Download as PDF, PPTX













![MongoDB is a document oriented DB
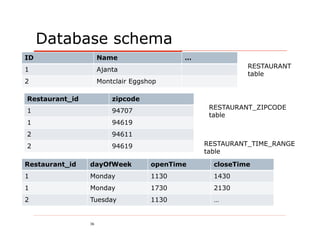
Server
Database: Food To Go
Collection: Restaurants
{
"_id" : ObjectId("4bddc2f49d1505567c6220a0")
"name": "Ajanta",
"serviceArea": ["94619", "99999"], BSON =
"openingHours": [
{
binary
"dayOfWeek": 1, JSON
"open": 1130,
"close": 1430 },
{ Sequence
"dayOfWeek": 2,
"open": 1130,
of bytes on
"close": 1430 disk fast
}, …
]
i/o
}
16](https://image.slidesharecdn.com/polygotpersistenceforjavadevsphillyete2012-pptx-shrunk-120412114147-phpapp02/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-PhillyETE-2012-16-320.jpg)
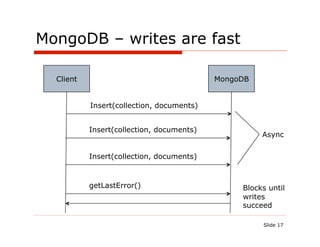










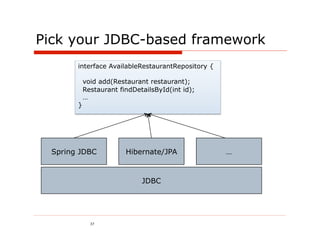

![MongoDB: persisting restaurants is easy
{
"_id" : ObjectId("4bddc2f49d1505567c6220a0")
"name": "Ajanta",
"serviceArea": ["94619", "99999"],
"openingHours": [
{
"dayOfWeek": 1,
"open": 1130,
"close": 1430 },
{
"dayOfWeek": 2,
"open": 1130,
"close": 1430
}, …
]
}
40](https://image.slidesharecdn.com/polygotpersistenceforjavadevsphillyete2012-pptx-shrunk-120412114147-phpapp02/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-PhillyETE-2012-40-320.jpg)



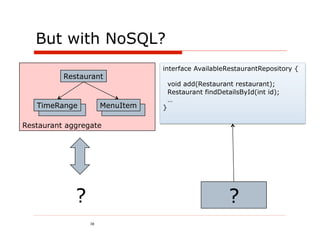
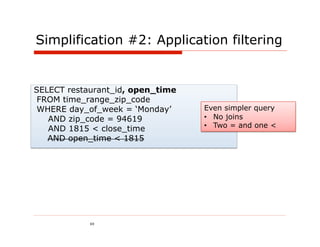
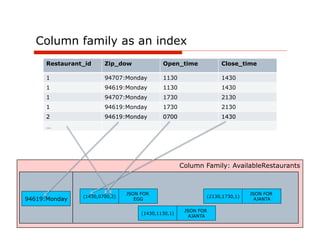
![Option #1: Use a column per attribute
Column Name = path/expression to access property value
Column Family: RestaurantDetails
openingHours[0].dayOfWeek Monday
name Ajanta serviceArea[0] 94619
1 openingHours[0].open 1130
type indian serviceArea[1] 94707
openingHours[0].close 1430
Egg openingHours[0].dayOfWeek Monday
name serviceArea[0] 94611
shop
2 Break openingHours[0].open 0830
type serviceArea[1] 94619
Fast
openingHours[0].close 1430](https://image.slidesharecdn.com/polygotpersistenceforjavadevsphillyete2012-pptx-shrunk-120412114147-phpapp02/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-PhillyETE-2012-44-320.jpg)
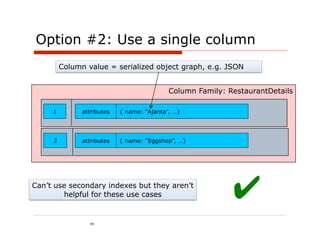




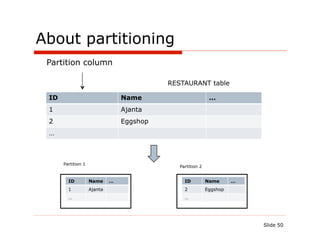
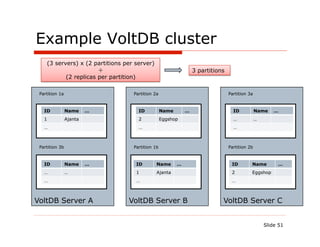
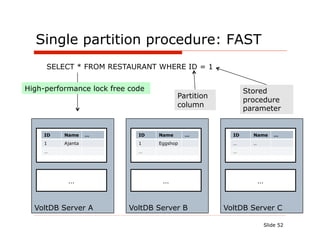
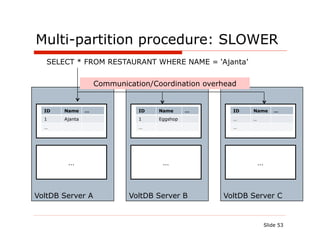

![Stored procedure – AddRestaurant
@ProcInfo( singlePartition = true, partitionInfo = "Restaurant.id: 0”)
public class AddRestaurant extends VoltProcedure {
public final SQLStmt insertRestaurant =
new SQLStmt("INSERT INTO Restaurant VALUES (?,?);");
public final SQLStmt insertServiceArea =
new SQLStmt("INSERT INTO service_area VALUES (?,?);");
public final SQLStmt insertOpeningTimes =
new SQLStmt("INSERT INTO time_range VALUES (?,?,?,?);");
public final SQLStmt insertMenuItem =
new SQLStmt("INSERT INTO menu_item VALUES (?,?,?);");
public long run(int id, String name, String[] serviceArea, long[] daysOfWeek, long[] openingTimes,
long[] closingTimes, String[] names, double[] prices) {
voltQueueSQL(insertRestaurant, id, name);
for (String zipCode : serviceArea)
voltQueueSQL(insertServiceArea, id, zipCode);
for (int i = 0; i < daysOfWeek.length ; i++)
voltQueueSQL(insertOpeningTimes, id, daysOfWeek[i], openingTimes[i], closingTimes[i]);
for (int i = 0; i < names.length ; i++)
voltQueueSQL(insertMenuItem, id, names[i], prices[i]);
voltExecuteSQL(true);
return 0;
}
}
55](https://image.slidesharecdn.com/polygotpersistenceforjavadevsphillyete2012-pptx-shrunk-120412114147-phpapp02/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-PhillyETE-2012-55-320.jpg)
![VoltDb repository – add()
@Repository
public class AvailableRestaurantRepositoryVoltdbImpl
implements AvailableRestaurantRepository {
@Autowired
private VoltDbTemplate voltDbTemplate;
@Override
public void add(Restaurant restaurant) {
invokeRestaurantProcedure("AddRestaurant", restaurant);
}
private void invokeRestaurantProcedure(String procedureName, Restaurant restaurant) {
Object[] serviceArea = restaurant.getServiceArea().toArray();
long[][] openingHours = toArray(restaurant.getOpeningHours()); Flatten
Object[][] menuItems = toArray(restaurant.getMenuItems());
Restaurant
voltDbTemplate.update(procedureName, restaurant.getId(), restaurant.getName(),
serviceArea, openingHours[0], openingHours[1],
openingHours[2], menuItems[0], menuItems[1]);
}
56](https://image.slidesharecdn.com/polygotpersistenceforjavadevsphillyete2012-pptx-shrunk-120412114147-phpapp02/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-PhillyETE-2012-56-320.jpg)




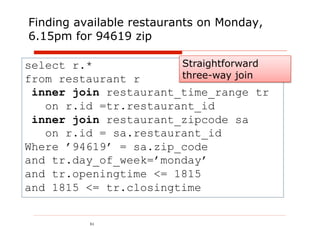






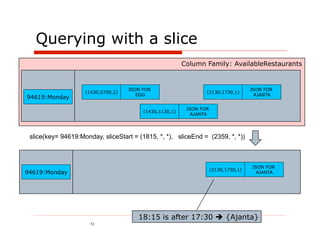





![VoltDB - attempt #1
@ProcInfo( singlePartition = false)
public class FindAvailableRestaurants extends VoltProcedure { ... }
create index idx_service_area_zip_code on service_area(zip_code);
..
ERROR 10:12:03,251 [main] COMPILER: Failed to plan for statement
type(findAvailableRestaurants_with_join) select r.* from restaurant
r,time_range tr, service_area sa Where ? = sa.zip_code and
sa.restaurant_id= tr.restaurant_id and r.restaurant_id =
sa.restaurant_id and tr.day_of_week=? and tr.open_time <= ? and ?
<= tr.close_time Error: "Unable to plan for statement. Possibly joining
partitioned tables in a multi-partition procedure using a column that is
not the partitioning attribute or a non-equality operator. This is
statement not supported at this time."
2012-03-19 08:19:31,743 ERROR [main] COMPILER: Catalog
compilation failed.
#fail
Slide 78](https://image.slidesharecdn.com/polygotpersistenceforjavadevsphillyete2012-pptx-shrunk-120412114147-phpapp02/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-PhillyETE-2012-78-320.jpg)
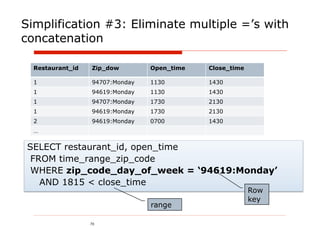
![VoltDB - attempt #2
@ProcInfo( singlePartition = true, partitionInfo = "Restaurant.id: 0”)
public class AddRestaurant extends VoltProcedure {
public final SQLStmt insertAvailable=
new SQLStmt("INSERT INTO available_time_range VALUES (?,?,?, ?, ?, ?);");
public long run(....) {
...
for (int i = 0; i < daysOfWeek.length ; i++) {
voltQueueSQL(insertOpeningTimes, id, daysOfWeek[i], openingTimes[i], closingTimes[i]);
for (String zipCode : serviceArea) {
voltQueueSQL(insertAvailable, id, daysOfWeek[i], openingTimes[i],
closingTimes[i], zipCode, name);
}
}
... public final SQLStmt findAvailableRestaurants_denorm = new SQLStmt(
voltExecuteSQL(true); "select restaurant_id, name from available_time_range tr " +
return 0; "where ? = tr.zip_code " +
} "and tr.day_of_week=? " +
} "and tr.open_time <= ? " +
" and ? <= tr.close_time ");
Works but queries are only slightly
faster than MySQL!
Slide 79](https://image.slidesharecdn.com/polygotpersistenceforjavadevsphillyete2012-pptx-shrunk-120412114147-phpapp02/85/SQL-NoSQL-NewSQL-What-s-a-Java-developer-to-do-PhillyETE-2012-79-320.jpg)



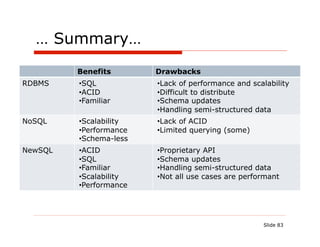



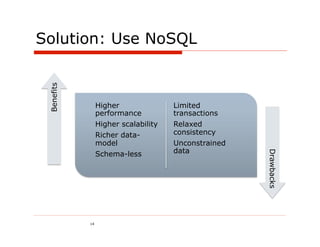
The document discusses the challenges and solutions associated with using NoSQL and NewSQL databases for Java applications, highlighting their benefits over traditional relational databases, particularly regarding scalability and performance. It details specific NoSQL databases like MongoDB and Cassandra, outlining their use cases, advantages, and implementations. Additionally, it introduces NewSQL as an option that combines relational database features with improved scalability through innovative architectures.























































































