This document discusses various technologies related to architectures, frameworks, infrastructure, services, data stores, analytics, logging and metrics. It covers Java 8 features like lambda expressions and method references. It also discusses microservices, Spring Boot basics and features, Gradle vs Maven, Swagger, AngularJS, Gulp, Jasmine, Karma, Nginx, CloudFront, Couchbase, Lambda Architecture, logging with Fluentd and Elasticsearch, metrics collection with Collectd and Statsd, and visualization with Graphite and Grafana.

![Areas of Focus
[ Web ]
[ Services ]
[ Monitoring and Alerting ]
[ Logging and Metrics ]
[ Analytics ]
[ Datastores ]
[ Caching ]](https://image.slidesharecdn.com/d86f44a3-93a1-488a-a262-561f740fbb38-160106163705/75/Architectures-Frameworks-and-Infrastructure-2-2048.jpg)
![[ Services ]](https://image.slidesharecdn.com/d86f44a3-93a1-488a-a262-561f740fbb38-160106163705/75/Architectures-Frameworks-and-Infrastructure-3-2048.jpg)



![SpringBoot - Basics
• Basics
• Use Gradle plugin for runnable jar/war.
• Run a project in-place with bootRun task.
• Spring-Loaded - Reload Java classes without restarting the
container.
• Unlike 'hot code replace' which only allows simple changes
once a JVM is running (e.g. changes to method bodies),
Spring Loaded allows you to add/modify/delete
methods/fields/constructors.
• Datastores
[ If you are using auto-configuration, repositories will be searched from the package
containing your main configuration class (the one annotated with @EnableAutoConfiguration or
@SpringBootApplication) down.]
• JPA
• NoSQL
• Couchbase
• MongoDB](https://image.slidesharecdn.com/d86f44a3-93a1-488a-a262-561f740fbb38-160106163705/75/Architectures-Frameworks-and-Infrastructure-7-2048.jpg)
![SpringBoot - Features
• Externalized Configuration
server:
address: 192.168.2.192
---
spring:
profiles: development
server:
address: 127.0.0.1
---
spring:
profiles: staging
server:
address: 192.168.22.184
• Profile specific configuration values
• Using YAML instead of Properties
• Profile specific application-[profile].yml files
• Multi-profile YAML documents
• Automatic property expansion using Gradle
• Adding active profiles
• -Dspring.profiles.active=production](https://image.slidesharecdn.com/d86f44a3-93a1-488a-a262-561f740fbb38-160106163705/75/Architectures-Frameworks-and-Infrastructure-8-2048.jpg)








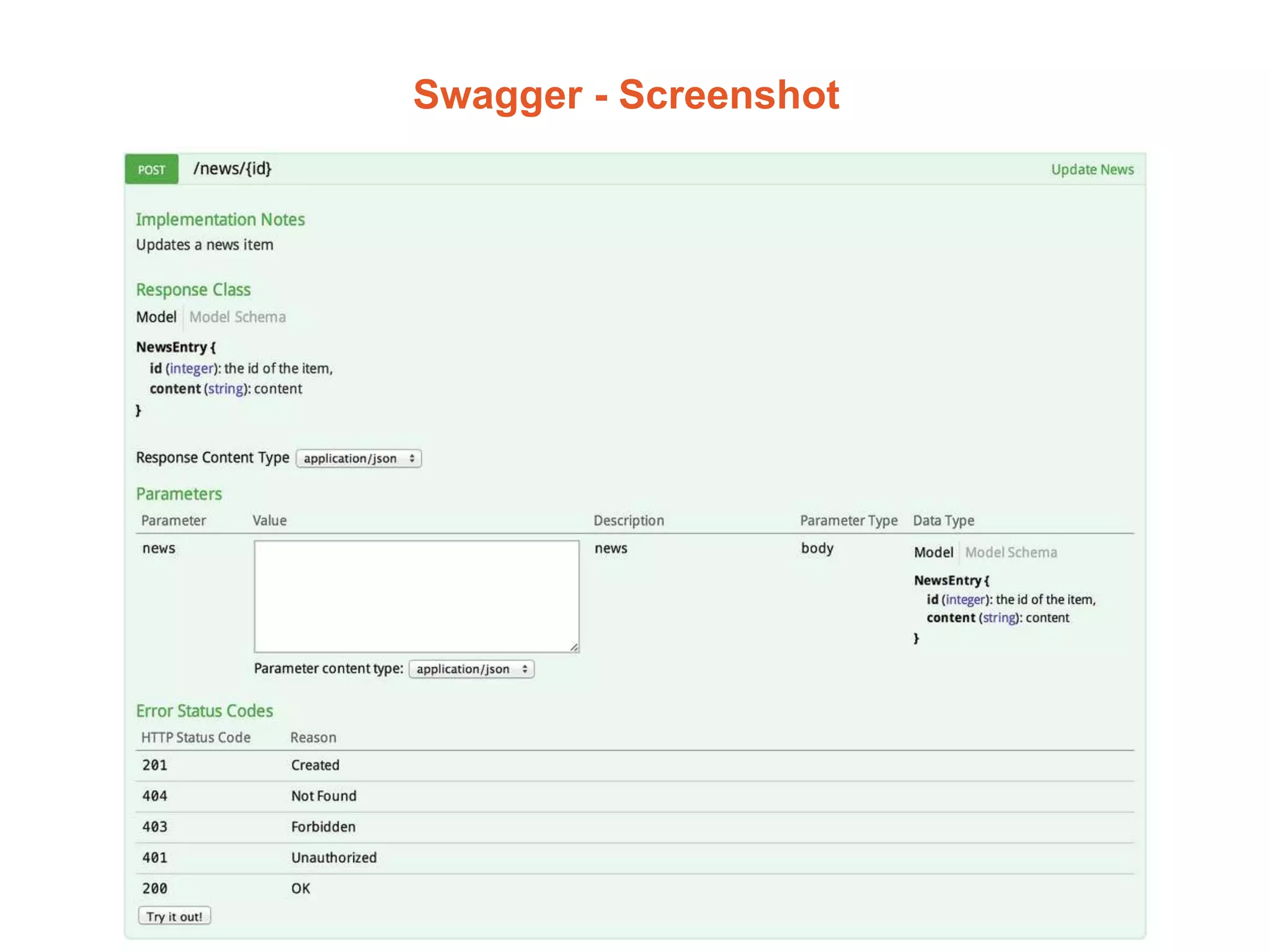
![[ Web ]](https://image.slidesharecdn.com/d86f44a3-93a1-488a-a262-561f740fbb38-160106163705/75/Architectures-Frameworks-and-Infrastructure-18-2048.jpg)






![[ Datastores ]](https://image.slidesharecdn.com/d86f44a3-93a1-488a-a262-561f740fbb38-160106163705/75/Architectures-Frameworks-and-Infrastructure-25-2048.jpg)

![[ Analytics ]](https://image.slidesharecdn.com/d86f44a3-93a1-488a-a262-561f740fbb38-160106163705/75/Architectures-Frameworks-and-Infrastructure-27-2048.jpg)
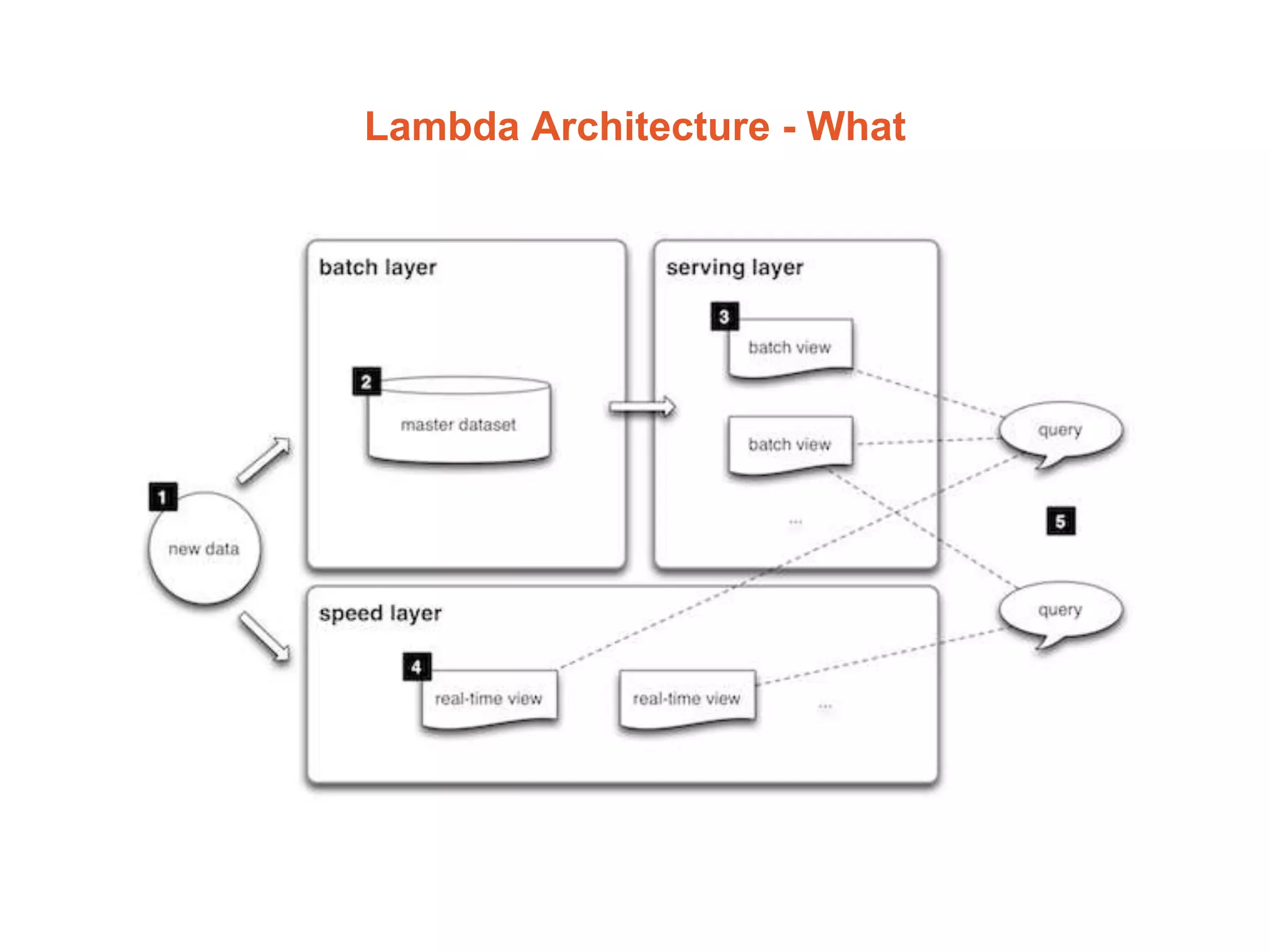


![[ Logging and Metrics ]](https://image.slidesharecdn.com/d86f44a3-93a1-488a-a262-561f740fbb38-160106163705/75/Architectures-Frameworks-and-Infrastructure-31-2048.jpg)



![[ Monitoring and Alerting ]](https://image.slidesharecdn.com/d86f44a3-93a1-488a-a262-561f740fbb38-160106163705/75/Architectures-Frameworks-and-Infrastructure-35-2048.jpg)


![[ Caching ]](https://image.slidesharecdn.com/d86f44a3-93a1-488a-a262-561f740fbb38-160106163705/75/Architectures-Frameworks-and-Infrastructure-38-2048.jpg)















































