Downloaded 33 times






![What is Spark and Why we Should Care
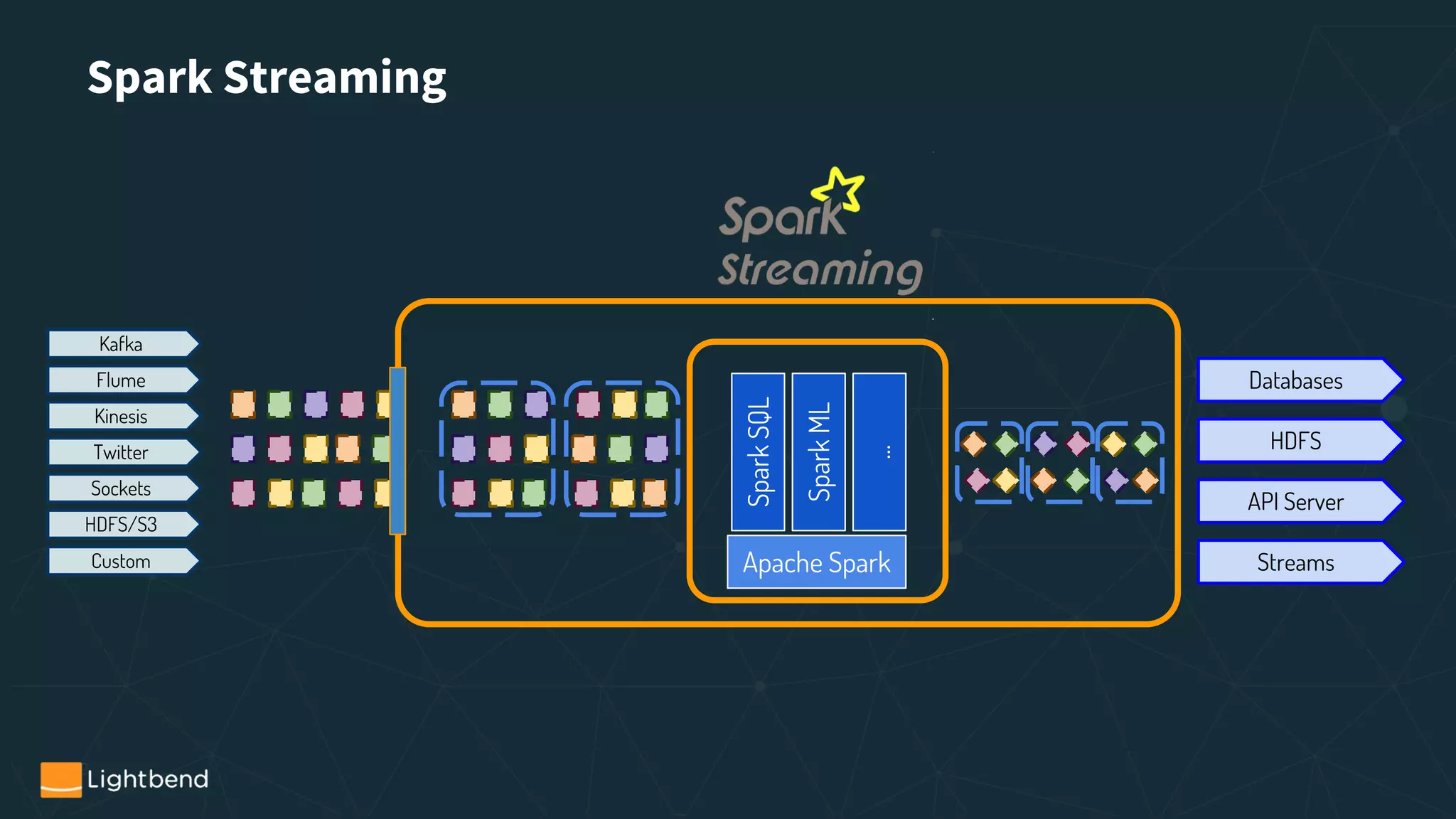
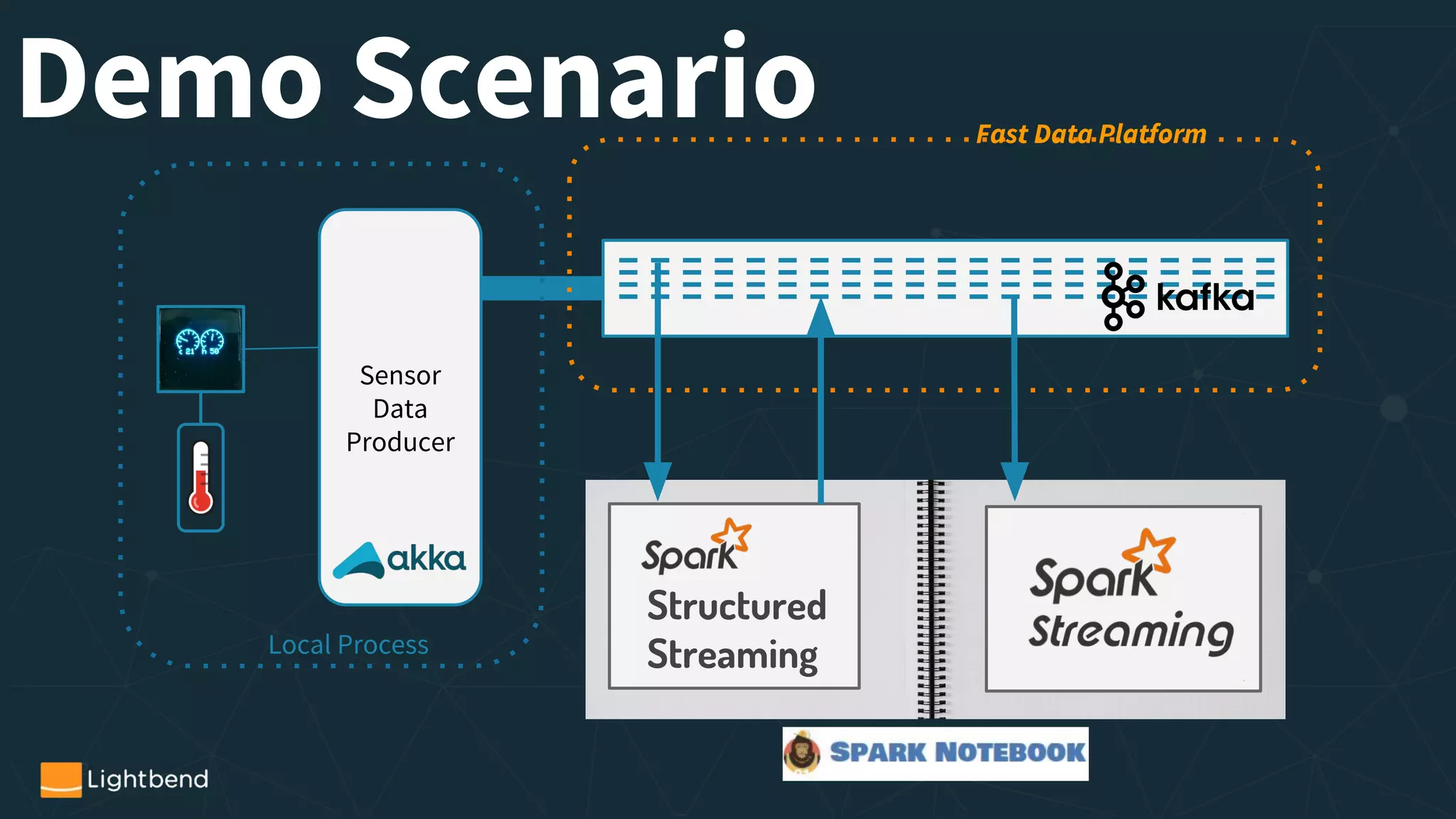
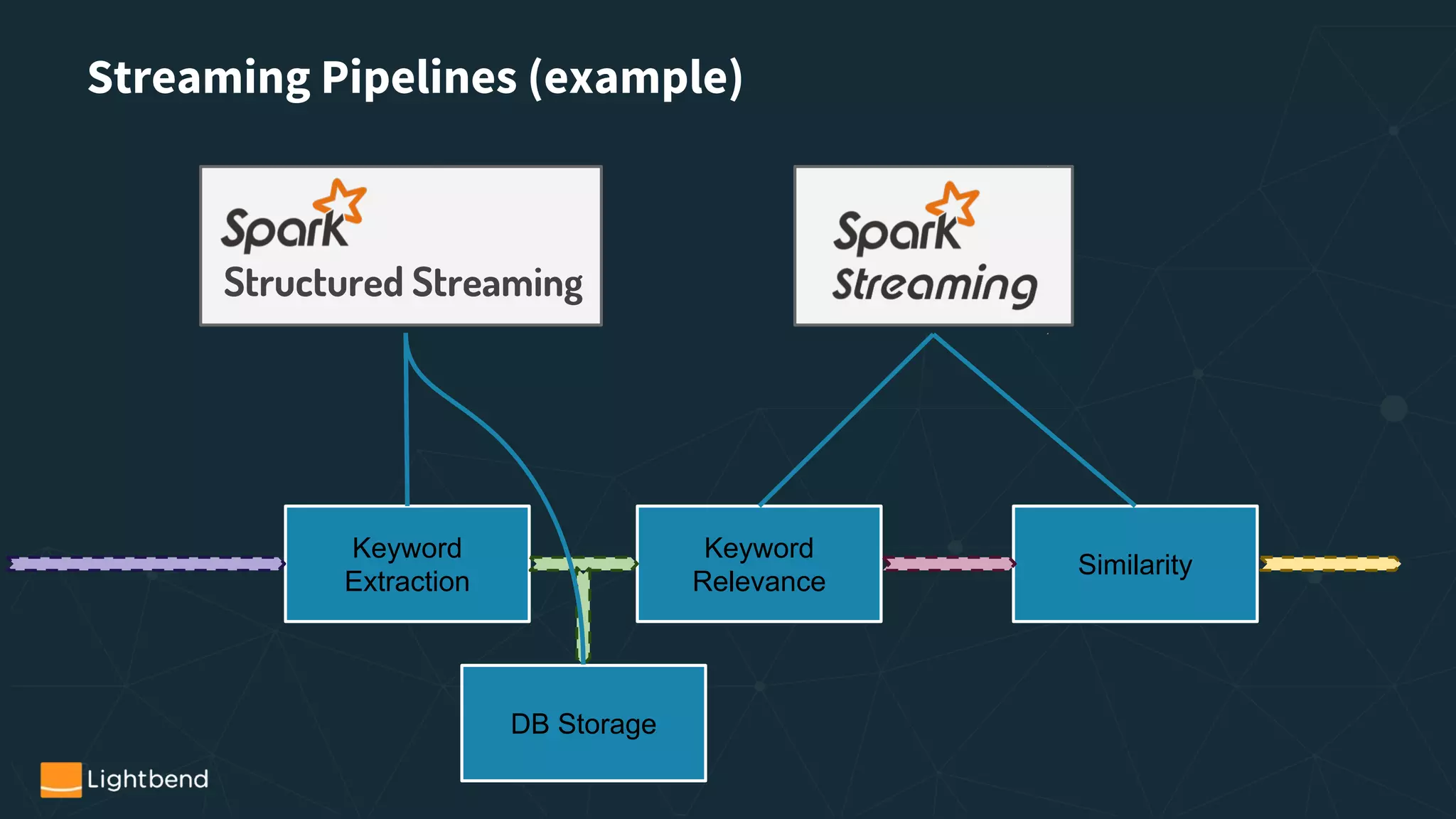
Streaming APIs in Spark
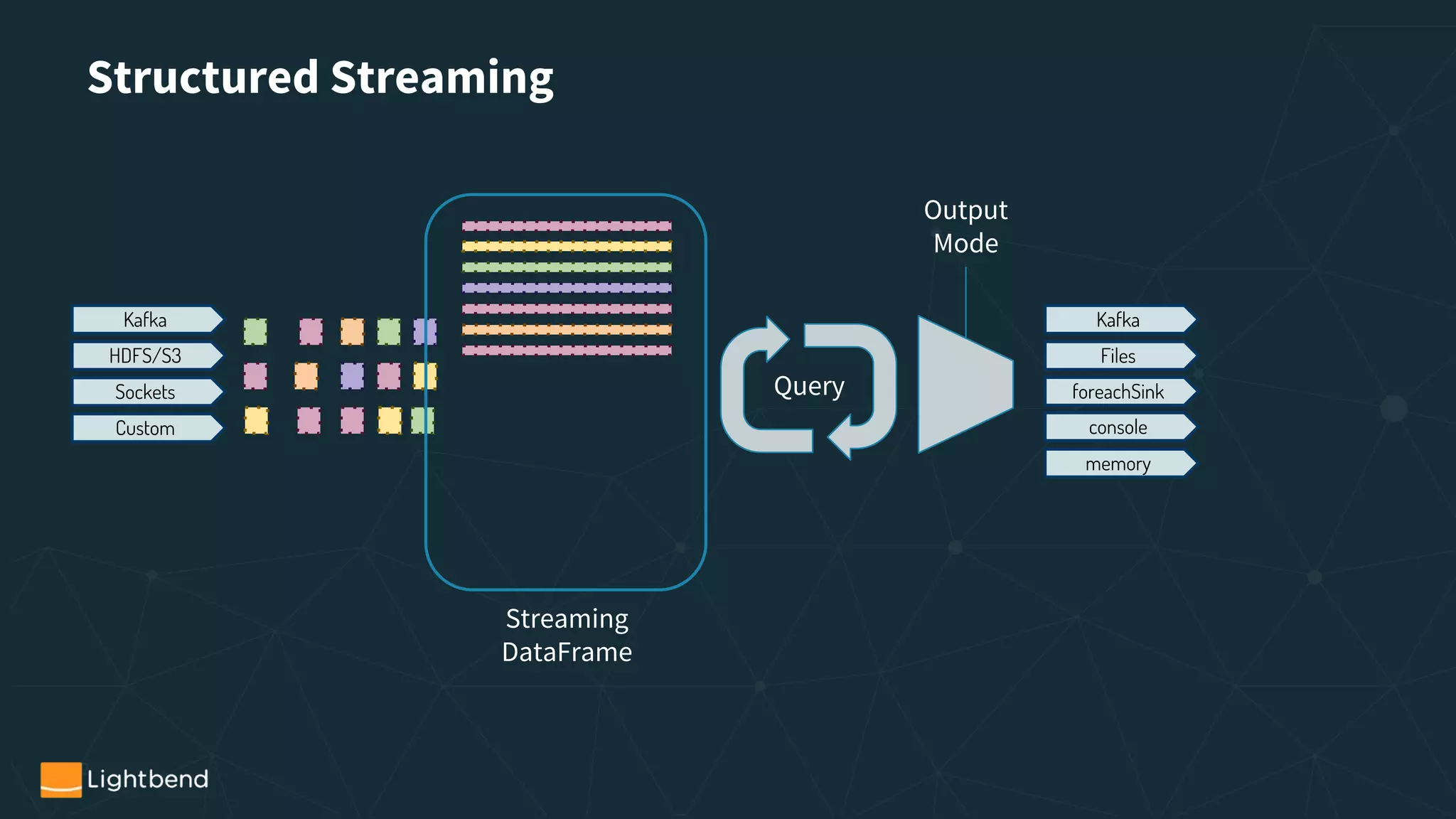
- Structured Streaming Overview
- Interactive Session 1
- Spark Streaming Overview
- Interactive Session 2
Spark Streaming [AND|OR|XOR] Structured Streaming](https://image.slidesharecdn.com/reducedversionwebinarstreaming-with-spark1-171201144525/75/A-Tale-of-Two-APIs-Using-Spark-Streaming-In-Production-8-2048.jpg)





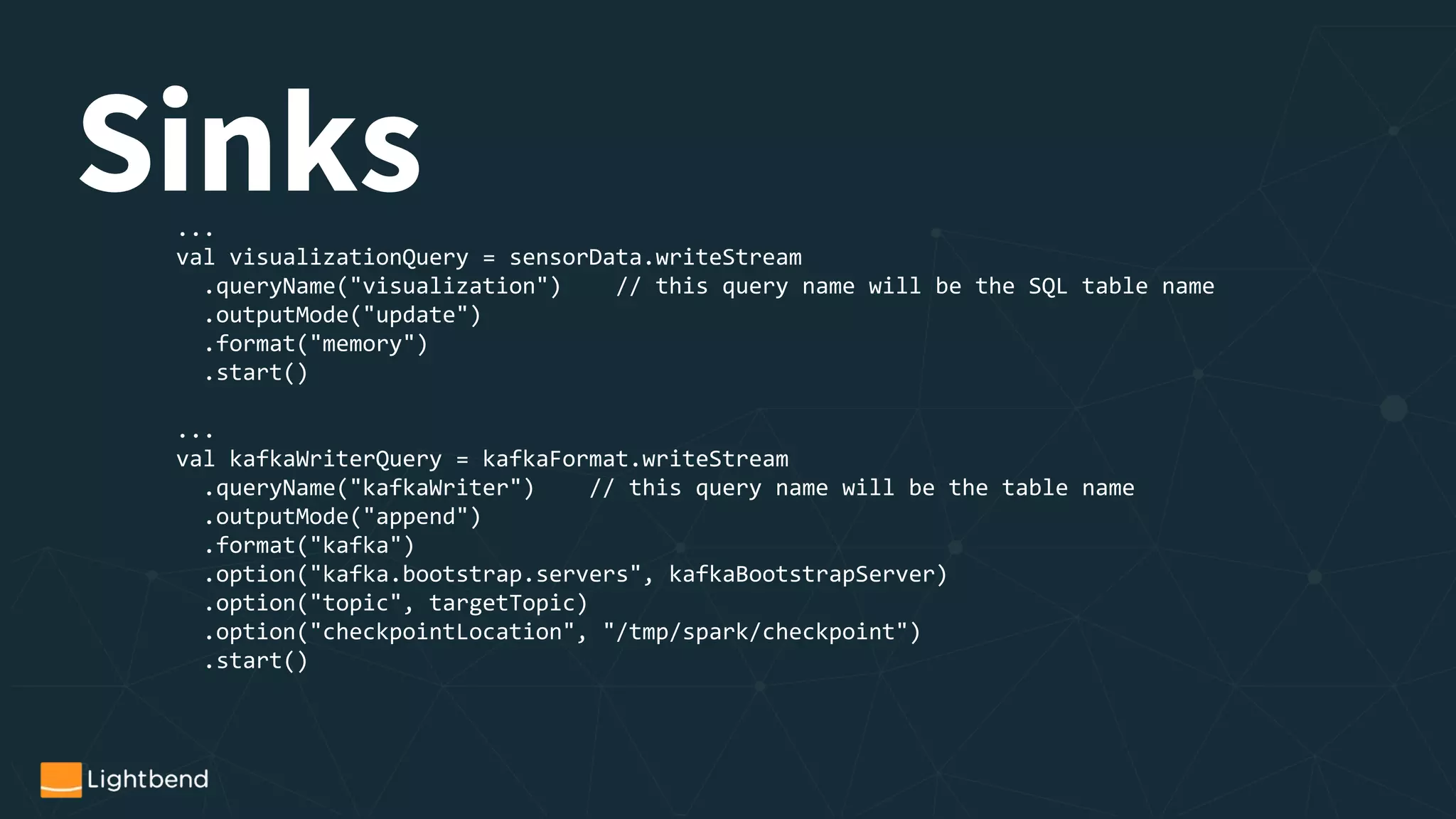
![Operations
...
val rawValues = rawData.selectExpr("CAST(value AS STRING)").as[String]
val jsonValues = rawValues.select(from_json($"value", schema) as "record")
val sensorData = jsonValues.select("record.*").as[SensorData]
…](https://image.slidesharecdn.com/reducedversionwebinarstreaming-with-spark1-171201144525/75/A-Tale-of-Two-APIs-Using-Spark-Streaming-In-Production-17-2048.jpg)



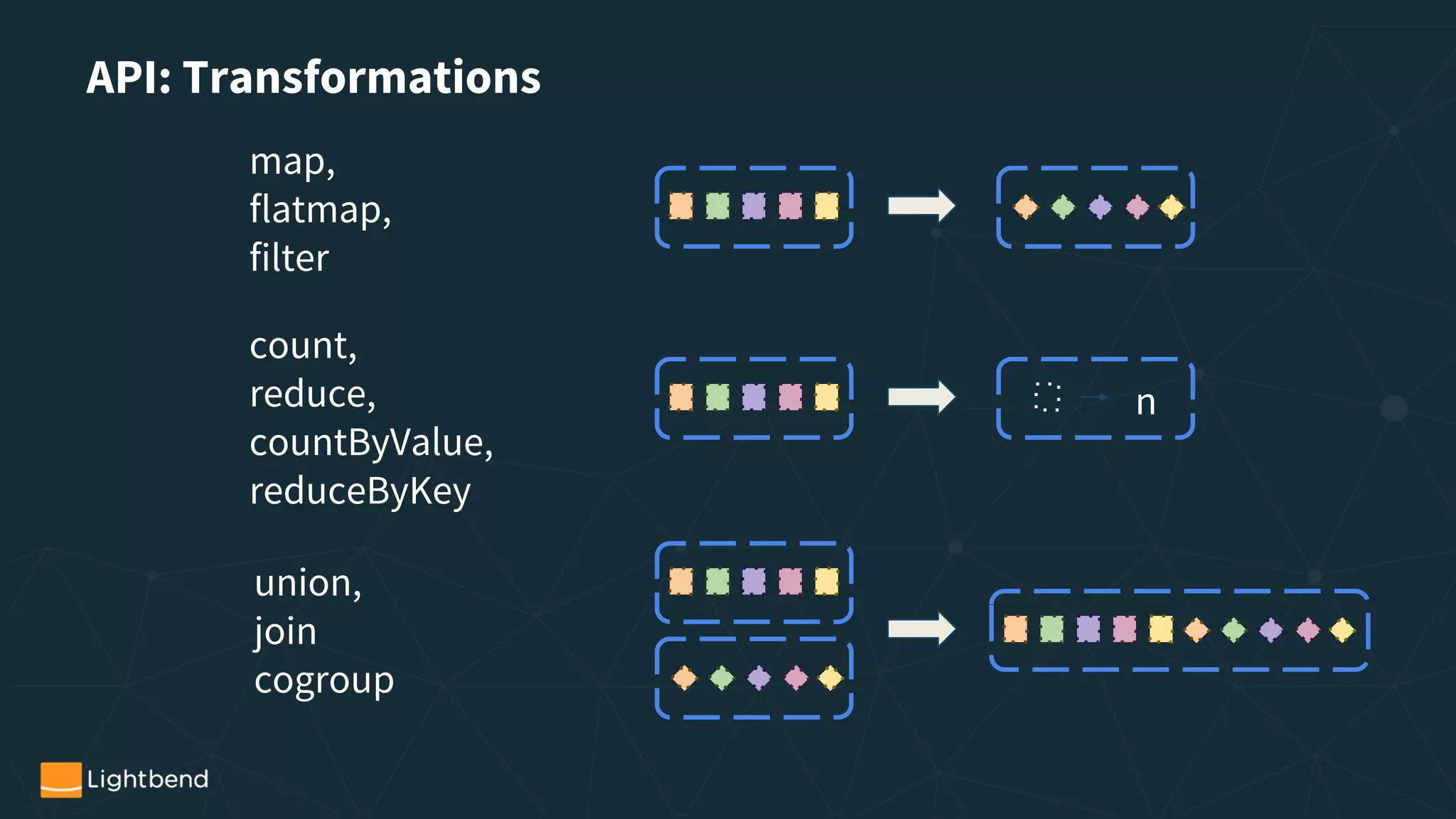
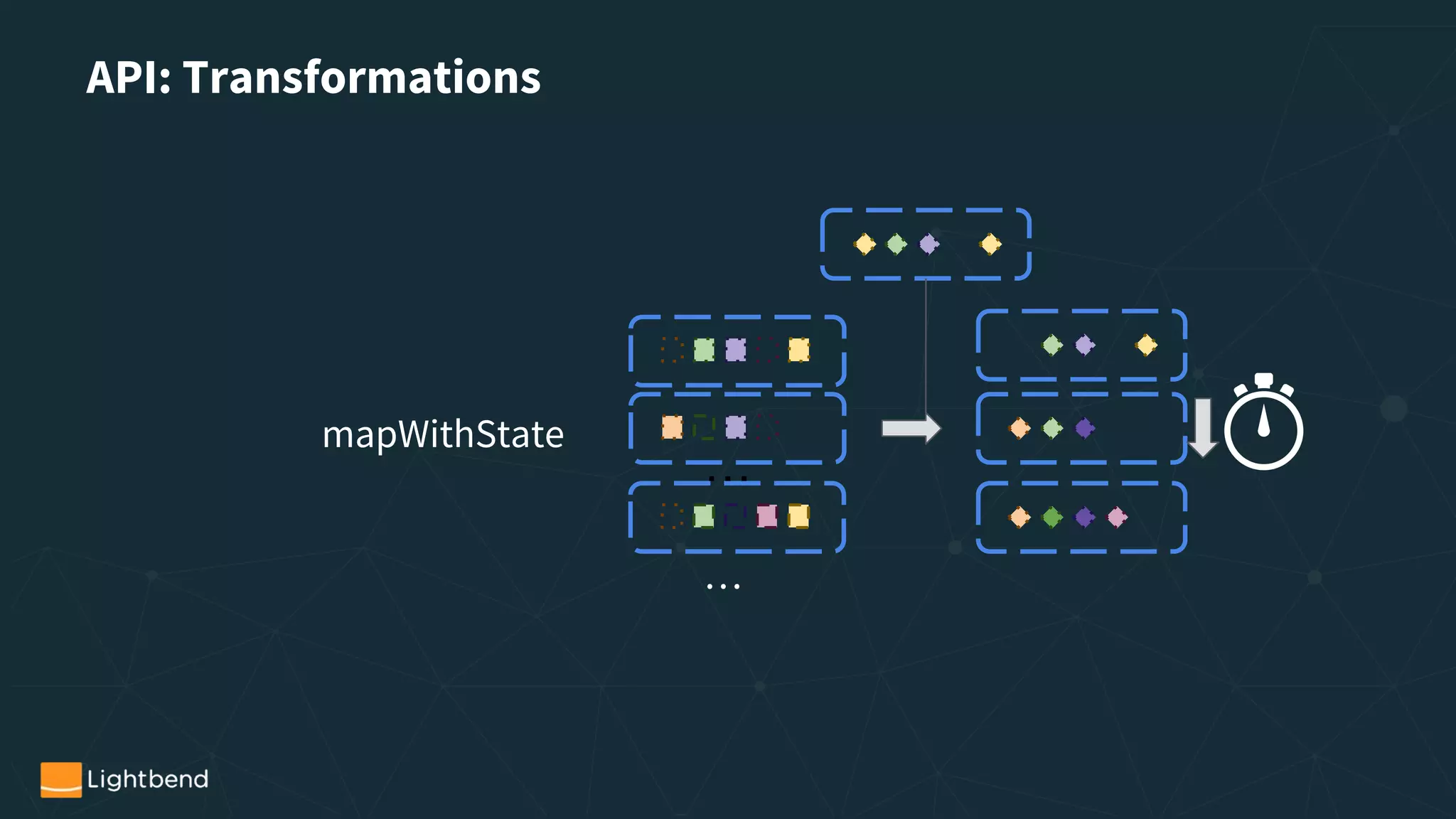
![DStream[T]
RDD[T] RDD[T] RDD[T] RDD[T] RDD[T]
t0 t1 t2 t3 ti ti+1
RDD[U] RDD[U] RDD[U] RDD[U] RDD[U]
Transformation
T -> U
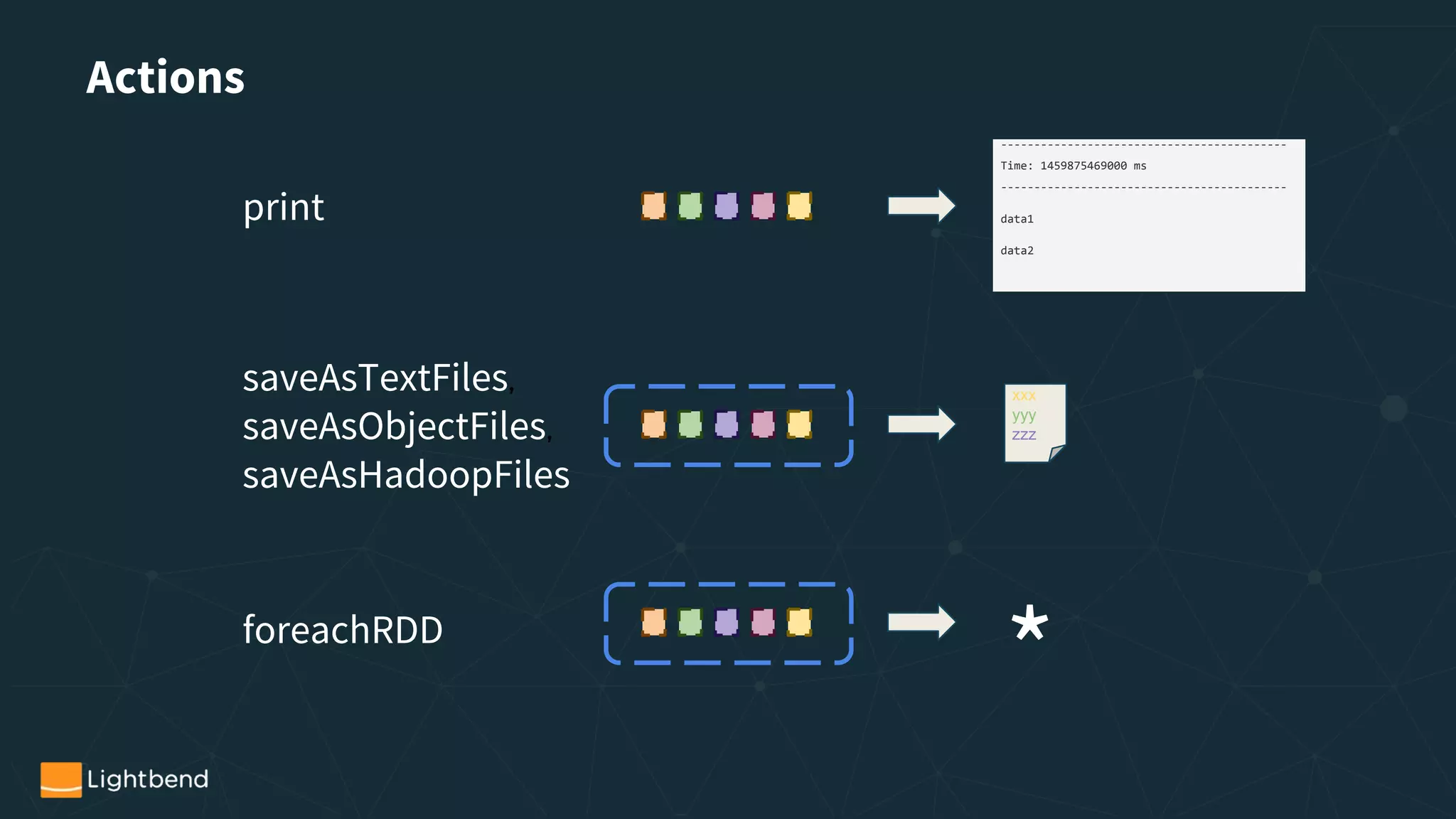
Actions](https://image.slidesharecdn.com/reducedversionwebinarstreaming-with-spark1-171201144525/75/A-Tale-of-Two-APIs-Using-Spark-Streaming-In-Production-23-2048.jpg)



.toString
)
val topics = Set(topic)
@transient val stream = KafkaUtils.createDirectStream[String, String, StringDecoder,
StringDecoder](
streamingContext, kafkaParams, topics)
Source](https://image.slidesharecdn.com/reducedversionwebinarstreaming-with-spark1-171201144525/75/A-Tale-of-Two-APIs-Using-Spark-Streaming-In-Production-32-2048.jpg)
![import spark.implicits._
val sensorDataStream = stream.transform{rdd =>
val jsonData = rdd.map{case (k,v) => v}
val ds = sparkSession.createDataset(jsonData)
val jsonDF = spark.read.json(ds)
val sensorDataDS = jsonDF.as[SensorData]
sensorDataDS.rdd
}
Transformations](https://image.slidesharecdn.com/reducedversionwebinarstreaming-with-spark1-171201144525/75/A-Tale-of-Two-APIs-Using-Spark-Streaming-In-Production-33-2048.jpg)


![Usecases
● Stream-stream joins
● Complex state management (local + cluster state)
● Streaming Machine Learning
○ Learn
○ Score
● Join Streams with Updatable Datasets
● [-] Event-time oriented analytics
● [-] Continuous processing](https://image.slidesharecdn.com/reducedversionwebinarstreaming-with-spark1-171201144525/75/A-Tale-of-Two-APIs-Using-Spark-Streaming-In-Production-36-2048.jpg)

![Spark Streaming + Structured Streaming
38
val parse: Dataset[String] => Dataset[Record] = ???
val process: Dataset[Record] => Dataset[Result] = ???
val serialize: Dataset[Result] => Dataset[String] = ???
val kafkaStream = spark.readStream…
val f = parse andThen process andThen serialize
val result = f(kafkaStream)
result.writeStream
.format("kafka")
.option("kafka.bootstrap.servers",bootstrapServers)
.option("topic", writeTopic)
.option("checkpointLocation", checkpointLocation)
.start()
val dstream = KafkaUtils.createDirectStream(...)
dstream.map{rdd =>
val ds = sparkSession.createDataset(rdd)
val f = parse andThen process andThen serialize
val result = f(ds)
result.write.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServers)
.option("topic", writeTopic)
.option("checkpointLocation", checkpointLocation)
.save()
}
Structured StreamingSpark Streaming](https://image.slidesharecdn.com/reducedversionwebinarstreaming-with-spark1-171201144525/75/A-Tale-of-Two-APIs-Using-Spark-Streaming-In-Production-38-2048.jpg)





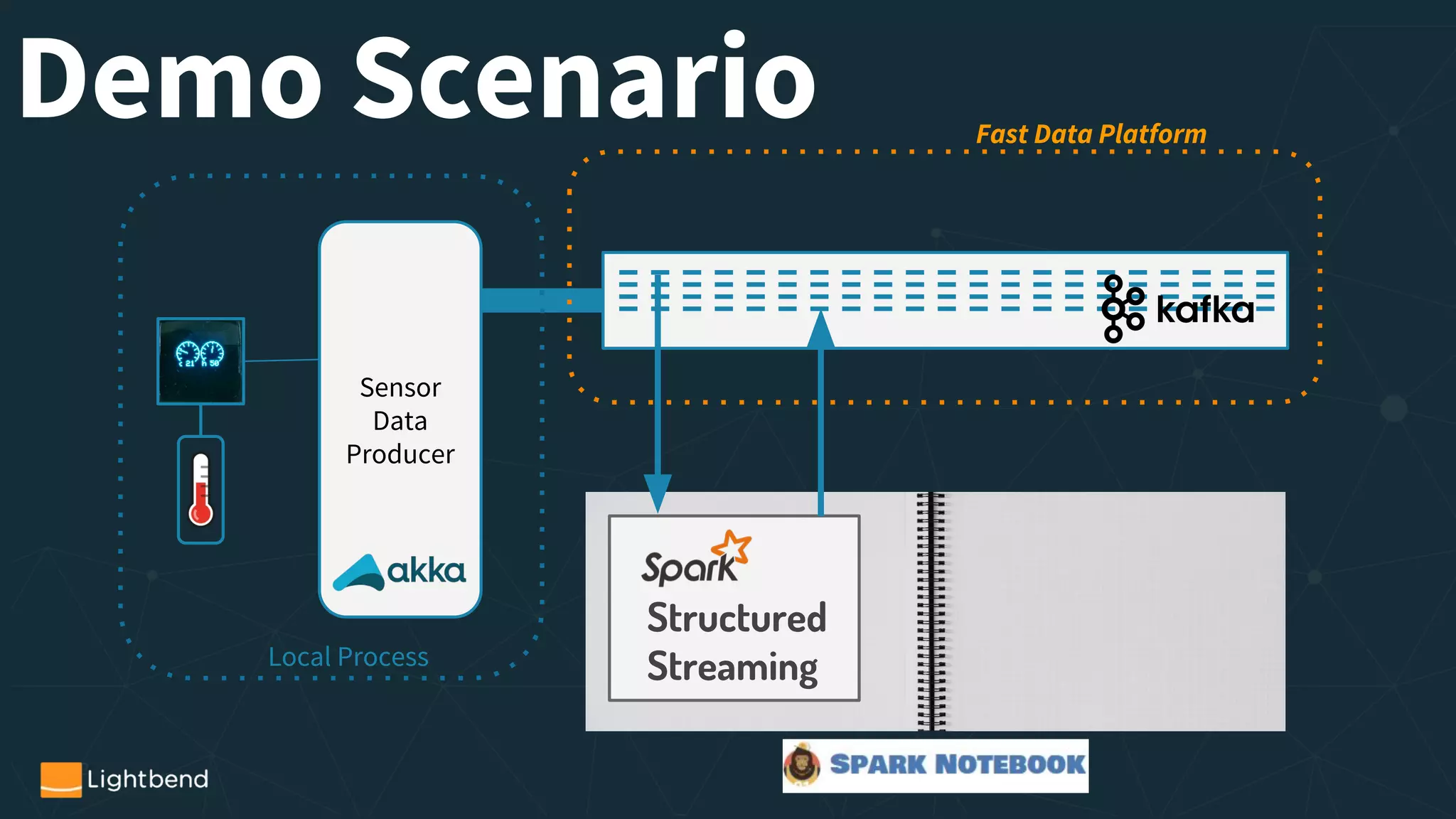
The document presents a detailed overview of streaming data processing using Apache Spark, focusing on structured streaming and its various components such as Kafka and machine learning. It highlights practical use cases, code examples, and the integration of different data sources and operations. The author, Gerard Maas, is an experienced software engineer and an active contributor to the Scala and Spark communities.























































































