勤め先の社内勉強会での発表資料です。日本語版 Wikipedia の抄録を対象として gensim の LdaModel を利用する例を説明した後、LDA の生成モデルについて説明します。そのうえで、gensim の LdaModel に指定できるパラメータや提供されているメソッドの意味を LDA の生成モデルに照らして確認します。










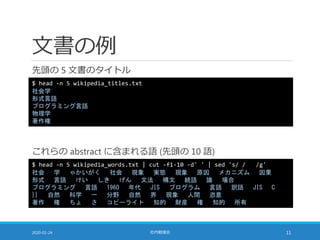
![モデルの学習 [1/5]
文書集合を読み込む
2020-01-24 社内勉強会 12
with open('wikipedia_words.txt', 'r') as f:
docs = [l.strip().split(' ') for l in f]
docs の確認
len(docs)
# 20488
docs[0][:10]
# ['社会', '学', 'ゃかいがく', '社会', '現象', '実態', '現象', '原因',
# 'メカニズム', '因果']](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-12-320.jpg)
![モデルの学習 [2/5]
辞書を作成する
2020-01-24 社内勉強会 13
from gensim.corpora import Dictionary
dic = Dictionary(docs)
dic.filter_extremes(no_below=5, no_above=0.1)
dic.compactify()
◦ 出現する文書数が 5 未満または全体の 10% 超の語は捨てる
辞書の確認
len(dic.items())
# 19544
[x for x in dic.items()][:500:100]
# [(0, '08'), (100, 'プログラミング'), (200, 'New'), (300, '愛知'),
# (400, '賞')]](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-13-320.jpg)
![モデルの学習 [3/5]
辞書を用いて docs を BoW 表現に変換する
2020-01-24 社内勉強会 14
corpus = [dic.doc2bow(d) for d in docs]
corpus の確認
sorted(corpus[0], key=lambda x:x[1], reverse=True)[:10]
# [(45, 5), (4, 3), (13, 3), (22, 2), (27, 2), (29, 2), (31, 2), (33, 2),
# (42, 2), (0, 1)]
dic[45]
# '社会'](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-14-320.jpg)
![モデルの学習 [4/5]
LDA のモデルを学習する
2020-01-24 社内勉強会 15
import logging
from gensim.models import LdaModel
logging.basicConfig(level=logging.INFO)
lda = LdaModel(corpus=corpus, num_topics=50, id2word=dic, passes=30,
chunksize=len(corpus), update_every=0, decay=0,
alpha='auto')
◦ パラメータ設定の意図
◦ トピック数 50
◦ 反復回数 30
◦ バッチ学習 (chunksize, update_every, decay)
◦ 超パラメータ α を非対称として、データから推定する](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-15-320.jpg)
![モデルの学習 [5/5]
学習済みのモデルを保存する
2020-01-24 社内勉強会 16
lda.save('lda_model')
作成されるファイル群
$ ls -1 lda_model*
lda_model
lda_model.expElogbeta.npy
lda_model.id2word
lda_model.state](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-16-320.jpg)
![モデルの利用 [1/4]
保存されたモデルを読み込む
2020-01-24 社内勉強会 17
lda = LdaModel.load('lda_model')
辞書を用いて文書 (0: 社会学) の BoW 表現を得る
bow = lda.id2word.doc2bow(docs[0])
sorted(bow, key=lambda x: x[1], reverse=True)[:10]
# [(45, 5), (4, 3), (13, 3), (22, 2), (27, 2), (29, 2), (31, 2), (33, 2),
# (42, 2), (0, 1)]
lda.id2word[45]
# '社会'](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-17-320.jpg)
![モデルの利用 [2/4]
文書 (0: 社会学) のベクトル表現を得る
2020-01-24 社内勉強会 18
doc_topics = lda[bow]
sorted(doc_topics, key=lambda x: x[1], reverse=True)
# [(40, 0.5127592), (17, 0.16900457), (13, 0.07605075), (21, 0.055048402),
# (18, 0.052849013), (11, 0.048535615), (28, 0.038251393),
# (19, 0.0284172)]
◦ 値が 0.01 未満の次元は無視される (minimum_probability で指定可)
トピック (40) から出やすい単語を確認する
lda.show_topic(40)
# [('学', 0.037192468), ('社会', 0.019697921), ('性', 0.016326433),
# ('研究', 0.014481985), ('論', 0.013506126), ('経済', 0.012653638),
# ('分野', 0.010562398), ('科学', 0.01027073), ('人間', 0.010165557),
# ('哲学', 0.009113403)]](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-18-320.jpg)
![モデルの利用 [3/4]
単語 (45: 社会) のベクトル表現を得る
2020-01-24 社内勉強会 19
from gensim.matutils import unitvec
word_topics = unitvec(lda.get_term_topics(45), 'l1')
sorted(word_topics, key=lambda x: x[1], reverse=True)
# [(40, 0.4573952962266497), (21, 0.2643119328144538),
# (27, 0.1328625669290675), (48, 0.07961762773507063),
# (38, 0.06300880483462193), (29, 0.002803771460136456)]
各トピックから出やすい単語を確認する
for t in [40, 21, 27]:
words = ' '.join([w for w, p in lda.show_topic(t)])
print(f'{t}: {words}')
# 40: 学 社会 性 研究 論 経済 分野 科学 人間 哲学
# 21: 主義 世紀 政治 運動 派 社会 革命 宗教 歴史 自由
# 27: 研究 大学 教授 科学 学 医療 学会 科 専門 教育](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-19-320.jpg)
![モデルの利用 [4/4]
応用例:文書 (0: 社会学) に近い文書を検索する
2020-01-24 社内勉強会 20
from gensim.matutils import hellinger
corpus = [lda.id2word.doc2bow(d) for d in docs]
doc_topics = lda[corpus]
similarities = [hellinger(doc_topics[0], vec) for vec in doc_topics]
with open('wikipedia_titles.txt', 'r') as f:
titles = [l.strip() for l in f]
sorted(zip(titles, similarities), key=lambda x: x[1])[:5]
# [('社会学', 0.000358726519171783),
# ('消極的事実の証明', 0.39963072308952974),
# ('計量学', 0.4017121026471338),
# ('心身問題', 0.41389200570973506),
# ('外向性と内向性', 0.41777963953887276)]](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-20-320.jpg)


















![ディリクレ分布の例 [1/2]
αi が 1 より大きい場合
2020-01-24 社内勉強会 39
LDA ではこういう設定はしない](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-39-320.jpg)
![ディリクレ分布の例 [2/2]
αi が 1 より小さい場合
2020-01-24 社内勉強会 40
LDA ではこういう設定をする
解釈:
◦ 各文書は、すべてのトピック (x1,
x2, x3) のうちごく少数を主題と
する
◦ 各トピックからは、すべての語
彙 (x1, x2, x3) のうちごく少数が
頻出する](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-40-320.jpg)





![モデルの利用
BoW 表現された文書のトピック分布を得る
2020-01-24 社内勉強会 46
doc_topics = lda[bow]
sorted(doc_topics, key=lambda x: x[1], reverse=True)
# [(40, 0.5127592), (17, 0.16900457), (13, 0.07605075), (21, 0.055048402),
# (18, 0.052849013), (11, 0.048535615), (28, 0.038251393),
# (19, 0.0284172)]
◦ get_document_topics メソッドでも概ね同じ
トピックの単語分布を得る
lda.show_topic(40)
# [('学', 0.037192468), ('社会', 0.019697921), ('性', 0.016326433),
# ('研究', 0.014481985), ('論', 0.013506126), ('経済', 0.012653638),
# ('分野', 0.010562398), ('科学', 0.01027073), ('人間', 0.010165557),
# ('哲学', 0.009113403)]
◦ get_topic_terms メソッドを使えば単語は word_id で戻る](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-46-320.jpg)

![per_word_topics=True
BoW 表現された文書のトピック分布を得る
2020-01-24 社内勉強会 48
doc_topics, word_topics, word_topic_probs = ¥
lda.get_document_topics(bow, per_word_topics=True)
word_topic_probs[0]
# (0, [(17, 0.5443574), (28, 0.45384607)])
◦ word_id=0 は topic 17 から 0.544 回、topic 28 から 0.454 回出現
lda.id2word[45]
# '社会'
dict(word_topic_probs)[45]
# [(21, 0.26105392), (40, 4.7388897)]
◦ word_id=45 は topic 21 から 0.261 回、topic 40 から 4.739 回出現
◦ "社会" はこの文書に 5 回出現しているので合計が 5 になる](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-48-320.jpg)




![α や η の目安は?
私にはよくわからない
◦ Blei らの論文[1]
◦ α は非対称 (asymmetric), η は対称 (symmetric) として話が進む
◦ これらの超パラメータも推定する (論文 Appendix に記載)
◦ (著者らによる) lda-c の実装は symmetric α のみ対応。η は存在しない
◦ Blei らの論文では η は "Smoothing" として途中から導入される
◦ Griffiths らの論文[2]
◦ α = 50/K (K = 50, 100, 200, 300, 400, 500, 600, 1000 で実験している)
◦ η = 0.1
◦ (CGS に基づく) GibbsLDA++ と PLDA は α, η とも symmetric のみ対応。推定もなし
◦ Wallach らの論文[3]
◦ Asymmetric α の方が良いモデル (低 perplexity) が得られたという報告
2020-01-24 社内勉強会 53
[1] D. Blei, A. Ng, M. Jordan. Latent Dirichlet Allocation. JMLR 2003.
[2] T. Griffiths, M. Steyvers. Finding Scientific Topics. PNAS 2004.
[3] H. Wallach, D. Mimno, A. McCallum. Rethinking LDA: Why Priors Matter. NIPS 2009.](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-53-320.jpg)




![gensim のドキュメントには
update_every=0 でバッチ学習とあるが?
実装を確認したところ以下も設定すべきに思える
◦ chunksize を文書数にする (または None にする)
◦ decay=0 とする (0.5 から 1 と書かれているが 0 でも通る)
実装の詳細
◦ update_every は M-step の実行間隔を制御するだけ
◦ update_every=0 でも E-step や超パラメータ更新は chunksize ごとに実行される
◦ decay の設定は常に (update_every=0 でも) 有効
補足:gensim の LDA が参照する論文[4] にある記述
◦ "Note that we recover batch VB when S=D and κ=0."
◦ ここでの S が chunk に、κ が decay に対応する
2020-01-24 社内勉強会 58
[4] M. Hoffman, D. Blei, F. Bach. Online Learning for Latent Dirichlet Allocation. NIPS 2010.](https://image.slidesharecdn.com/latentdirichletallocation-200118112628/85/slide-58-320.jpg)











![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)























































