



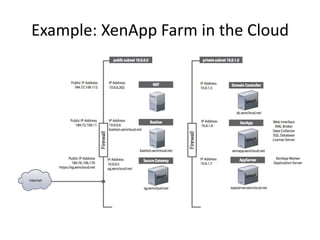

![Typed and Validated Parameters
DBName": {
"Default": "MyDatabase",
"Description" : "MySQL database name",
"Type": "String",
"MinLength": "1",
"MaxLength": "64",
"AllowedPattern" : "[a-zA-Z][a-zA-Z0-9]*",
"ConstraintDescription" : "must begin with a letter and contain only alphanumeric
characters."
},
InstanceType" : {
"Description" : "WebServer EC2 instance type",
"Type" : "String",
"Default" : "m1.small",
"AllowedValues" : [
"t1.micro","m1.small","m1.medium","m1.large","m1.xlarge","m2.xlarge","m2.2xlarge","m2.4
xlarge","m3.xlarge","m3.2xlarge","c1.medium","c1.xlarge","cc1.4xlarge","cc2.8xlarge","c
g1.4xlarge"],
"ConstraintDescription" : "must be a valid EC2 instance type."
},
Default Value
Type
Constraints](https://image.slidesharecdn.com/stackmateccc13-130626041759-phpapp02/85/StackMate-CloudFormation-for-CloudStack-8-320.jpg)
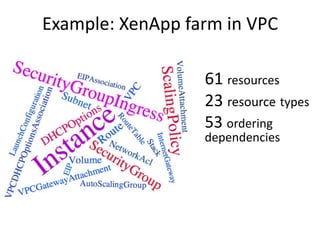
![Resources
WebServer: {
"Type": "AWS::EC2::Instance",
"Metadata" : {
#bootstrap script fetched by cfn-init
},
"Properties": {
"ImageId" : { “Ref” : “ImageId”},
"InstanceType" : { "Ref" : "InstanceType" },
"SecurityGroups" : [ {"Ref" : "WebServerSecurityGroup"} ],
"UserData" : { "Fn::Base64" : { "Fn::Join" : ["", [
"#!/bin/bash -vn",
"yum update -y aws-cfn-bootstrapn”,
"# Install LAMP packagesn",
”/opt/aws/bin/cfn-init -s ", { "Ref" : "AWS::StackId" }, " -r WebServer ”,
"# Setup MySQL, create a user and a databasen",
"mysqladmin -u root password '", { "Ref" : "DBRootPassword" }, "' || error_exit 'Failed
to initialize root password'n",
"# Configure the PHP application - in this case, fixup the page with the right
references to the databasen",
"sed -i "s/REPLACE_WITH_DATABASE/localhost/g" /var/www/html/index.phpn",
"# All is well so signal successn",
"/opt/aws/bin/cfn-signal -e 0 -r "LAMP setup complete" '", { "Ref" : "WaitHandle"
}, "'n"
]]}}
}
Reference to Parameters
Reference to Other Resources
ec2-initbootstrap
Fetchfrommetadataserver](https://image.slidesharecdn.com/stackmateccc13-130626041759-phpapp02/85/StackMate-CloudFormation-for-CloudStack-9-320.jpg)
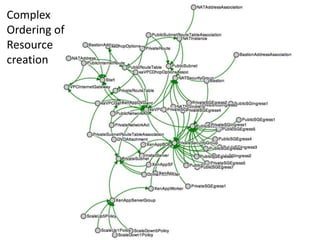
![Outputs
"Outputs" : {
"WebsiteURL" : {
"Value" : { "Fn::Join" : ["", ["http://", { "Fn::GetAtt" :
[ "WebServer", "PublicDnsName" ]}]] },
"Description" : "URL for newly created LAMP stack"
}
Reference to Resources created by the stack](https://image.slidesharecdn.com/stackmateccc13-130626041759-phpapp02/85/StackMate-CloudFormation-for-CloudStack-10-320.jpg)


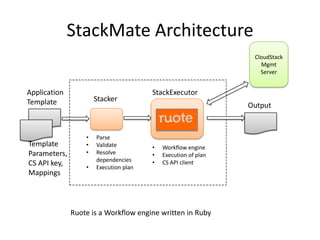

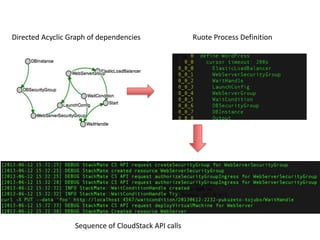


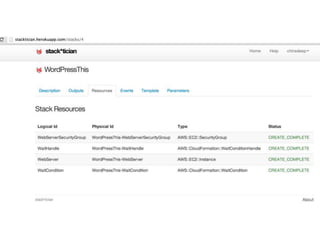
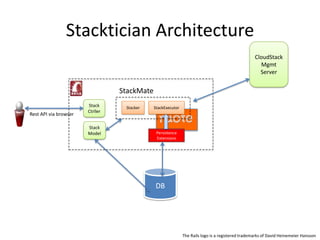








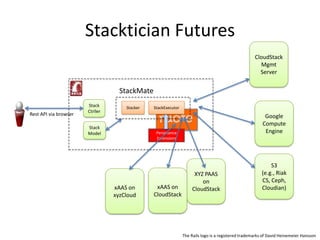


The document provides an overview of 'Stackmate,' a tool that integrates with AWS CloudFormation to manage cloud resources using a JSON-based templating system. It describes the functionalities including parsing, validation, and execution of stack templates while ensuring proper resource creation order and dependency management. Additionally, future directions for Stackmate and Stacktician are mentioned, focusing on extending support for more resource types and improved orchestration capabilities.

















































































