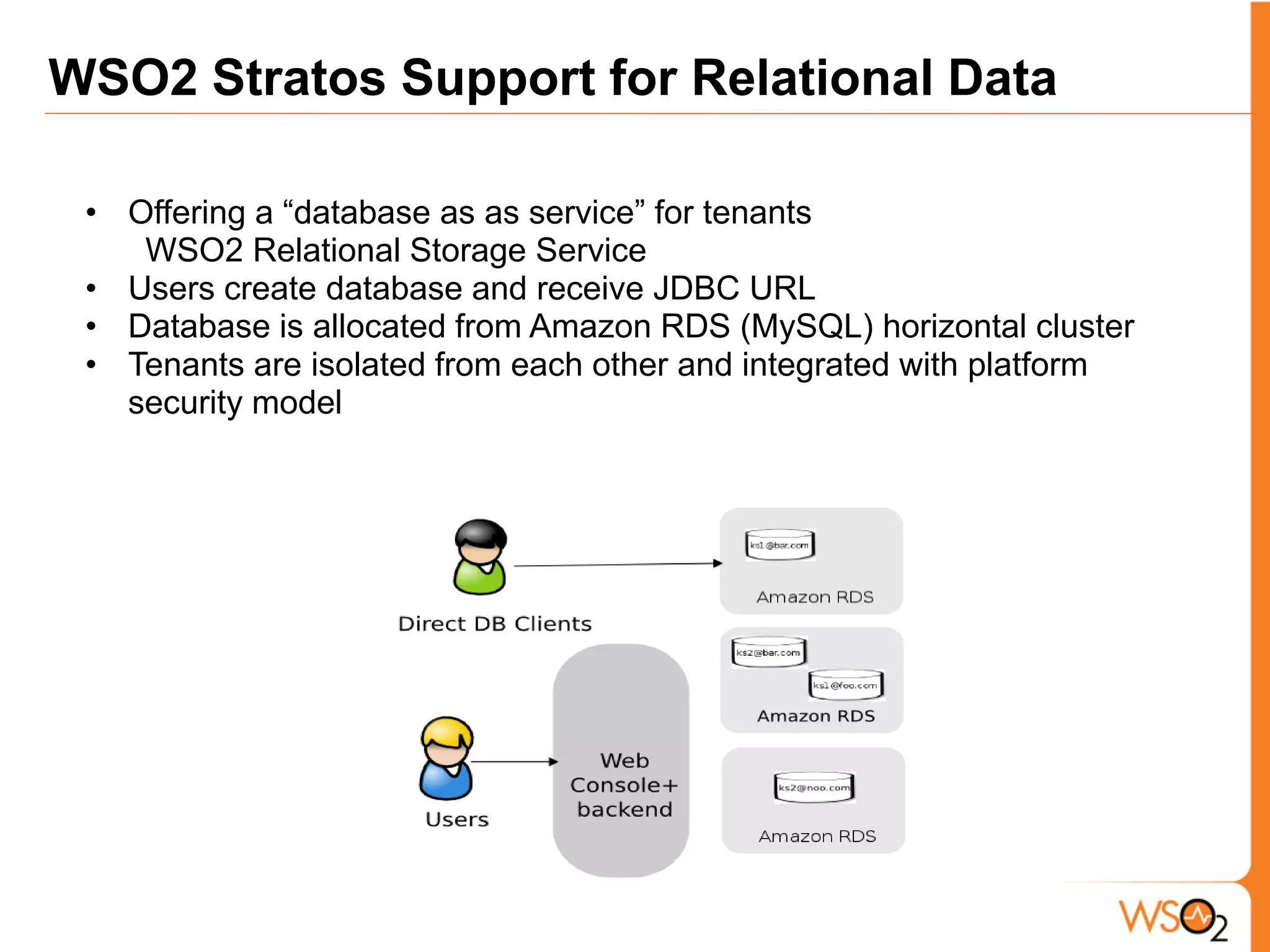

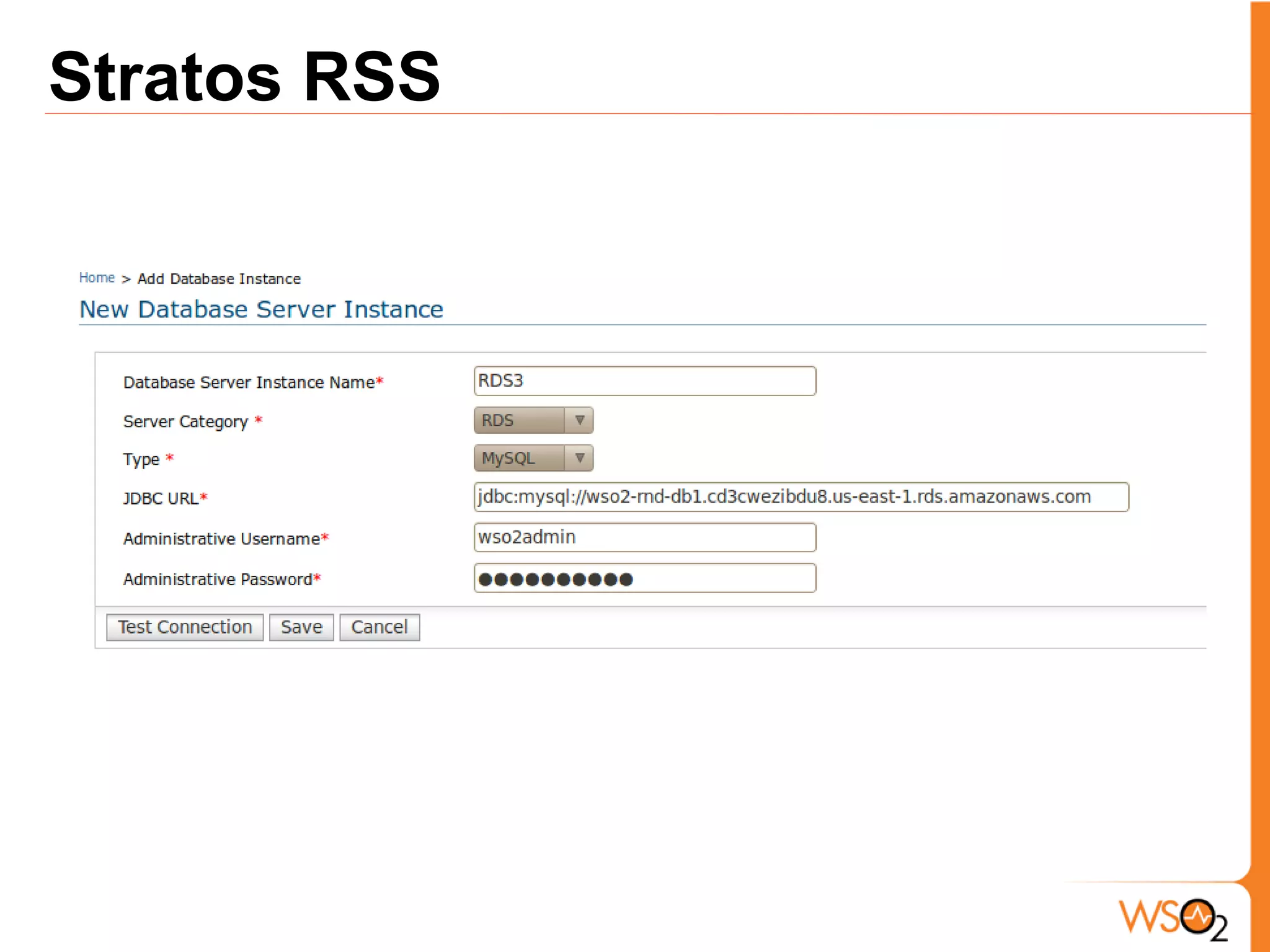
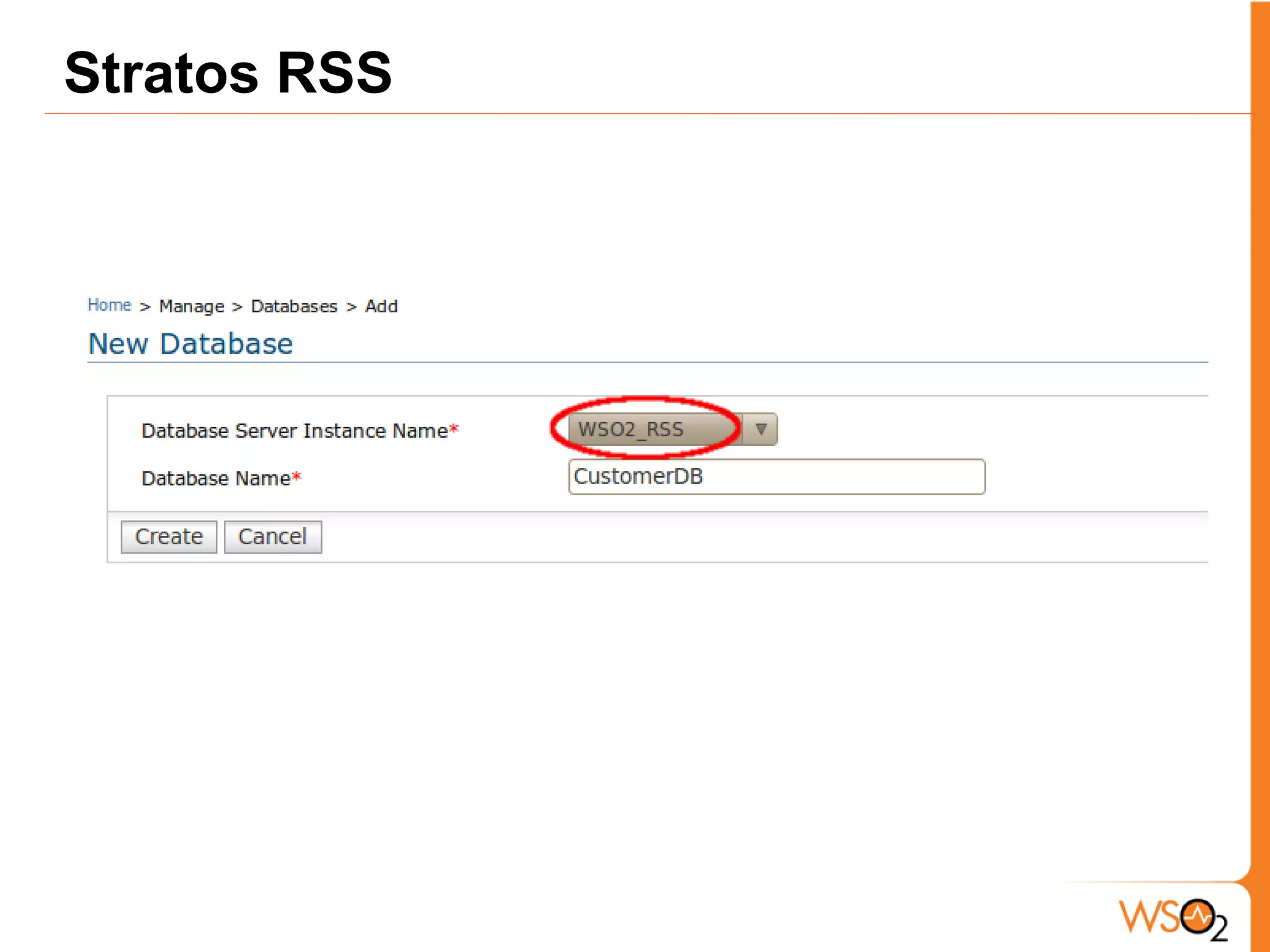
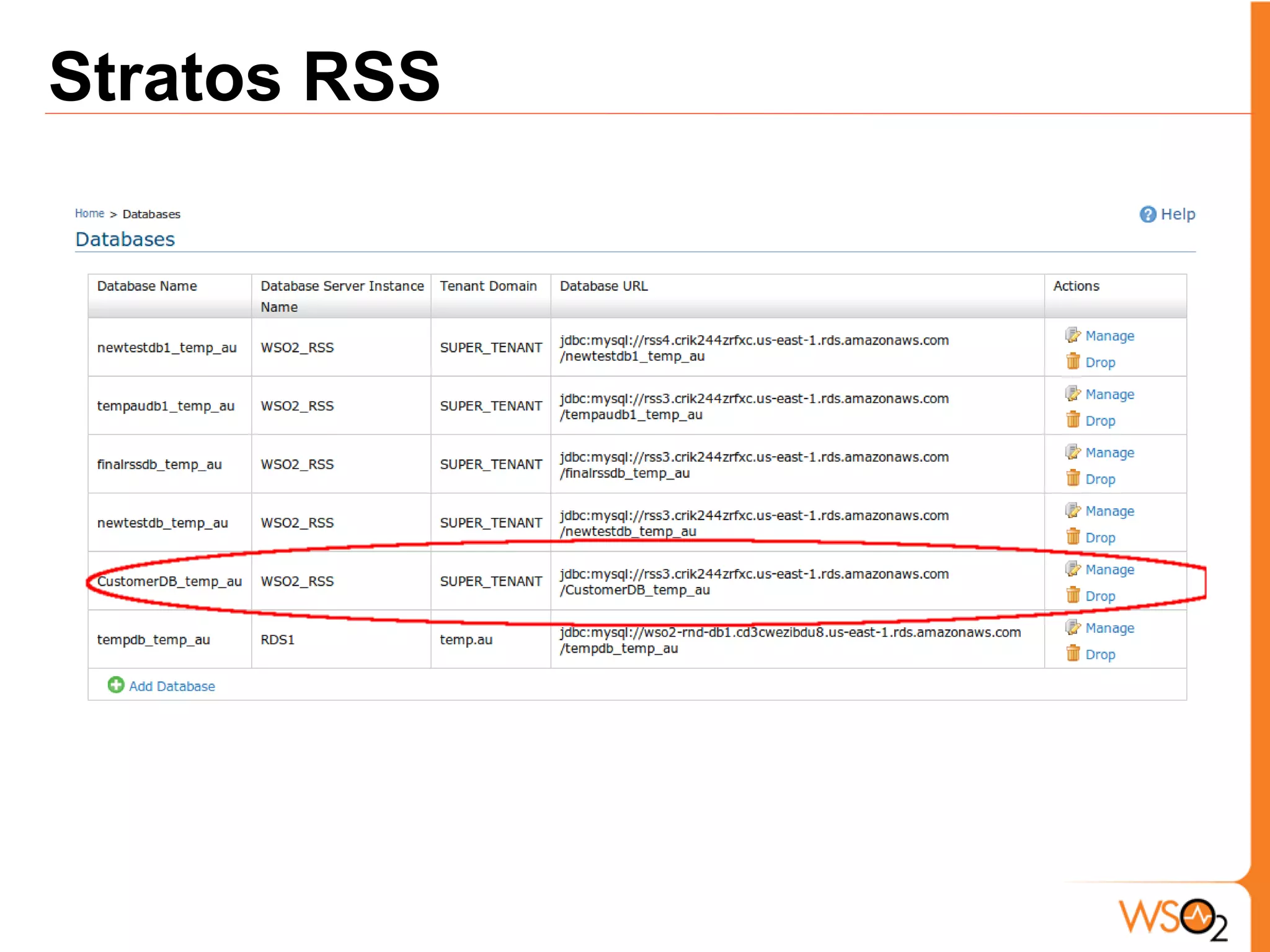

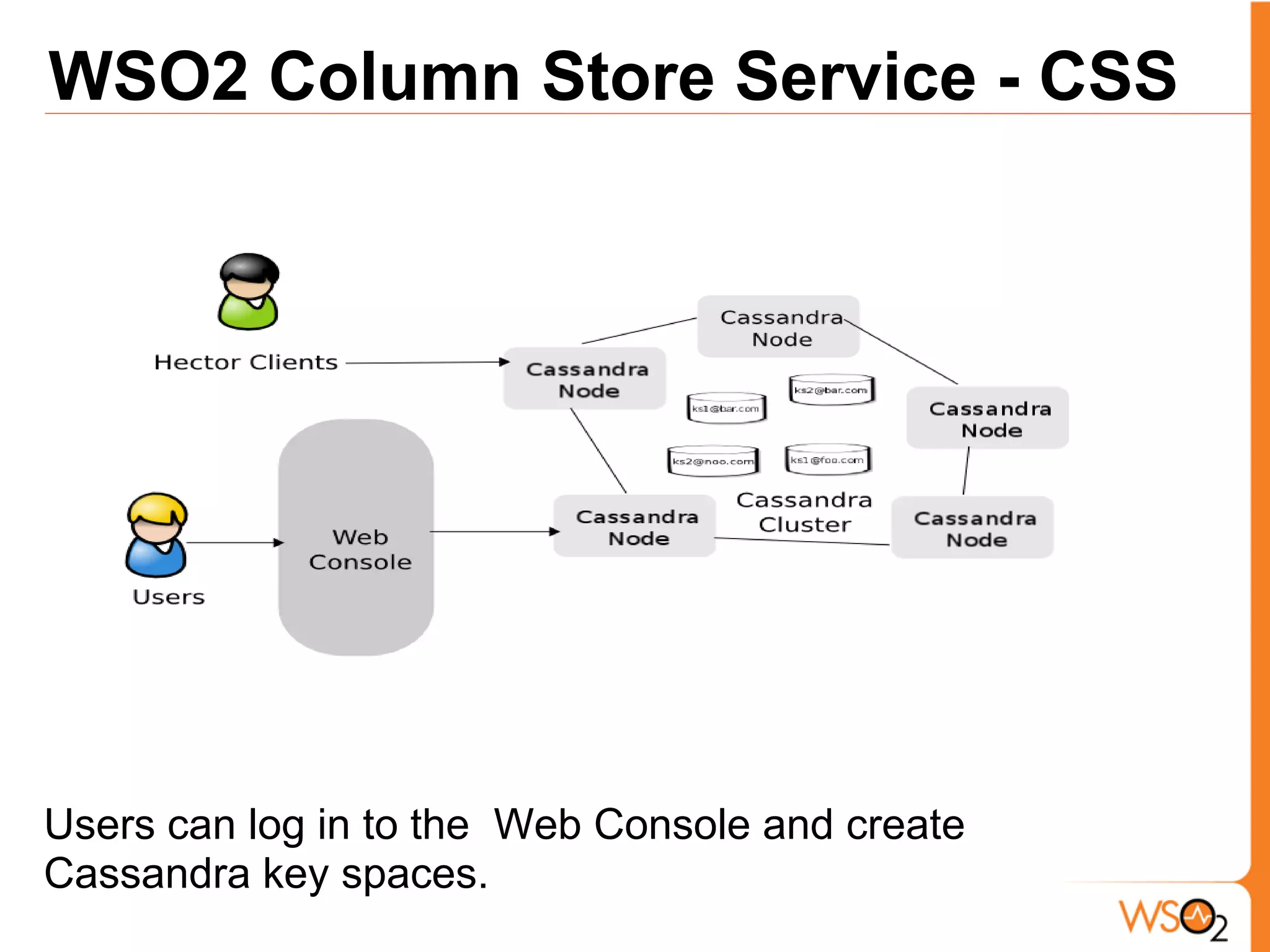

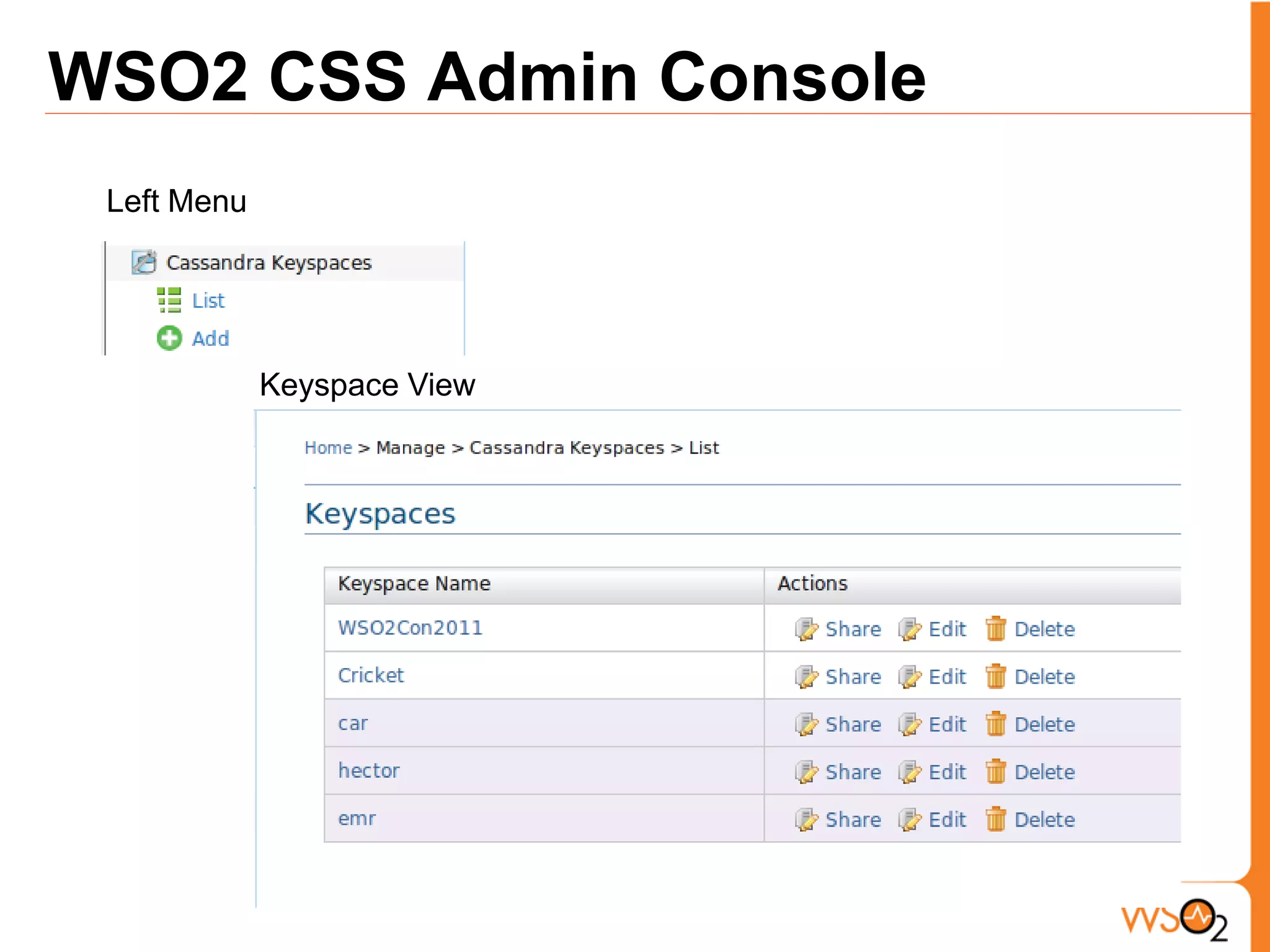
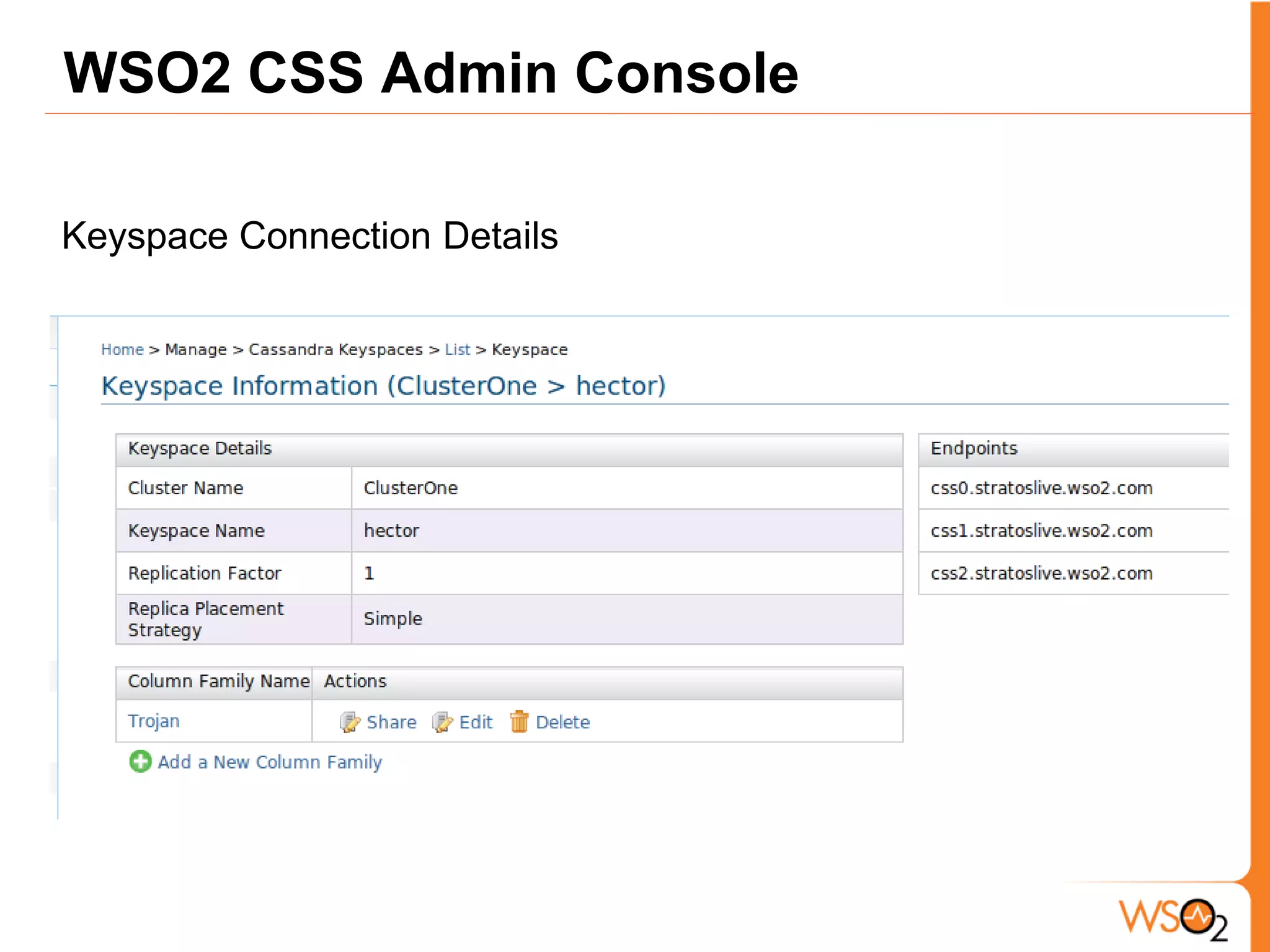

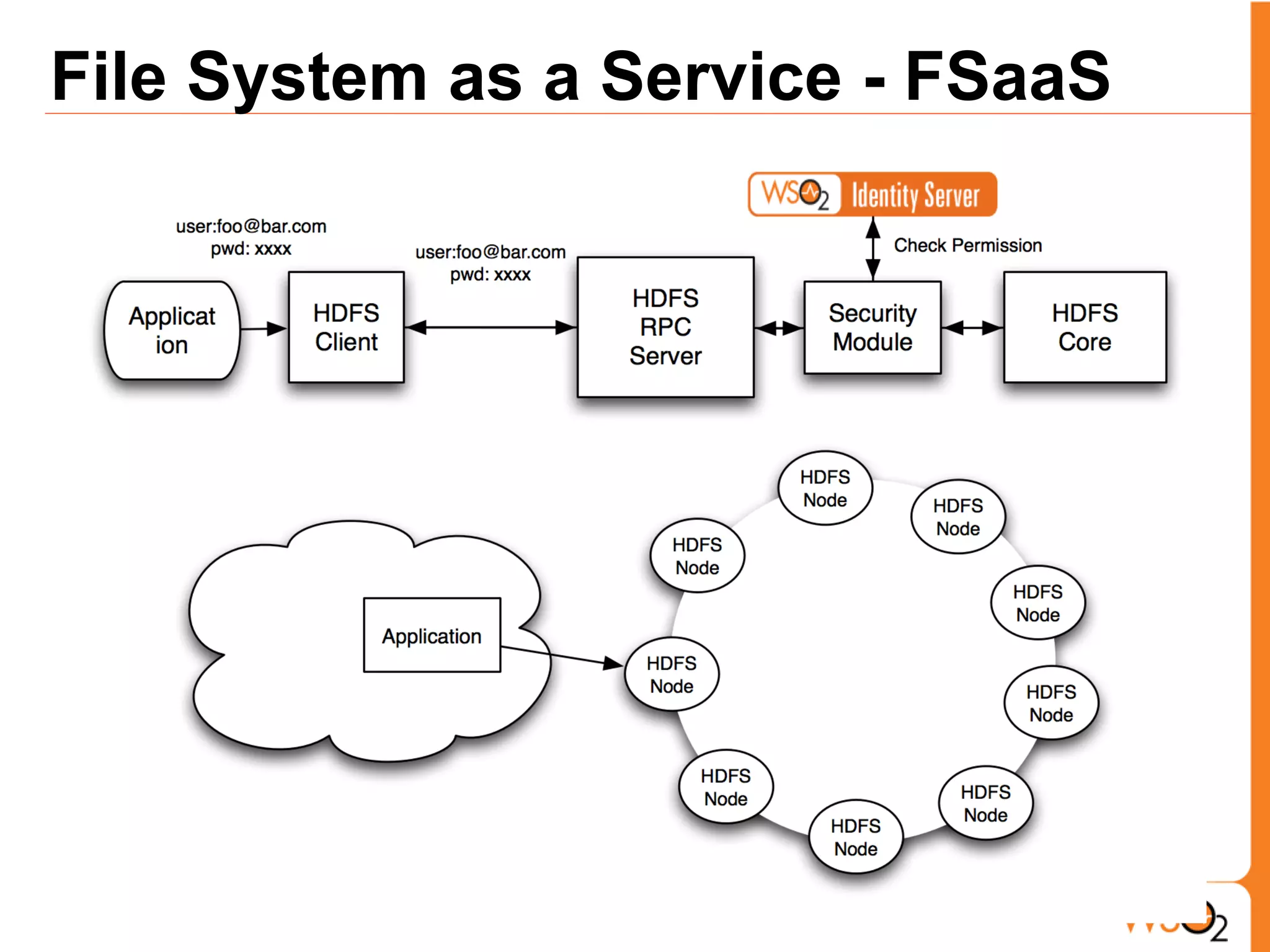



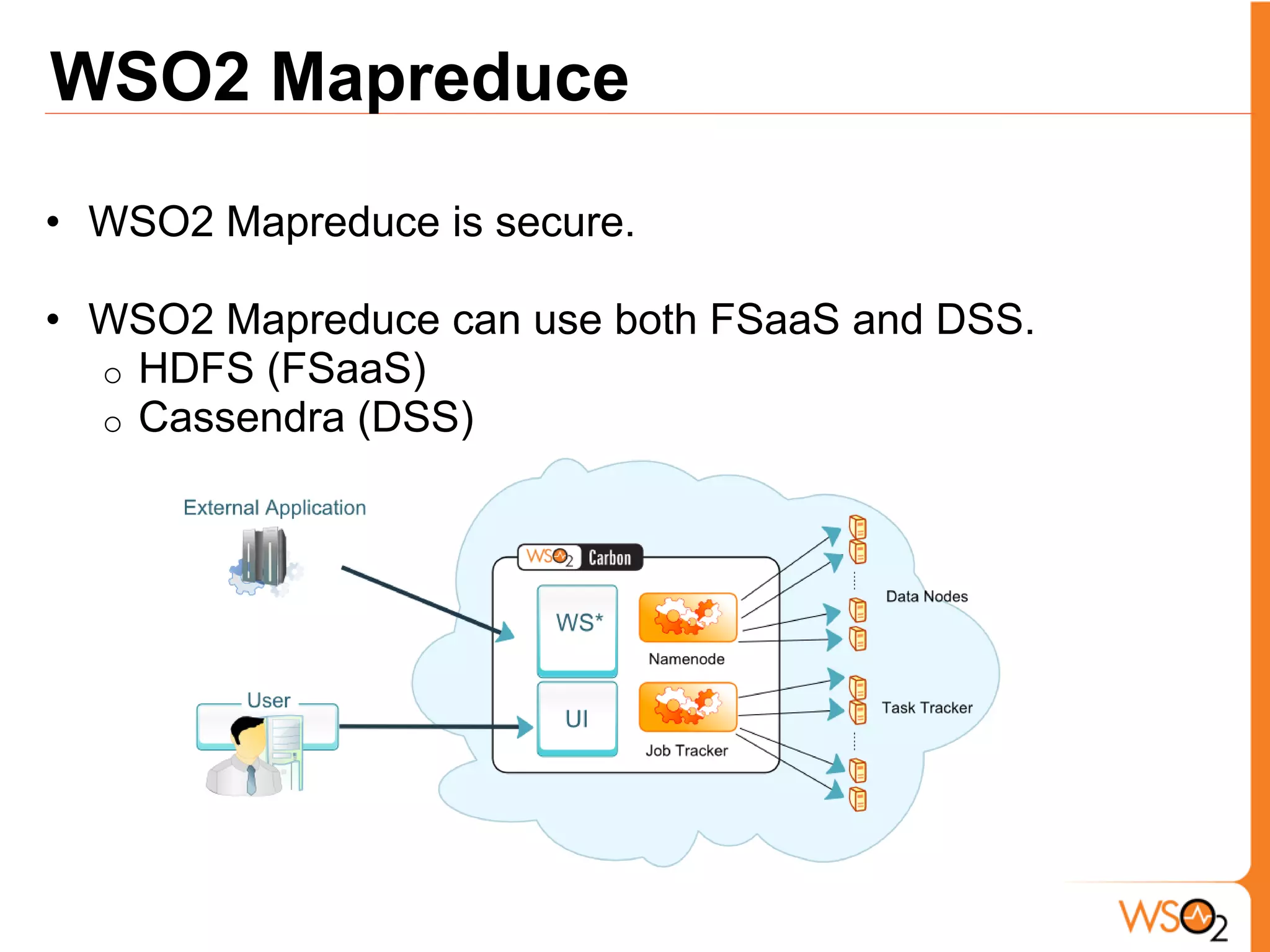
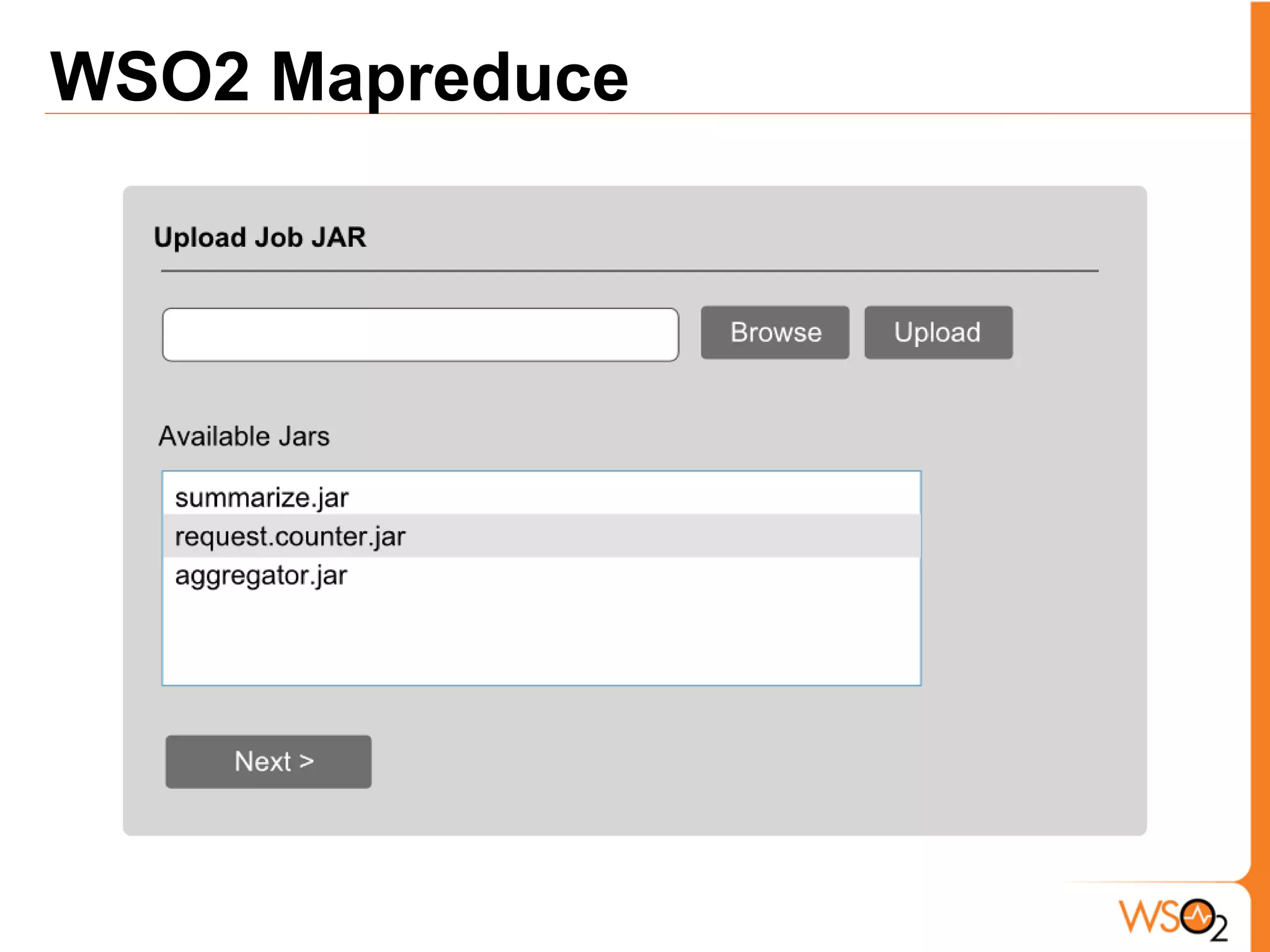
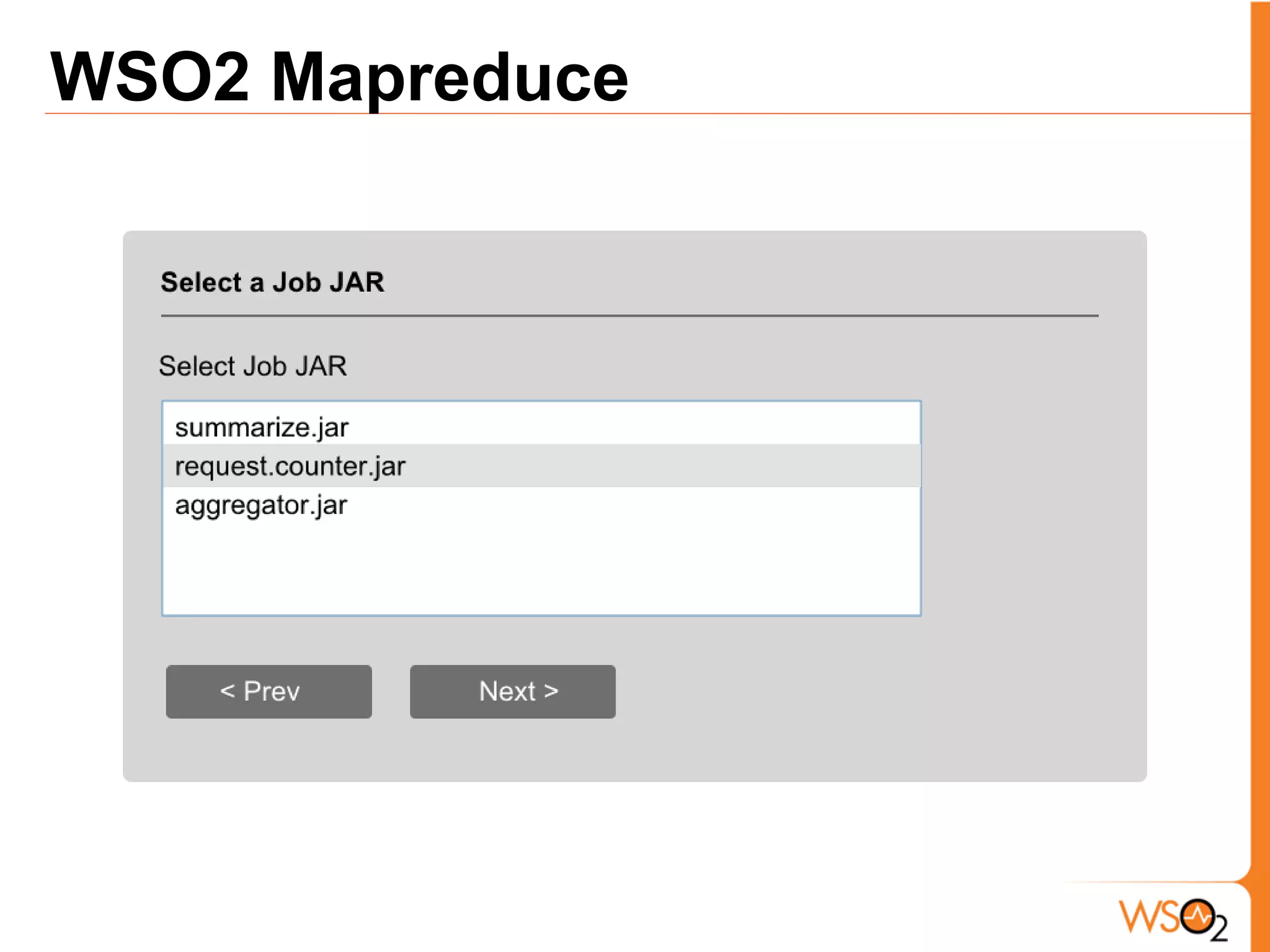
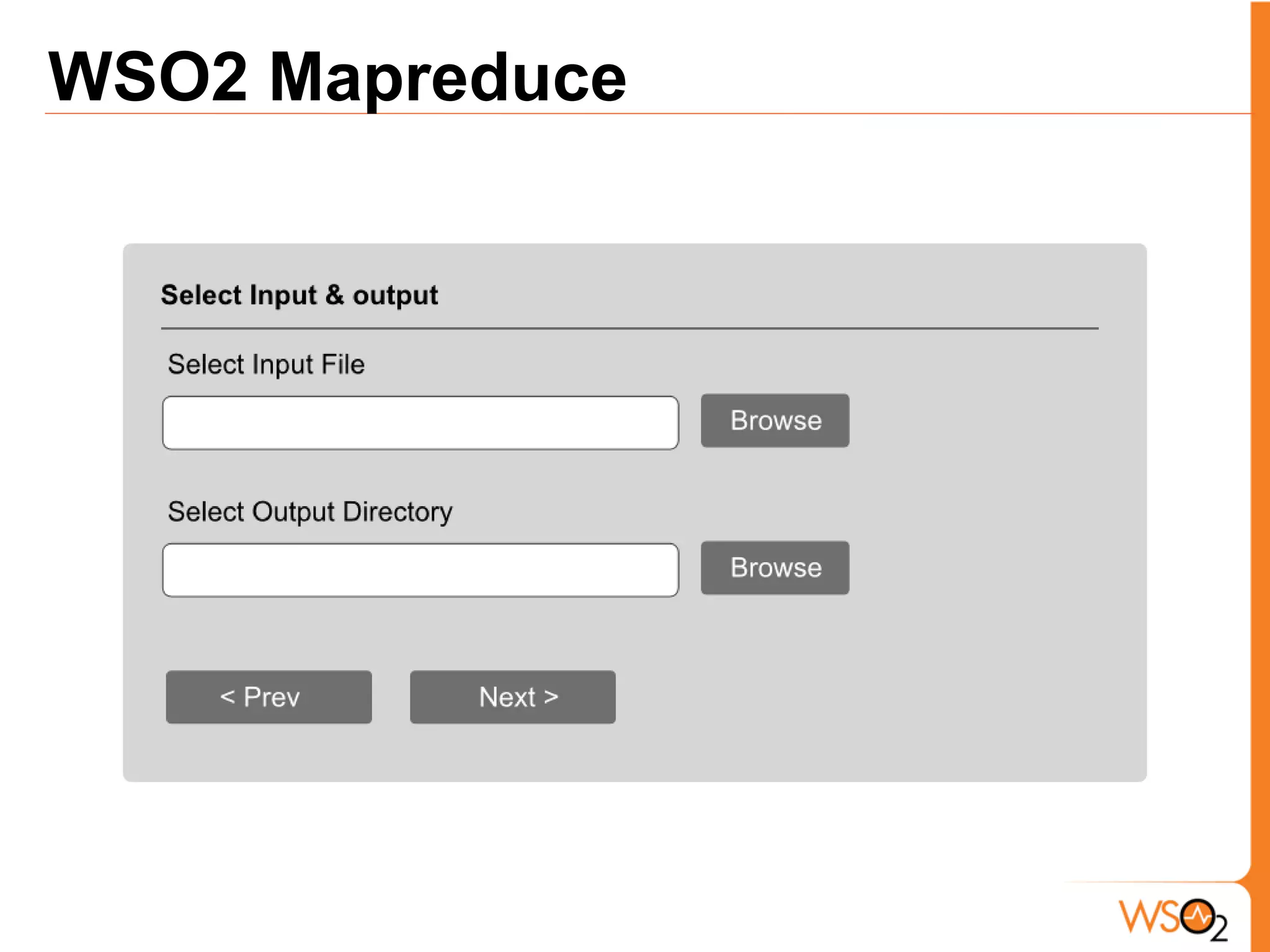
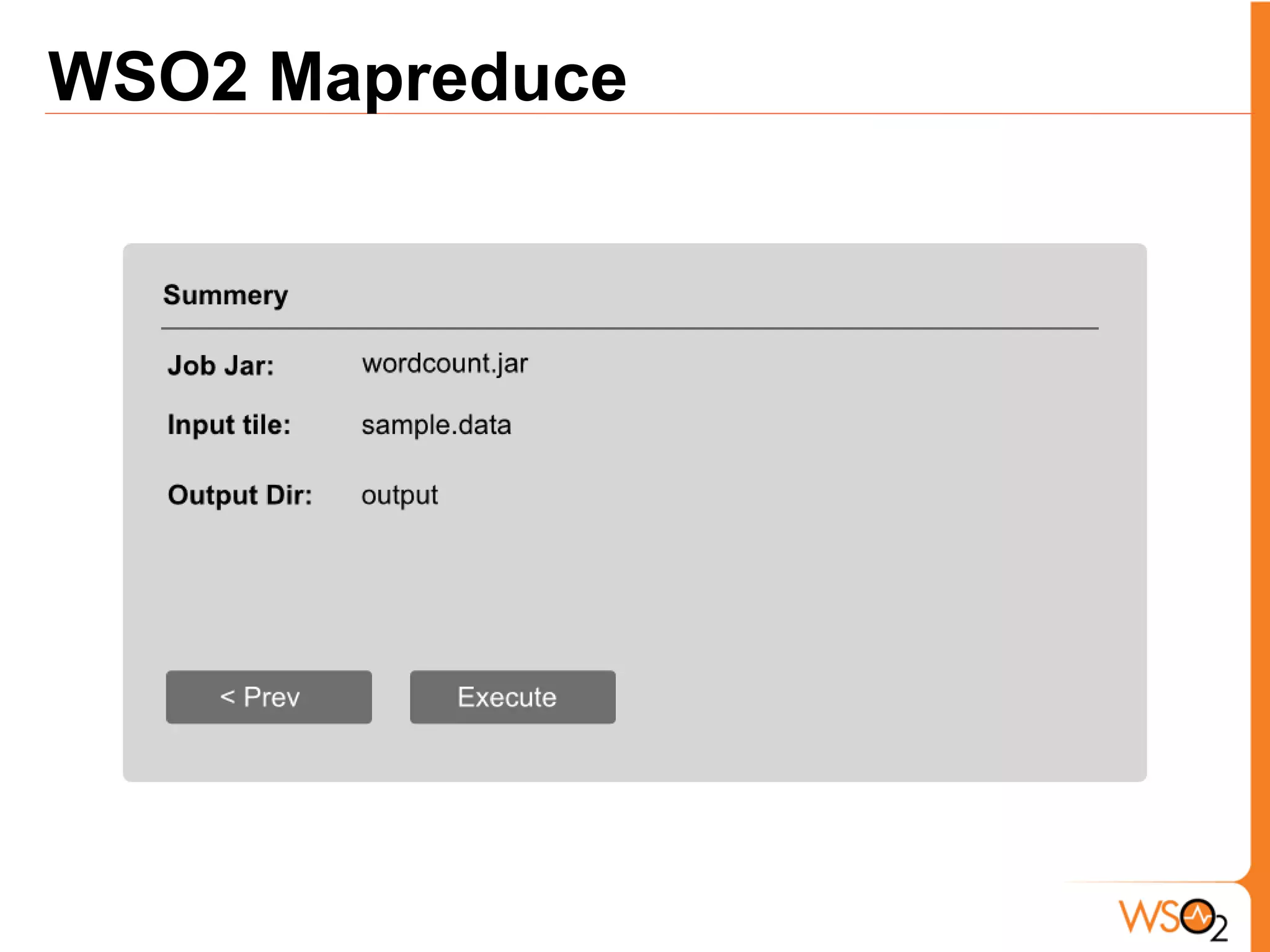






The document discusses data storage and processing challenges posed by large amounts of data, and different solutions for structuring and scaling data, including: 1) Relational databases face scaling issues, while NoSQL databases like key-value and column-family stores are more scalable. 2) The type of data determines the best solution - for example, using graph databases for relationship data and distributed file systems for unstructured data. 3) Highly scalable systems require loosening consistency requirements and cannot support transactions or joins across thousands of nodes according to the CAP theorem. Hybrid approaches may be needed for complex data needs.
























































![[Roundtable] Choreo - The AI-Native Internal Developer Platform as a Service](https://cdn.slidesharecdn.com/ss_thumbnails/choreo-deck-250328074645-511dded7-thumbnail.jpg?width=640&height=640&fit=bounds)






























