Download as PDF, PPTX


















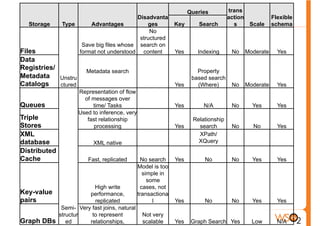




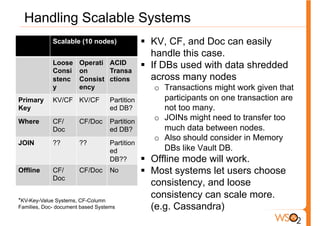




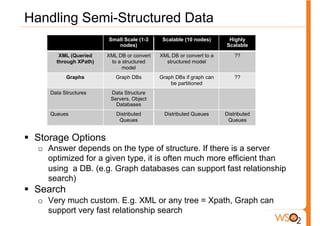






The document discusses the evolution of data storage solutions from traditional relational database management systems (RDBMS) to NoSQL alternatives, highlighting the challenges in scalability and transaction management with increasing system demands. It categorizes data into structured, semi-structured, and unstructured types and outlines key considerations for selecting appropriate data storage solutions based on scalability, consistency, and query requirements. The conclusion emphasizes that while traditional databases were once the standard, evolving needs necessitate careful selection from various data solutions, taking into account the specific requirements of applications.



































































