Dokumen tersebut membahas tentang pengukuran dispersi data, termasuk pengertian dan rumus varians, standar deviasi, koefisien variasi, kemencengan, dan contoh-contoh perhitungannya."
Buku Teks
2
Lind, Marchal and Wathen, 2005, Statistical
Techniques in Business & Economics, 12th Ed.,
McGraw Hill, Irwin.
3.
Pengukuran Dispersi
3
Mengapa perlu mempelajari Dispersi?
Pengukuran Range, Deviasi Rata-rata, Varians dan
Standar Deviasi, dan Koefisien Variasi
Pengukuran Kemencengan (Skewness)
Pengukuran Kurtosis (Peakedness)
Pengukuran Kuartil, Desil, dan Persentil
4.
Mengapa perlu mempelajariDispersi?
4
Pengukuran nilai sentral (e.g. mean, modus, median)
hanya menjelaskan pusat data, tidak menjelaskan sebaran
data.
Dispersi dapat dipergunakan untuk membandingkan
sebaran pada dua distribusi data atau lebih.
5.
Pengukuran Range (Rentang/Jangkauan)
5
Range (Rentang/ Jangkauan) adalah perbedaan antara
terbesar dan nilai terkecil.
Range = H - L
Hanya dua nilai yang digunakan dalam perhitungan.
Sangat dipengaruhi oleh nilai ekstrem.
Mudah untuk dihitung dan dimengerti.
6.
Deviasi Rata-rata (MeanDeviation)
Deviasi Rata-Rata (Mean Deviation) adalah rata-rata
arimatik/hitung dari nilai absolut deviasi terhadap nilai
rata-rata aritmatik/hitung.
Semua nilai yang digunakan dalam perhitungan.
Tidak terlalu banyak dipengaruhi oleh nilai-nilai yang
besar atau kecil.
Nilai absolut sulit untuk dimanipulasi.
Σ X- X
n
MD=
Mean deviation juga disebut Mean Absolute Deviation (MAD).
7.
Contoh 1
7
Berat sampel peti-peti berisi buku untuk toko buku
(dalam Kg) adalah:
103, 97, 101, 106, 103
Tentukan rentang dan deviasi rata-rata-nya.
Range = 106 – 97 = 9
8.
Contoh 1
8
Langkah pertama adalah menentukan rata-rata berat
kotak tsb:
510
5 = 102
ΣX
n =
X=
Deviasi rata-rata-nya adalah:
Σ X - X 12 MD= = = 2.4
n 5
x |x-xbar|
103 1
97 5
101 1
106 4
103 1
510 12
9.
Varians & StandarDeviasi
9
Varians adalah rata-rata aritmatik/hitung dari kuadrat
deviasi rata-rata.
Standar Deviasi adalah akar kuadrat dari Varians.
10.
Varians Populasi
10
Varians populasi adalah rata-rata aritmetik/hitung dari
kuadrat deviasi terhadap rata-rata populasi.
Semua nilai yang digunakan dalam perhitungan.
Lebih cenderung dipengaruhi oleh nilai-nilai ekstrim
dibandingkan dengan deviasi rata-rata.
11.
Varians
11
Rumusuntuk Varians Populasi adalah:
σ = Σ(X- μ)
N
2
2
Rumus untuk Varians Sampel adalah:
Σ(X- X)
n -1
s =
2
2
Catatan dalam rumus varians sampel jumlah deviasi dibagi oleh (n-1)
bukan n. Walaupun secara logis seharusnya menggunakan n bukan (n-1),
pembagian dengan (n-1) menghasilkan estimator yang tidak bias terhadap
varians populasi, sedangkan pembagian menggunakan n menghasilkan
estimator yang bias.
12.
Untuk memudahkan hitunganmanual:
12
( ) ( )
( )
å å
- = å -
å
( )
2
2 2
2
2
2
å å
2
2
-
1
1
X
X X X
n
X X
s
n
X
X
s n
n
=
-
-
=
-
13.
Contoh 2
13
Usia masing-masing anggota keluarga Pak Arman adalah
sbb:
2, 18, 34, 42
Berapa varians populasi-nya?
96
4 = 24
ΣX
n =
μ =
2
σ2 = Σ(X- μ) = 944 = 236
N 4
x x- μ (x- μ)2
2 -22 484
18 -6 36
34 -10 100
42 18 324
Σ=96 Σ=944
14.
Standar Deviasi Populasi
14
Standar Deviasi populasi (σ) adalah akar kuadrat dari
varians populasi.
Untuk Contoh 2, Standar Deviasi populasi-nya adalah
15.36, diperoleh dari:
σ = σ2 = 236 = 15.36
15.
Contoh 3 Untuk data Sampel
15
Upah per jam yang diperoleh dari sampel lima pekerja
adalah:
$7, $5, $11, $8, $6.
Hitunglah varians dari data tsb.
37
5 = 7.40
ΣX
n =
X=
x x- x bar (x- x bar)2
7 -0.4 0.16
5 -2.4 5.76
11 3.6 12.96
8 0.6 0.36
6 -1.4 1.96
Σ=37 Σ=21.2
( )2
2 Σ X- X 21.2 s = = = 5.30
n-1 5-1
16.
Standar Deviasi Sample
16
Standar deviasi sampel adalah akar kuadrat dari varians
sampel.
In Contoh 3, standar deviasi sample adalah 2.30
s = s2 = 5.29 = 2.30
17.
Variance
UngroupedData
• Population
• Sample
Grouped Data
• Population
Sample
( )
2
m
( )
2
2
2
2
X
N
X
X
N
N
s
s
-
=
-
=
å
å å
( X X
)
=
å å
( )
1
-
1
2
2
2
2
2
-
-
=
-
å
n
X
n
X
s
n
s
( )
2
m
( )
2
2
2
2
f X
N
fX
fX
N
N
s
s
-
=
-
=
å
å å
( )
f X -
X
=
å å
( )
1
1
2
2
2
2
2
-
-
=
-
å
n
fX
n
fX
s
n
s
18.
Standard Deviation
Ungrouped Data
• Population
• Sample
Grouped Data
• Population
Sample
( )
2
m
( ) ( )
2
2
X
N
X
X
N
N
s
s
-
=
-
=
å
å å
( )
2
i f X
m
( ) ( )
2
2
N
fX
fX
N
N
s
s
-
=
-
=
å
å å
( )
X -
X
( )
s =
å å
( ) ( )
1
1
2
2
2
-
-
=
-
å
n
X
n
X
s
n
f X -
X
=
å å
( ) ( )
1
1
2
2
2
-
-
=
-
å
n
fX
n
fX
s
n
s
19.
Sebuah sampelyang
terdiri dari sepuluh
bioskop di Surabaya
dihitung jumlah film
yang diputar minggu lalu.
Hitunglah varian dan
standar deviasinya.
Jumlah
film yang
diputar
frequency
f
1 up to 3 1
3 up to 5 2
5 up to 7 3
7 up to 9 1
9 up to 11 3
Total 10
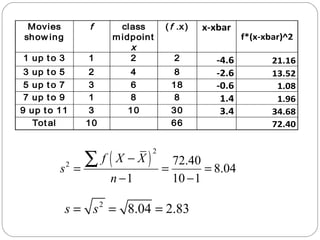
20.
Movies
showing
fclass
midpoint
x
(f .x) x-xbar
f*(x-xbar)^2
1 up t o 3 1 2 2 -4.6 21.16
3 up t o 5 2 4 8 -2.6 13.52
5 up t o 7 3 6 18 -0.6 1.08
7 up t o 9 1 8 8 1.4 1.96
9 up to 11 3 10 30 3.4 34.68
Total 10 66 72.40
( )2
f X X
2 72.40 8.04
1 10 1
s
n
-
= = =
- -
å
s = s2 = 8.04 = 2.83
21.
Interpretasi dan PenggunaanStandar
Deviasi
21
Teorema Chebyshev : untuk setiap kelompok
pengamatan (baik sampel maupun populasi), proporsi
minimum nilai-nilai yang terletak dalam standar deviasi
rata-rata k sekurang-kurangnya adalah:
1- 1
k2
dimana k2 adalah konstanta yang lebih besar dari 1.
22.
Contoh:
Rata-rata hitungharga sepatu Nike adalah $51.54 dengan standar
deviasi $7.51. Setidaknya berapa persen harga yang berada antara
plus 3.5 standar deviasi dan minus 3.5 standar deviasi dari rata-rata?
Sekitar 92%
1 0.92
1- 1 1- 1
= = = 2 2
(3.5) 12.25
k
23.
Teorema Chebyshev
TeoremaChebyshev: Untuk semua jenis pengamatan, proposi
minimum nilai yang terletak dalam kisaran standar deviasi rata-rata
k sekurang-kurangnya adalah 1- 1/k2
K Coverage
1 0%
2 75.00%
3 88.89%
4 93.75%
5 96.00%
6 97.22%
Ingat: semakin kecil standar deviasi, menunjukkan bahwa pengamatan berada
didekat rata-rata, vice versa.
24.
Interpretasi dan PenggunaanStandar
Deviasi
24
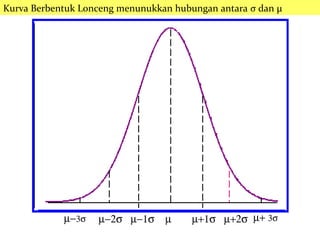
Aturan Empiris: Untuk setiap distribusi yang simetris &
berbentuk lonceng (bell-shaped) :
Sekitar 68% observasi akan berada pada plus dan minus 1 standar
deviasi rata-rata,
Sekitar 95% observasi akan berada pada plus dan minus 2 standar
deviasi rata-rata,
Dalam prakteknya, hampir semua observasi berada dalam plus
dan minus 3 standar deviasi rata-rata.
Aturan Empiris juga disebut sebagai Aturan normal.
25.
Kurva Berbentuk Loncengmenunukkan hubungan antara σ dan μ
25
m-3s m-2s m-1s m m+1s m+2s m+ 3s
26.
Mengapa perlu memperhatikandispersi?
26
Dispersi dipergunakan sebagai salah satu ukuran risiko.
Bandingkan dua aset dengan rata-rata expected return
yang sama:
-2%, 0%,+2%
-4%, 0%,+4%
Dispersi return aset kedua lebih besar dibandingkan
yang pertama. Dengan demikian, aset kedua yang lebih
berisiko.
Hal ini menunjukkan bahwa dispersi sangat penting
untuk keputusan investasi, disamping informasi rata-rata
expected return .
27.
Dispersi Relatif
KoefisienVariasi adalah rasio dari standar deviasi terhadap rata-rata
aritmatik, dinyatakan dalam persentase:
CV=
CV: coefficient of variation
s: standar deviasi
x-bar: rata-rata
s
(100%)
X
Berguna untuk membandingkan dua atau lebih distribusi yang:
Datanya memiliki satuan /unit yang berbeda (misalnya: hari dan Rupiah)
Datanya memiliki satuan / unit yang sama, tetapi rata-ratanya sangat jauh
berbeda (misal: gaji direktur dengan gaji buruh kasar)
28.
Contoh
28
Sebuahstudi tentang bonus dan lama bekerja menghasilkan informasi statistik
sebagai berikut:
Rata-rata bonus: $200, standar deviasi bonus: $40
Rata-rata lama bekerja: 20 tahun, standar deviasi: 2 tahun
Bandingkan kedua distribusi tersebut (ingat masing-masing memiliki satuan yang
berbeda)
Digunakan koefisien variasi:
CV= s (100%) = (100%) = 20%
40
200
Untuk Bonus:
X
Untuk lama bekerja
Dispersi untuk bonus lebih besar dibanding rata-ratanya.
CV= s (100%) = (100%) = 10%
2
20
X
29.
Skewness (Kemencengan/ asimetris)
a3
Skewness (Kemencengan/ asimetris) adalah pengukuran dari
kurangnya simetri pada distribusi.
Koefisien skewness (kemencengan) dapat berkisar dari -3,00
(asimetris negatif) sampai 3,00 (asimetris positif).
Nilai 0 menunjukkan distribusi yang simetris.
Koefisien Kemencengan ini dihitung sebagai berikut:
Pearson:
Software:
3(x -median)
S
sk =
ù
ú ú
û
é
ê ê
ë
ö
÷ ÷ø
æ - å
ç çè
3
x x
s
sk = n
(n -1)(n - 2)
Cont..
Relative skewness:
Ungrouped data :
Grouped data :
nåX -X
nåf X -X
Karl Pearson : a3 ³ ± 0,5
Kenny & Keeping :
-2 £ a3 £ 2 (moderately skewed)
a3 ³ ± 2 (significantly skewed)
( )
3
3
3
1
s
a =
( )
3
3
3
1
s
a =
33.
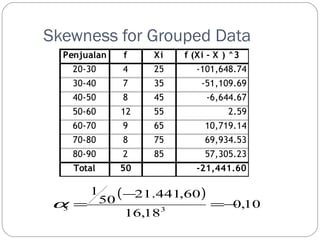
Skewness for GroupedData
Penjualan f Xi f (Xi - X ) ^3
20-30 4 25 -101,648.74
30-40 7 35 -51,109.69
40-50 8 45 -6,644.67
50-60 12 55 2.59
60-70 9 65 10,719.14
70-80 8 75 69,934.53
80-90 2 85 57,305.23
Total 50 -21,441.60
( )
0,10
-
50 21.441,60
16,18
1
a =
3 3 =-
35.
Kurtosis (Peakedness)
Kurtosis
Ukuran ketinggian distribusi frekuensi
Platykurtic (relatif datar dan menyebar)
Mesokurtic (normal)
Leptokurtic (tinggi dan tipis)
36.
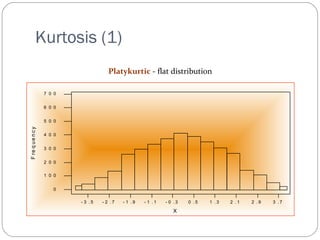
Kurtosis (1)
-3 . 5 - 2 . 7 - 1 . 9 - 1 . 1 - 0 . 3 0 . 5 1 . 3 2 . 1 2 . 9 3 . 7
7 0 0
6 0 0
5 0 0
4 0 0
3 0 0
2 0 0
1 0 0
0
X
F re q ue n c y
Platykurtic - flat distribution
37.
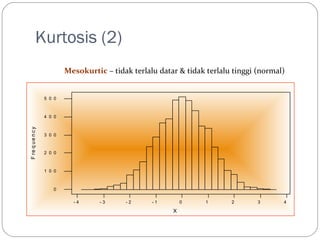
Kurtosis (2)
-4 - 3 - 2 - 1 0 1 2 3 4
5 0 0
4 0 0
3 0 0
2 0 0
1 0 0
0
X
F re q ue n c y
Mesokurtic – tidak terlalu datar tidak terlalu tinggi (normal)
38.
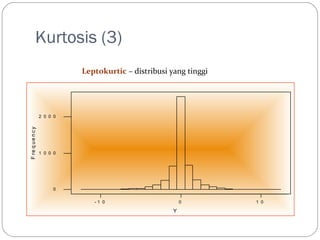
Kurtosis (3)
Leptokurtic– distribusi yang tinggi
- 1 0 0 1 0
2 0 0 0
1 0 0 0
0
Y
F re q ue n c y
39.
Kurtosis (Peakedness)
Formula:
Ungrouped data :
Grouped data :
nåX -X
Nåf X -X
Note :
a4 = 3 normal/mesokurtic
a4 = 3 leptokurtic
a4 = 3 platykurtic
( )
4
4
4
1
s
a =
( )
4
4
4
1
s
a =
40.
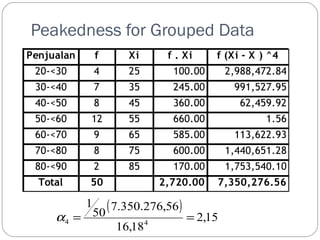
Peakedness for GroupedData
Penjualan f Xi f . Xi f (Xi - X ) ^4
20-30 4 25 100.00 2,988,472.84
30-40 7 35 245.00 991,527.95
40-50 8 45 360.00 62,459.92
50-60 12 55 660.00 1.56
60-70 9 65 585.00 113,622.93
70-80 8 75 600.00 1,440,651.28
80-90 2 85 170.00 1,753,540.10
Total 50 2,720.00 7,350,276.56
( )
2,15
50 7.350.276,56
16,18
1
4 4 a = =
41.
Kuartil, Desil, danPersentil
42
Fraktil adalah nilai-nilai data yang membagi seperangkat data yang telah
terurut menjadi beberapa bagian yang sama.
Kuartil: membagi sekelompok observasi/ pengamatan yang
telah diurutkan dari kecil ke besar menjadi 4 bagian yang
sama.
(Q1: 25%, Q2: 50%, Q3: 75%)
Desil: membagi sekelompok observasi/ pengamatan yang
telah diurutkan dari kecil ke besar menjadi 10 bagian yang
sama.
Persentil: membagi sekelompok observasi/ pengamatan yang
telah diurutkan dari kecil ke besar menjadi 100 bagian yang
sama.
42.
Lokasi Persentil
43
Lokasi persentil dapat ditentukan dengan rumus sbb:
L = (n 1) P p +
100
Lp : Lokasi persentil yang dicari
n : jumlah pengamatan
P: Persentil yang dicari
43.
Contoh 5
44
Quality Control pabrik selai kacang DK mencatat data
berat 9 botol selai yang diproduksi dalam satu jam
terakhir:
7,69 7,72 7,8 7,86 7,90 7,94 7,97 8,06 8,09
Tentukan Kuartil pertama.
Tentukan Persentil ke-67.
44.
Contoh 5 continued
45
7,69 7,72 7,8 7,86 7,90 7,94 7,97 8,06 8,09
Kuartil pertama:
2.5
L = (9 1) 25 25 + =
100
Kuartil pertama berada pada urutan ke-2.5 (antara data ke-2 dan ke-3):
7,72 + [(7,8-7,72)*0.5)= 7,72 + 0.04 = 7.76
Persentil ke-67:
L = (9 1) 67 6.70
67 + =
100
Persentil ke-67 berada pada urutan ke-6.70 (antara ke-6 ke-7):
7,94 + [(7.97-7,94)*0.7]= 7.94 + 0.02 = 7.96
45.
Untuk data yangdikelompokkan, urutan:
1. Susun Distribusi Frekuensi Kumulatif
2. Tentukan Lokasi Persentil:
Lokasi Persentil Lp = n . P .
100
3. Gunakan formula sbb:
Persentil : P = L + ( n. P/100 - CF) . i
fp
Pi = Persentil ke-i.
L = Batas bawah kelas persentil
n = Jumlah frekuensi.
CF = Frekuensi kumulatif sebelum kelas Persentil
f = Frekuensi kelas persentil
i = Interval kelas
46.
Contoh
Tentukan Kuartilpertama (P25) dari data berikut:
Lokasi Persentil: 10*25/100= 2.5 kelas 3-5
P25 = 3 + [(2.5 – 1)/2] * 2
= 4.5
Jumlah film
yg diputar
Frekuensi Frekuensi
Kumulat if
1 up to 3 1 1
3 up to 5 2 3
5 up to 7 3 6
7 up to 9 1 7
9 up to 11 3 10
47.
Jangkauan (Rentang) Interkuartil
48
Rentang interkuartil adalah jarak antara kuartil ketiga
Q3 dan kuartil pertama Q1.
Rentang ini akan mencakup nilai tengah 50 persen dari
pengamatan.
Rentang Interkuartil= Q3 - Q1
48.
Contoh 6
49
Untuk sekelompok observasi, Q3 adalah 24 dan Q1
adalah 10. Berapa rentang kuartilnya?
Rentang interkuartil: 24 - 10 = 14. Lima puluh persen
dari observasi berada antara 10 dan 24.
49.
Others Dispersion
QuartileDeviation :
d = -
Coefficient of Quartile Variation :
3 1 Q Q
2
Q
( Q Q
)
V 2 3 1 -
d
=
Q M
V = Q -
Q Q +
3 1
Q Q
3 1
50.
Data ekstrim (outliers)
51
Data ekstrim: nilai yang tidak konsisten dengan keseluruhan
data. Yakni data yang lebih besar dari 1,5 jangkauan
interkuartil (Q3-Q1) dan lebih kecil dari Q1 atau lebih besar
dari Q3.
Outlier (Ekstrim) kecil:
x Q1 – 1.5 (Q3-Q1)
Outlier (Ekstrim) besar:
x Q3 + 1.5 (Q3-Q1)
51.
Contoh
Berikut inidata total pengeluaran mahasiswa selama 1 bulan (dalam ribuan):
Q1= 175, Q2= 350, Q3= 930, min: 0, Max: 1750
apakah ada outlier dalam data ini?
Outlier (Ekstrim) kecil:
x 175 – 1.5 (930-175)
x - 957.5
Outlier (Ekstrim) besar:
x 930 + 1.5 (930-175)
x 2062.5
Oleh karena data min: 0 max: 1750, maka tidak ada data outlier.
52.
Box Plots
53
Box plot adalah tampilan grafis, yang didasarkan pada
kuartil, yang membantu untuk menggambarkan satu set
data.
Ada 5 data yang diperlukan untuk menyusun sebuah
box plot:
1. Nilai Minimum,
2. Kuartil Pertama,
3. Median,
4. Kuartil Ketiga,
5. Nilai Maksimum.
53.
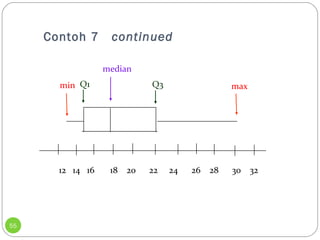
Contoh 7
54
Berdasarkan sampel dari 20 pengiriman, Buddy's Pizza
memperoleh informasi berikut. Waktu pengiriman
minimum adalah 13 menit dan maksimal 30 menit.
Kuartil pertama adalah 15 menit, median 18 menit, dan
kuartil ketiga 22 menit. Susun box plot untuk
pengiriman tersebut.
54.
Contoh 7 continued
55
median
Q1 Q3
min max
12 14 16 18 20 22 24 26 28 30 32
Editor's Notes
#5 Jika ukuran dispersi kecil menunjukkan data terkelompok secara berdekatan disekitar rata-rata hitung/ aritmatik, sehingga nilai sentral (e.g. rata-rata dapat dikatakan reliabel. Sebaliknya ukuran dispersi yang besar menjadi indikator bahwa nilai sentral tidak reliabel.
Misal ada 2 pabrik televisi, A dan B yang memiliki rata-rata produksi per jam yang sama=50. Apakah ini identik? Tapi ternyata, pabrik A per jam produksinya antara 48-52 unit TV, sedang pabrik B produksinya antara 40-60 unit TV per jam. Shg, pabrik A lebih mendekati rata-ratanya.
#22 Dalam buku terjemahan ada kesalahan, seharusnya K kuadrat.




































![Contoh 5 continued
45
7,69 7,72 7,8 7,86 7,90 7,94 7,97 8,06 8,09
Kuartil pertama:
2.5
L = (9 1) 25 25 + =
100
Kuartil pertama berada pada urutan ke-2.5 (antara data ke-2 dan ke-3):
7,72 + [(7,8-7,72)*0.5)= 7,72 + 0.04 = 7.76
Persentil ke-67:
L = (9 1) 67 6.70
67 + =
100
Persentil ke-67 berada pada urutan ke-6.70 (antara ke-6 ke-7):
7,94 + [(7.97-7,94)*0.7]= 7.94 + 0.02 = 7.96](https://image.slidesharecdn.com/statistik13dispersi-141031084005-conversion-gate02/85/Statistik-1-3-dispersi-44-320.jpg)

![Contoh
Tentukan Kuartil pertama (P25) dari data berikut:
Lokasi Persentil: 10*25/100= 2.5 kelas 3-5
P25 = 3 + [(2.5 – 1)/2] * 2
= 4.5
Jumlah film
yg diputar
Frekuensi Frekuensi
Kumulat if
1 up to 3 1 1
3 up to 5 2 3
5 up to 7 3 6
7 up to 9 1 7
9 up to 11 3 10](https://image.slidesharecdn.com/statistik13dispersi-141031084005-conversion-gate02/85/Statistik-1-3-dispersi-46-320.jpg)