Download as PDF, PPTX

















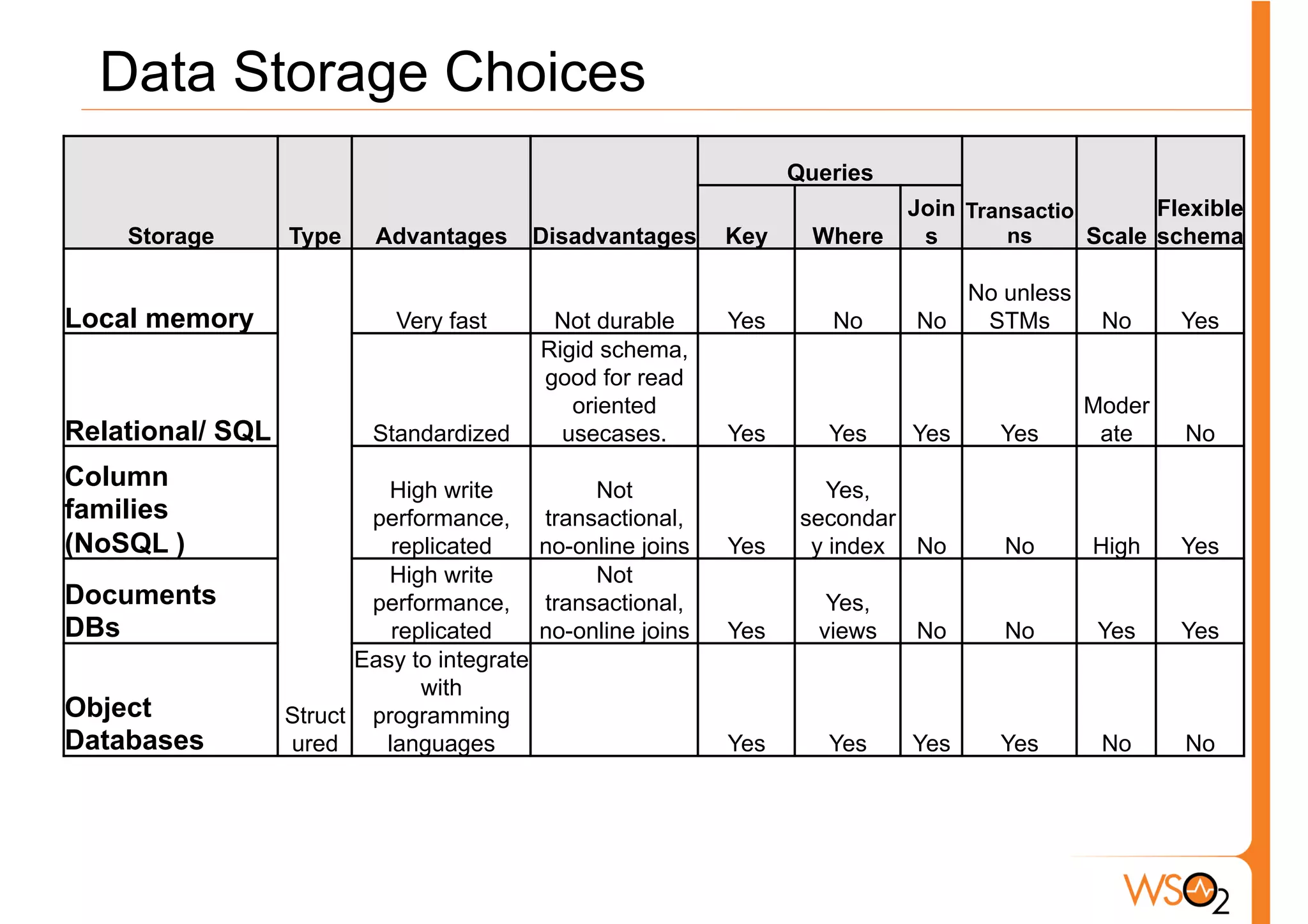
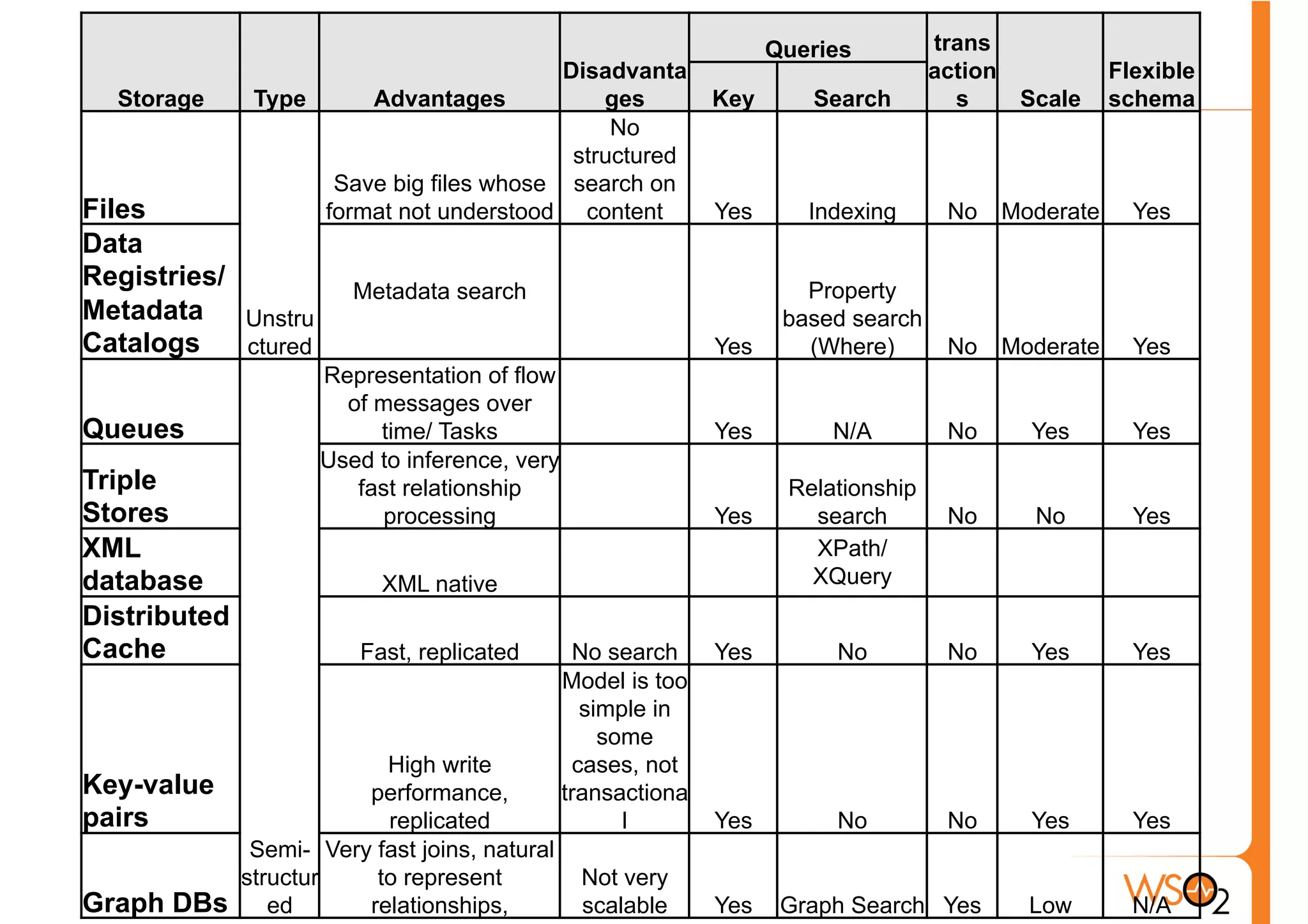


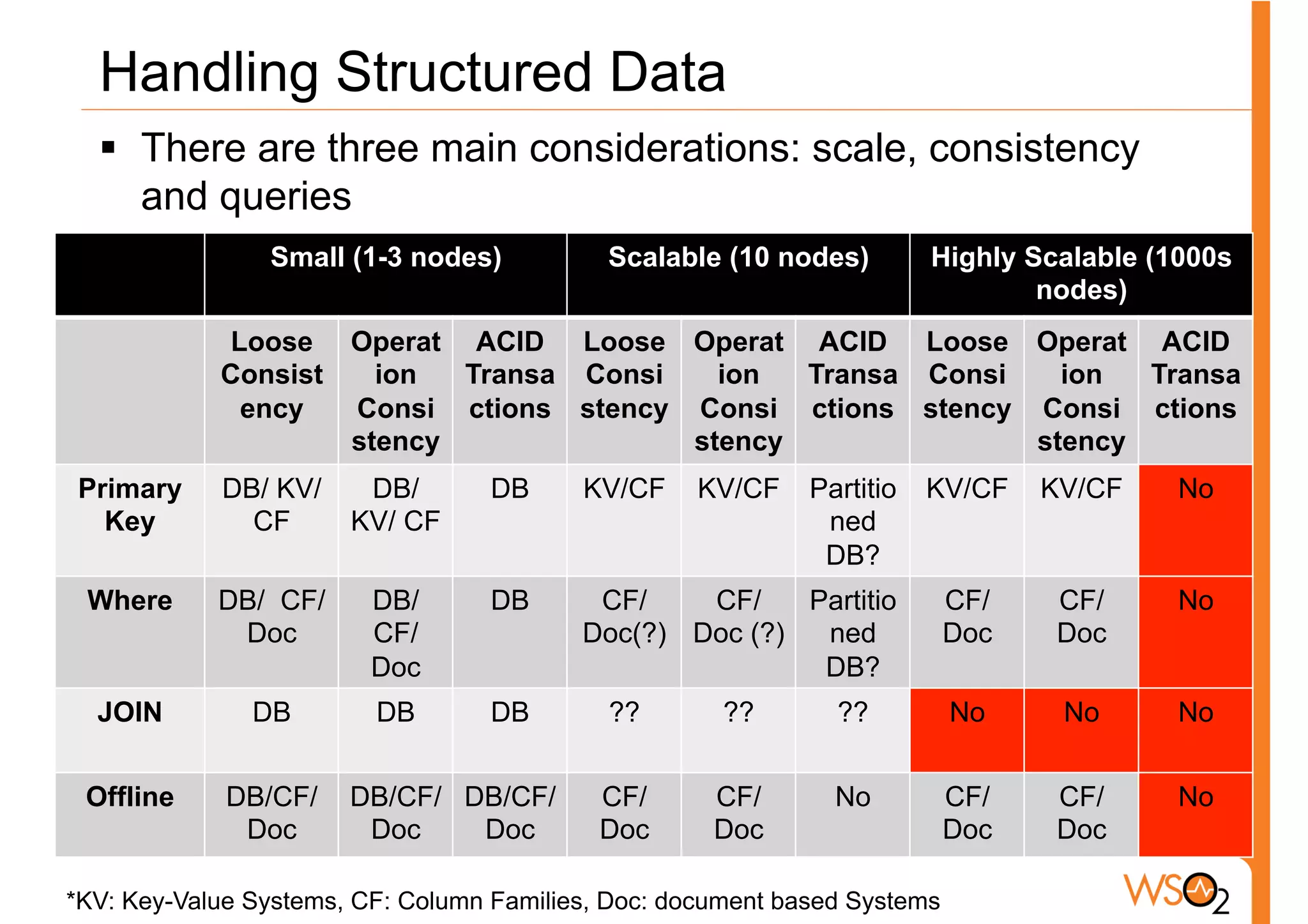

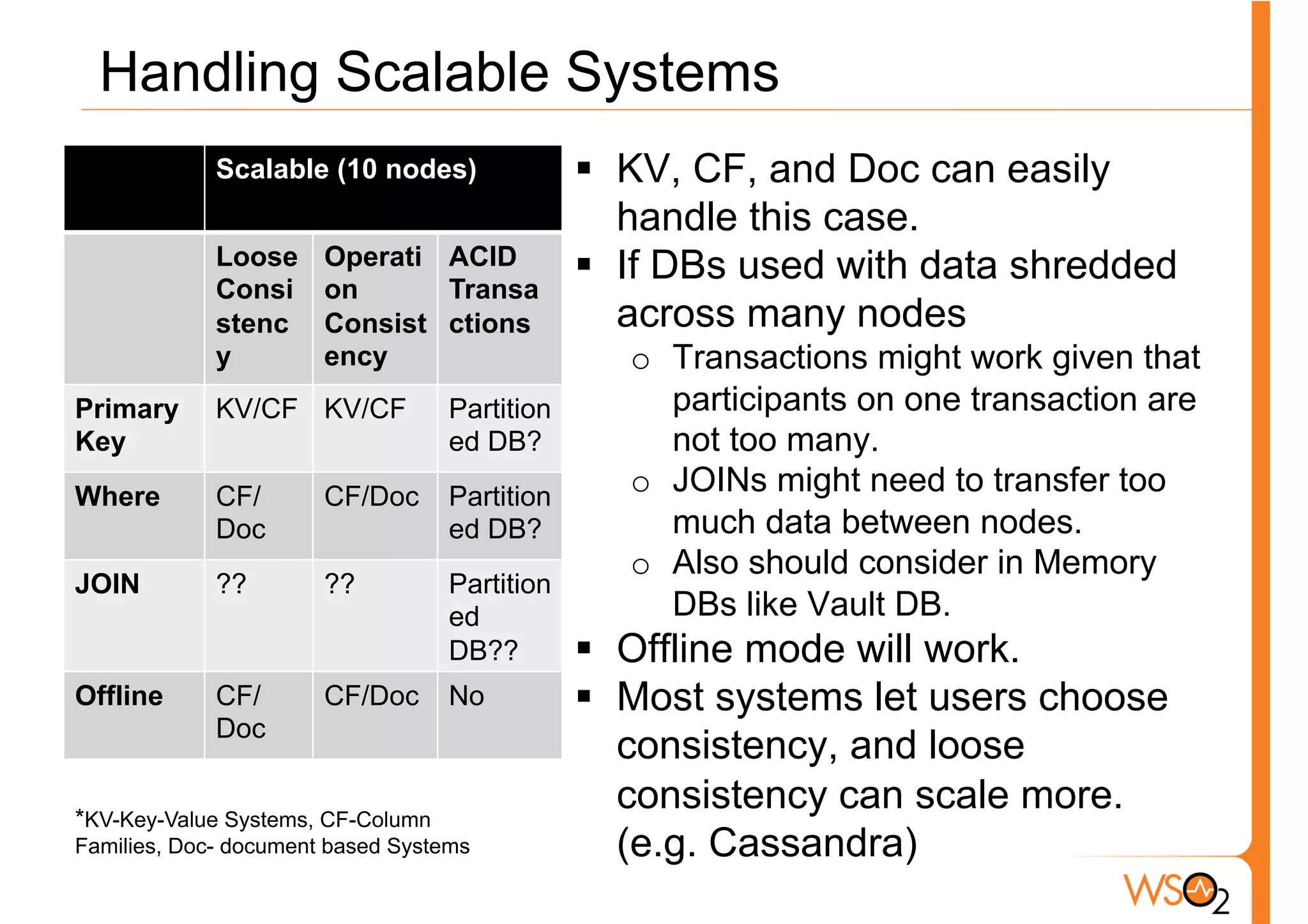

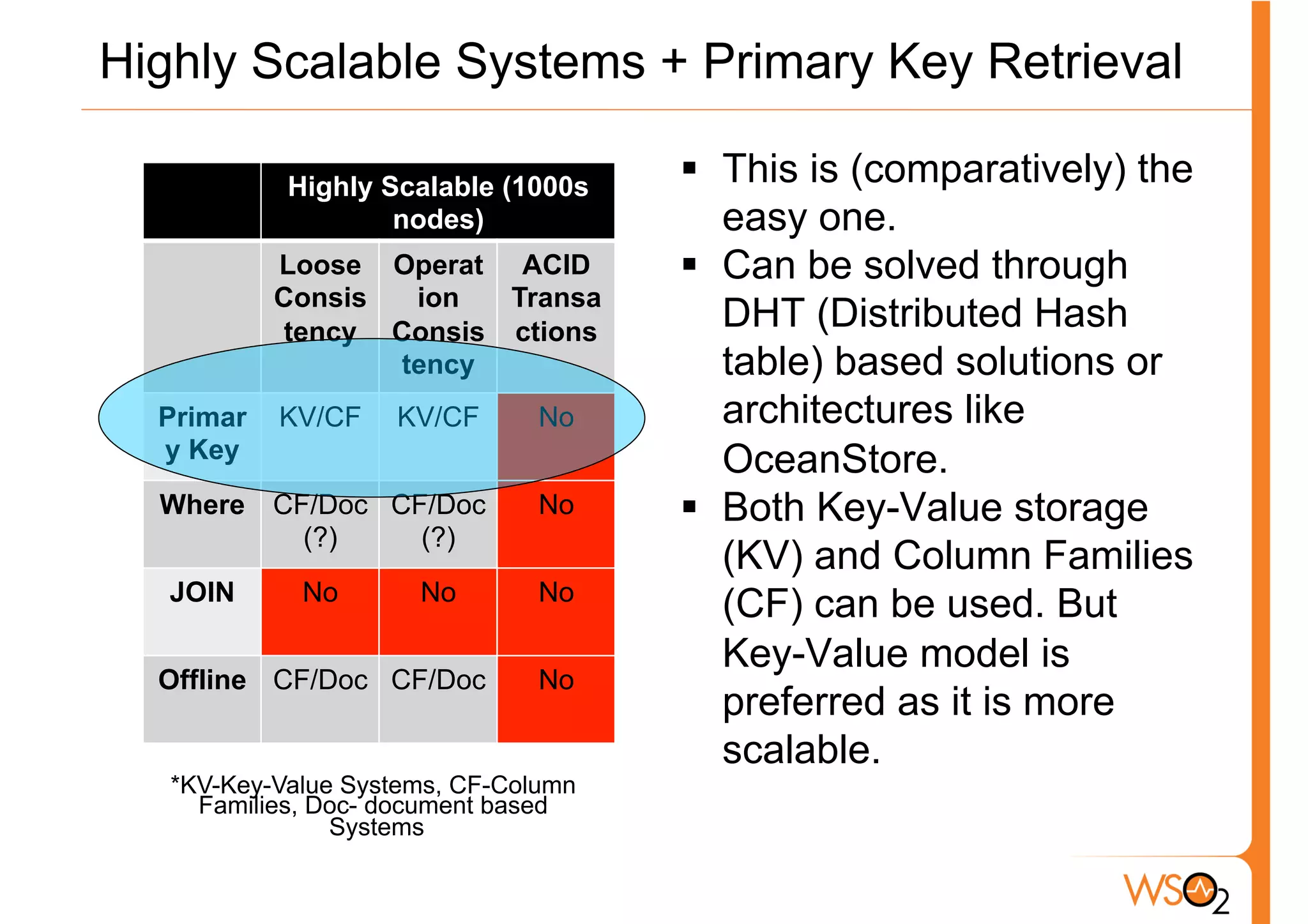

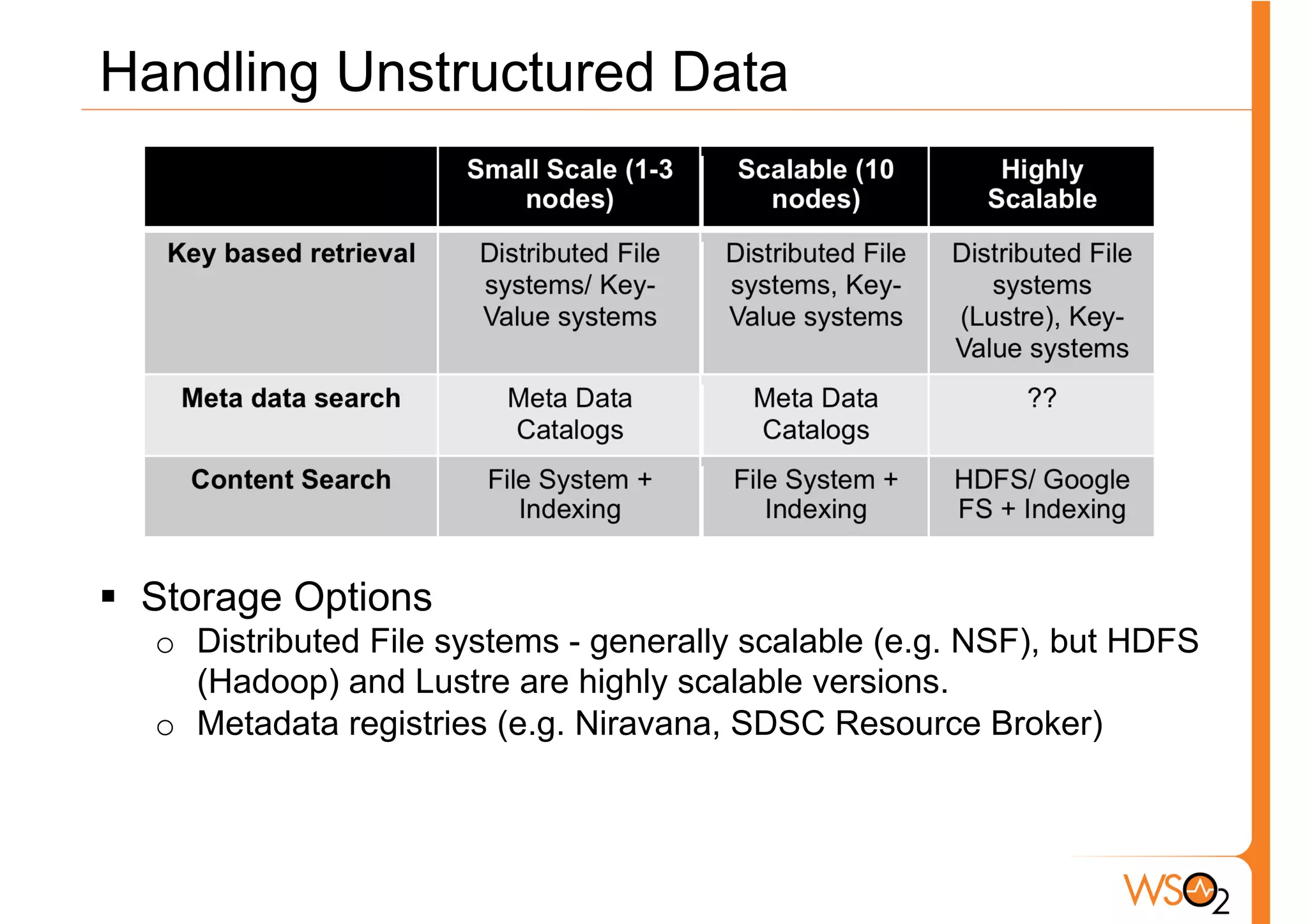





The document discusses the evolution of data storage solutions, highlighting the historical dominance of relational databases and their limitations in scaling due to changing system demands such as increased user bases and cloud computing. It introduces NoSQL and other storage systems that offer better scalability, flexible schemas, and fault tolerance, while also emphasizing the complexity of choosing the right data solution based on specific use cases and requirements. Key considerations for selecting a data solution include data types, scalability needs, query types, and consistency requirements.













































































