Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
正志 坪坂
PDF, PPTX
3,049 views
Icml2011 reading-sage
ICML 2011読む会(2011/7/16@PFI)発表資料
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
「統計的学習理論」第1章
by
Kota Matsui
PDF
A summary on “On choosing and bounding probability metrics”
by
Kota Matsui
PDF
TokyoNLP#7 きれいなジャイアンのカカカカ☆カーネル法入門-C++
by
sleepy_yoshi
PDF
文字列カーネルによる辞書なしツイート分類 〜文字列カーネル入門〜
by
Takeshi Arabiki
PDF
パターン認識第9章 学習ベクトル量子化
by
Miyoshi Yuya
PDF
演習発表 Sari v.1.2
by
Lutfiana Ariestien
PDF
Cvpr2011 reading-tsubosaka
by
正志 坪坂
PDF
PRML 第14章
by
Akira Miyazawa
「統計的学習理論」第1章
by
Kota Matsui
A summary on “On choosing and bounding probability metrics”
by
Kota Matsui
TokyoNLP#7 きれいなジャイアンのカカカカ☆カーネル法入門-C++
by
sleepy_yoshi
文字列カーネルによる辞書なしツイート分類 〜文字列カーネル入門〜
by
Takeshi Arabiki
パターン認識第9章 学習ベクトル量子化
by
Miyoshi Yuya
演習発表 Sari v.1.2
by
Lutfiana Ariestien
Cvpr2011 reading-tsubosaka
by
正志 坪坂
PRML 第14章
by
Akira Miyazawa
What's hot
PDF
TokyoNLP#5 パーセプトロンで楽しい仲間がぽぽぽぽ~ん
by
sleepy_yoshi
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PDF
PRML上巻勉強会 at 東京大学 資料 第1章後半
by
Ohsawa Goodfellow
PPTX
パターン認識モデル初歩の初歩
by
t_ichioka_sg
PDF
2値分類・多クラス分類
by
t dev
PDF
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
PDF
8.4 グラフィカルモデルによる推論
by
sleepy_yoshi
PDF
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
PDF
はじめてのパターン認識輪読会 10章後半
by
koba cky
PDF
最近傍探索と直積量子化(Nearest neighbor search and Product Quantization)
by
Nguyen Tuan
PDF
PRML chapter7
by
Takahiro (Poly) Horikawa
PDF
演習発表 Sari v.1.1
by
Lutfiana Ariestien
PDF
20130716 はじパタ3章前半 ベイズの識別規則
by
koba cky
PDF
CVIM#11 3. 最小化のための数値計算
by
sleepy_yoshi
PDF
Tsulide
by
tononro
PDF
KDD'17読み会:Anomaly Detection with Robust Deep Autoencoders
by
Satoshi Hara
PDF
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
PDF
パターン認識 05 ロジスティック回帰
by
sleipnir002
TokyoNLP#5 パーセプトロンで楽しい仲間がぽぽぽぽ~ん
by
sleepy_yoshi
20170422 数学カフェ Part1
by
Kenta Oono
PRML上巻勉強会 at 東京大学 資料 第1章後半
by
Ohsawa Goodfellow
パターン認識モデル初歩の初歩
by
t_ichioka_sg
2値分類・多クラス分類
by
t dev
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
8.4 グラフィカルモデルによる推論
by
sleepy_yoshi
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
はじめてのパターン認識輪読会 10章後半
by
koba cky
最近傍探索と直積量子化(Nearest neighbor search and Product Quantization)
by
Nguyen Tuan
PRML chapter7
by
Takahiro (Poly) Horikawa
演習発表 Sari v.1.1
by
Lutfiana Ariestien
20130716 はじパタ3章前半 ベイズの識別規則
by
koba cky
CVIM#11 3. 最小化のための数値計算
by
sleepy_yoshi
Tsulide
by
tononro
KDD'17読み会:Anomaly Detection with Robust Deep Autoencoders
by
Satoshi Hara
パターン認識と機械学習6章(カーネル法)
by
Yukara Ikemiya
パターン認識 05 ロジスティック回帰
by
sleipnir002
Similar to Icml2011 reading-sage
PDF
Prml 10 1
by
正志 坪坂
PDF
Chap12 4 appendix_suhara
by
sleepy_yoshi
PDF
Chap12 4 appendix_suhara
by
sleepy_yoshi
PDF
WordNetで作ろう! 言語横断検索サービス
by
Shintaro Takemura
PDF
Appendix document of Chapter 6 for Mining Text Data
by
Yuki Nakayama
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
テキストデータの理論的サンプリング
by
Naohiro Matsumura
PDF
お披露目会05/2010
by
JAVA DM
PDF
第17回コンピュータビジョン勉強会@関東
by
ukyoda
PDF
テキストマイニングで発掘!? 売上とユーザーレビューの相関分析
by
Shintaro Takemura
PDF
2013 03 25
by
Mutsuki Kojima
PDF
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
PDF
Infomation geometry(overview)
by
Yoshitake Misaki
PDF
ノンパラベイズ入門の入門
by
Shuyo Nakatani
PDF
社内勉強会-ナイーブベイジアンフィルタの実装
by
Kenta Onishi
PDF
生物統計特論3資料 2006 ギブス MCMC isseing333
by
Issei Kurahashi
PDF
機械学習を用いたWeb上の産学連携関連文書の抽出
by
National Institute of Informatics
PDF
潜在ディリクレ配分法
by
y-uti
PPTX
Ym20121122
by
Yoichi Motomura
PDF
Unified Expectation Maximization
by
Koji Matsuda
Prml 10 1
by
正志 坪坂
Chap12 4 appendix_suhara
by
sleepy_yoshi
Chap12 4 appendix_suhara
by
sleepy_yoshi
WordNetで作ろう! 言語横断検索サービス
by
Shintaro Takemura
Appendix document of Chapter 6 for Mining Text Data
by
Yuki Nakayama
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
テキストデータの理論的サンプリング
by
Naohiro Matsumura
お披露目会05/2010
by
JAVA DM
第17回コンピュータビジョン勉強会@関東
by
ukyoda
テキストマイニングで発掘!? 売上とユーザーレビューの相関分析
by
Shintaro Takemura
2013 03 25
by
Mutsuki Kojima
ベイズ推論による機械学習入門 第4章
by
YosukeAkasaka
Infomation geometry(overview)
by
Yoshitake Misaki
ノンパラベイズ入門の入門
by
Shuyo Nakatani
社内勉強会-ナイーブベイジアンフィルタの実装
by
Kenta Onishi
生物統計特論3資料 2006 ギブス MCMC isseing333
by
Issei Kurahashi
機械学習を用いたWeb上の産学連携関連文書の抽出
by
National Institute of Informatics
潜在ディリクレ配分法
by
y-uti
Ym20121122
by
Yoichi Motomura
Unified Expectation Maximization
by
Koji Matsuda
More from 正志 坪坂
PDF
Recsys2018 unbiased
by
正志 坪坂
PDF
WSDM2018Study
by
正志 坪坂
PDF
Recsys2016勉強会
by
正志 坪坂
PPTX
KDD 2016勉強会 Deep crossing
by
正志 坪坂
PDF
Deeplearning輪読会
by
正志 坪坂
PDF
WSDM 2016勉強会 Geographic Segmentation via latent factor model
by
正志 坪坂
PDF
Deeplearning勉強会20160220
by
正志 坪坂
PDF
OnlineMatching勉強会第一回
by
正志 坪坂
PDF
Recsys2015
by
正志 坪坂
PDF
KDD 2015読み会
by
正志 坪坂
PDF
Recsys2014 recruit
by
正志 坪坂
PDF
EMNLP2014_reading
by
正志 坪坂
PDF
Tokyowebmining ctr-predict
by
正志 坪坂
PDF
KDD2014_study
by
正志 坪坂
PDF
Riak Search 2.0を使ったデータ集計
by
正志 坪坂
PDF
Contexual bandit @TokyoWebMining
by
正志 坪坂
PDF
Introduction to contexual bandit
by
正志 坪坂
PDF
確率モデルを使ったグラフクラスタリング
by
正志 坪坂
PDF
Big Data Bootstrap (ICML読み会)
by
正志 坪坂
PDF
Tokyowebmining2012
by
正志 坪坂
Recsys2018 unbiased
by
正志 坪坂
WSDM2018Study
by
正志 坪坂
Recsys2016勉強会
by
正志 坪坂
KDD 2016勉強会 Deep crossing
by
正志 坪坂
Deeplearning輪読会
by
正志 坪坂
WSDM 2016勉強会 Geographic Segmentation via latent factor model
by
正志 坪坂
Deeplearning勉強会20160220
by
正志 坪坂
OnlineMatching勉強会第一回
by
正志 坪坂
Recsys2015
by
正志 坪坂
KDD 2015読み会
by
正志 坪坂
Recsys2014 recruit
by
正志 坪坂
EMNLP2014_reading
by
正志 坪坂
Tokyowebmining ctr-predict
by
正志 坪坂
KDD2014_study
by
正志 坪坂
Riak Search 2.0を使ったデータ集計
by
正志 坪坂
Contexual bandit @TokyoWebMining
by
正志 坪坂
Introduction to contexual bandit
by
正志 坪坂
確率モデルを使ったグラフクラスタリング
by
正志 坪坂
Big Data Bootstrap (ICML読み会)
by
正志 坪坂
Tokyowebmining2012
by
正志 坪坂
Icml2011 reading-sage
1.
論文紹介 Sparse Additive Generative
Model for Text icml 2011読み会 2011/7/16
2.
論文の背景 • 近年Dirichlet-multinomial分布を使った文章の生成モデルが
流行してる(e.g. LDA) • これらの分布を使った推論は比較的簡単であるという利点 がある • しかしながら、このような生成モデルには3つの問題点がある – Inference cost – Overparametrization – Lack of sparsity
3.
Inference cost • 評判情報やイデオロギーなど複数の側面を考慮した生成モ
デルを考えることがある(Mei + 2007 WWW, Ahmed & Xing 2010 EMNLP, Paul & Girju 2010 AAAI) • 多くの場合複数の側面の追加はトークンごとの潜在変数の 追加が必要となる – どの側面が有効かの”switch”に使われる • このため推論のコストが大きくなる Ahmed & Xing 2010(EMNLP)
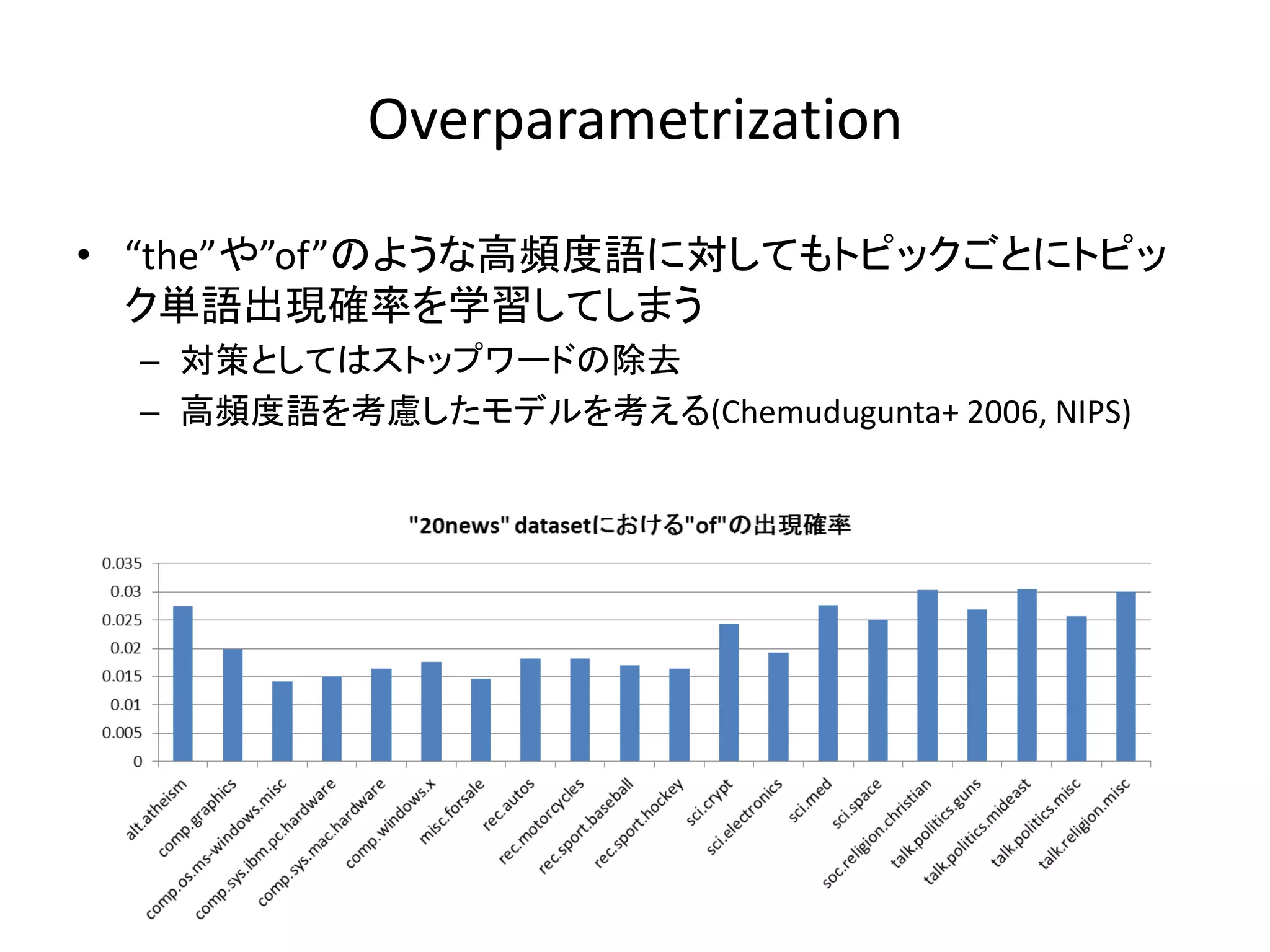
4.
Overparametrization • “the”や”of”のような高頻度語に対してもトピックごとにトピッ
ク単語出現確率を学習してしまう – 対策としてはストップワードの除去 – 高頻度語を考慮したモデルを考える(Chemudugunta+ 2006, NIPS)
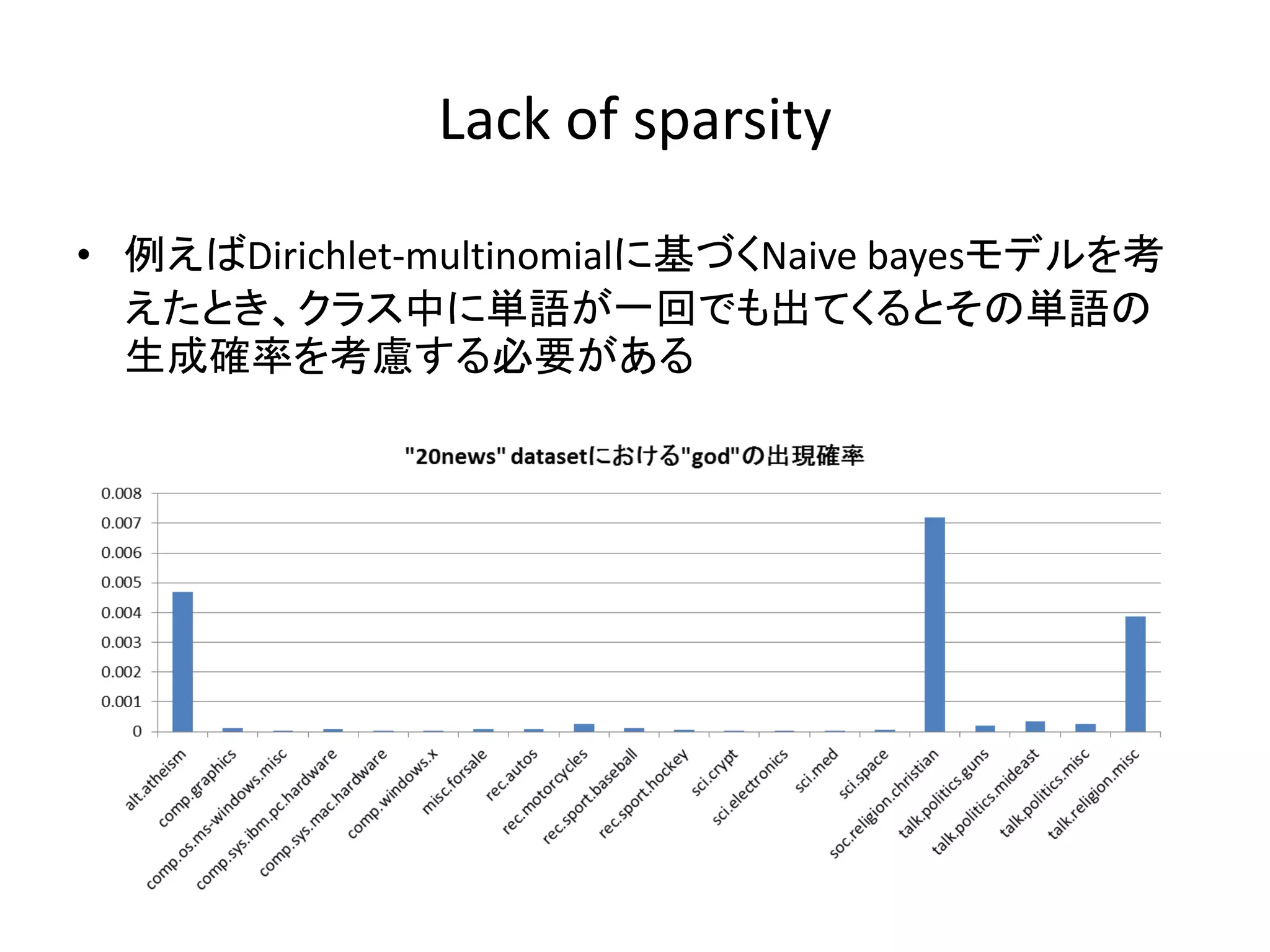
5.
Lack of sparsity •
例えばDirichlet-multinomialに基づくNaive bayesモデルを考 えたとき、クラス中に単語が一回でも出てくるとその単語の 生成確率を考慮する必要がある
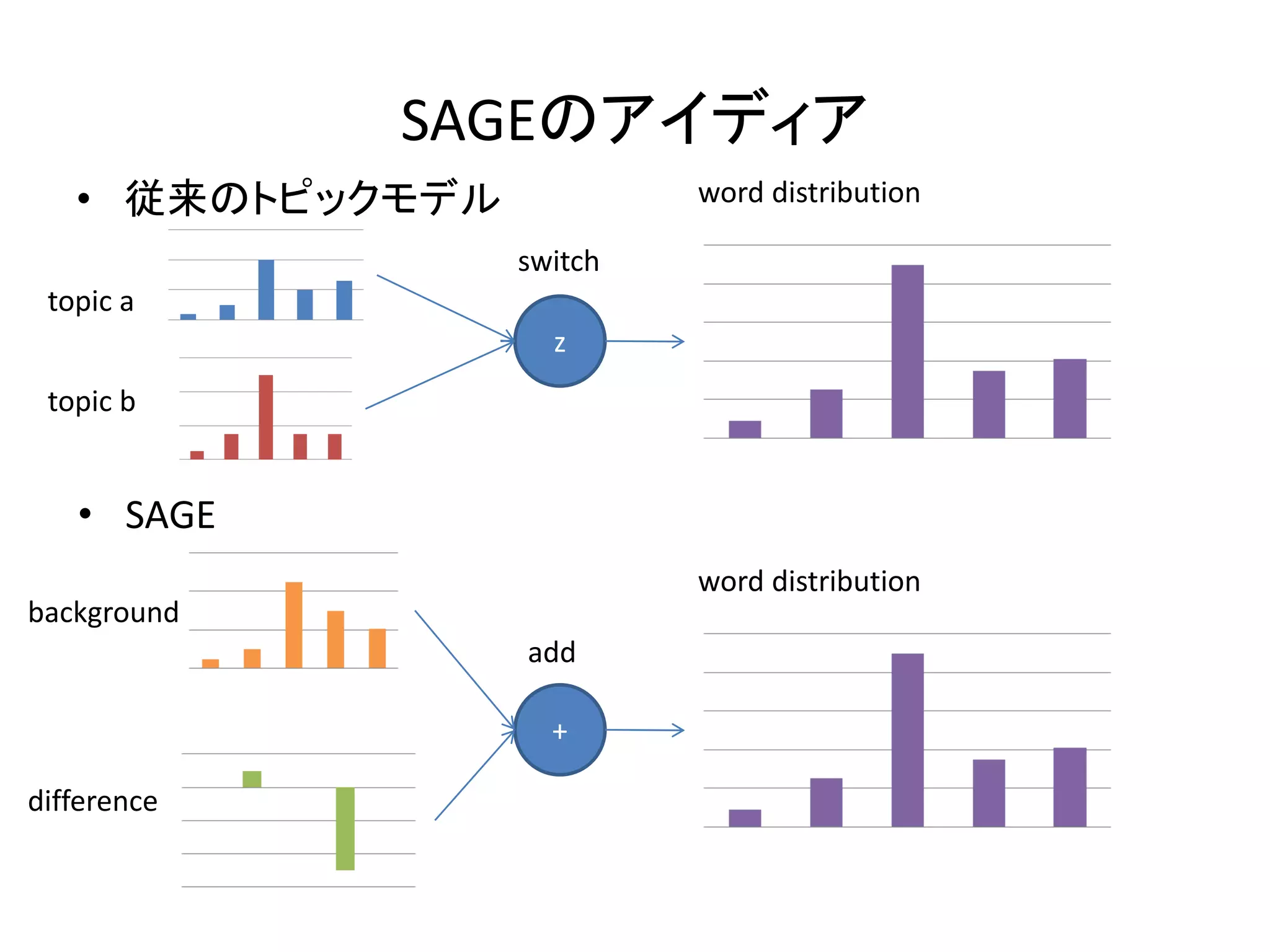
6.
Sparse Additive GEnerative
model (SAGE) • 上記の問題解決のためSAGEというモデルを導入する • このモデルではコーパスでの単語の対数頻度から文章ラベ ルや潜在変数に応じた差分をモデル化する • このモデルのメリットとして – 差分に関してsparseになるようなpriorを導入することにより、多くの単 語の差分を0とできる – 複数の側面があるときに各側面に関する差分を足し合わせるだけで 単語の生成確率が求まる • このモデルはDirichlet-mutlinomialなモデルを単純に置き換 えることができる、論文では以下の3つのモデルに関して SAGEの優位性を示している – Naive bayes分類 – トピックモデル(LDA) – イデオロギーや地理情報を加味した文章生成モデル
7.
SAGEのアイディア
• 従来のトピックモデル word distribution switch topic a z topic b • SAGE word distribution background add + difference
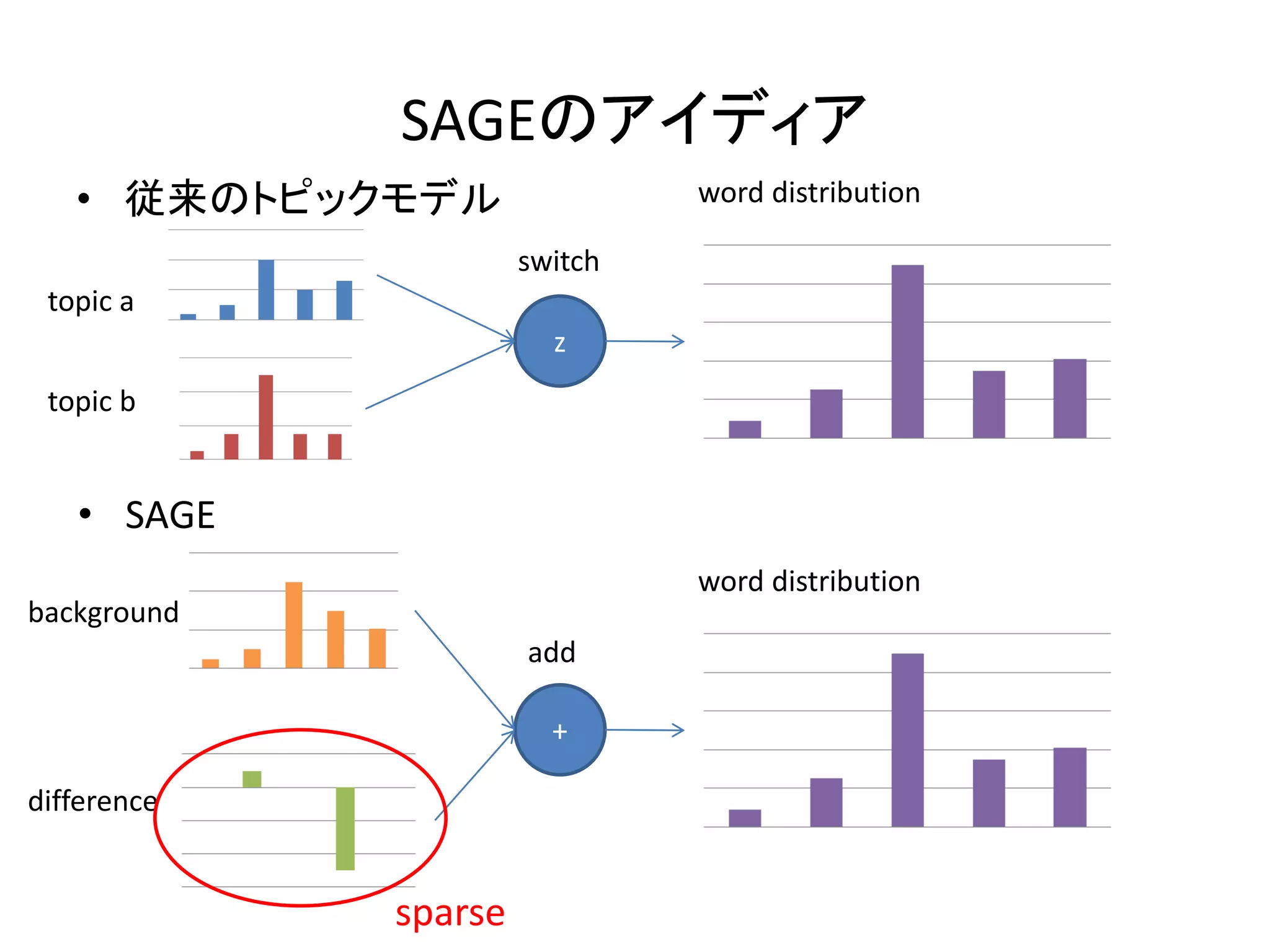
8.
SAGEのアイディア
• 従来のトピックモデル word distribution switch topic a z topic b • SAGE word distribution background add + difference sparse
9.
単語の出現確率モデル • background distribution
: ∈ • component vectors : * ∈ + – ここで添字は文章のラベルに対応しているとする • 文章における単語の出現確率を以下のようにモデル化する , , ∝ exp( + ) • ラベルが既知のときはNaive Bayesモデルに対応し • 未知の時は混合unigramモデルに対応する
10.
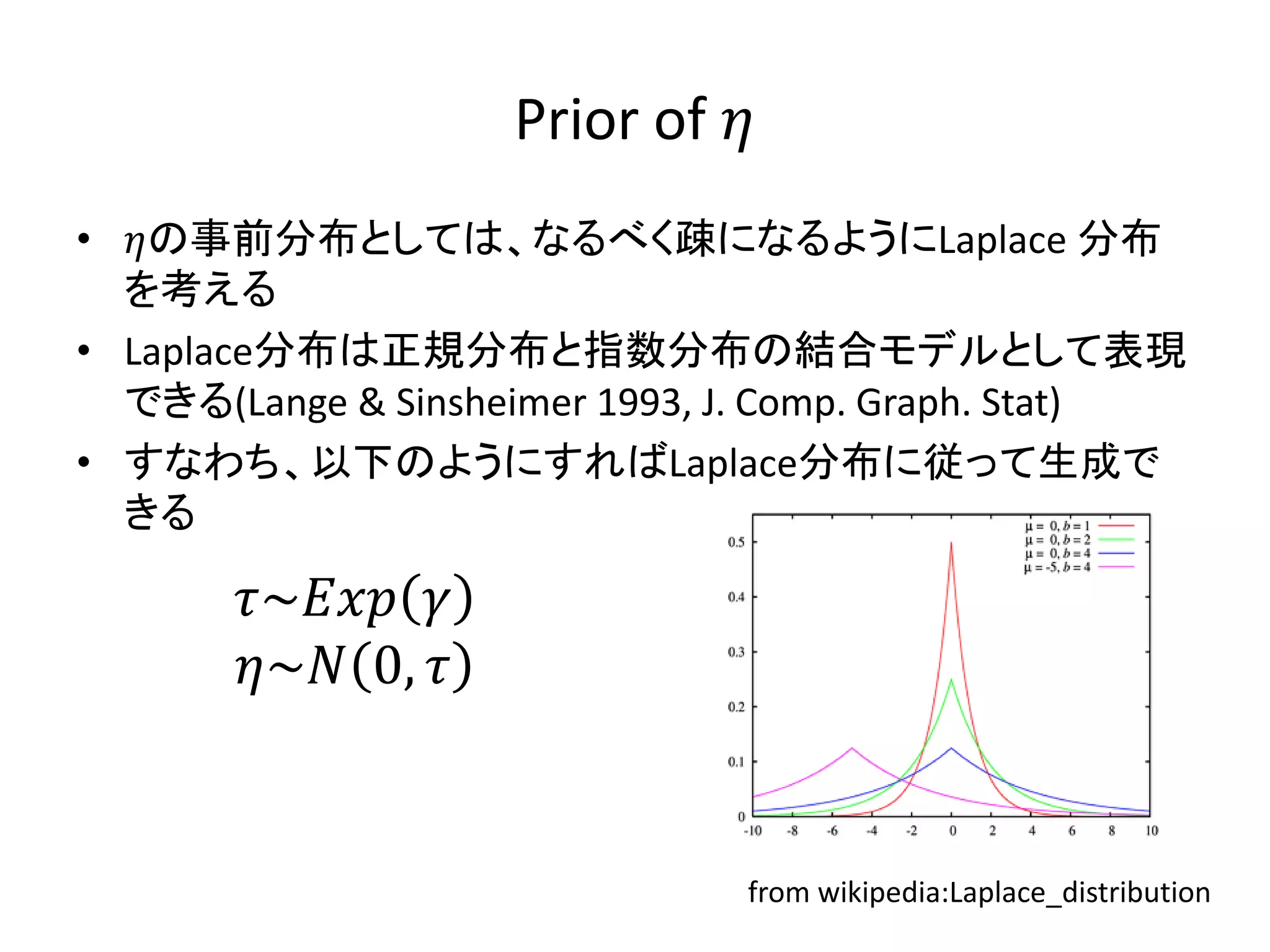
Prior of •
の事前分布としては、なるべく疎になるようにLaplace 分布 を考える • Laplace分布は正規分布と指数分布の結合モデルとして表現 できる(Lange & Sinsheimer 1993, J. Comp. Graph. Stat) • すなわち、以下のようにすればLaplace分布に従って生成で きる ~ ~ 0, from wikipedia:Laplace_distribution
11.
SAGEによるNBモデル • ラベル既知の文章における生成モデルは以下のように表さ
れる , ∼ (0, )と等価
12.
変分ベイズによる推定 • パラメータに関しては事後分布(|, ,
)をなるべく近似 するような変分分布()を求める • これは以下の変分下限を最大化することによって得られる – ここで<・>は変分分布で期待値をとることを意味する • またに関してはMAP推定により最適化する
13.
inference of •
変分下限の に関する項のみ抜き出すと = − log exp( + ) (|, )の部分 : = − diag < −1 > /2 (|)の部分 • : 文章dの単語頻度ベクトル • = : の要素の合計 • = : = : ラベルが付いた文章ベクトルの和 • = : の要素の合計
14.
inference of •
( )の勾配を求めると = − − diag < −1 > • 最適化にはNewton法を使うためHessianを計算すると 2 2 2 = − 1 −< >, = ( ) = − diag +< −1 >
15.
inference of •
Hessianの逆行列はSherman-Morrison公式を使って効率的 に計算でき、ニュートン方向は以下のようになる −1 = − 1 + −Δ = −1 = − ( ) 1 + −1 = diag − +< −1 > ( ) =
16.
inference of •
まず変分分布が次のように書けることを仮定する = ( ) • また はガンマ分布に従うとする、すなわち exp(− ) = , = −1 Γ • 期待値の性質として −1 < > = , < −1 > = − 1 , < log > = + log
17.
inference of •
(正確には だが簡単のため添字は省略)に関する項を抜 き出すと • に関するニュートン方向との解析解は
18.
inference of •
前述の更新式では指数分布のパラメータであるを決定する という問題が残る • このための事前分布として無情報事前分布であるinproper Jeffery’s prior ∝ 1/を採用する • この場合でもSparse性がある(Guan & Dy 2009, AISTATS) • このときのに関するニュートン方向との解析解は −2 • このとき、の推論に必要な< −1 >は< −1 > = となる
19.
Application: 文章分類 • 20
Newsgroups データセットを使って、評価を行った – http://people.csail.mit.edu/jrennie/20Newsgroups/ • ベースラインアルゴリズムとして、Dirichlet事前分布をいれたNB分 類器を用いる (Diriclet分布のparameterはNewton法を使って最適 化する(Minka 2003) ) – 当然識別モデルなどを使ったほうが分類性能は高くなるが、ここでは Dirichlet-Multinomialな分布との比較が主眼であるため考慮しない • また、ストップワードの除去は行わず、語彙数は50000となる
20.
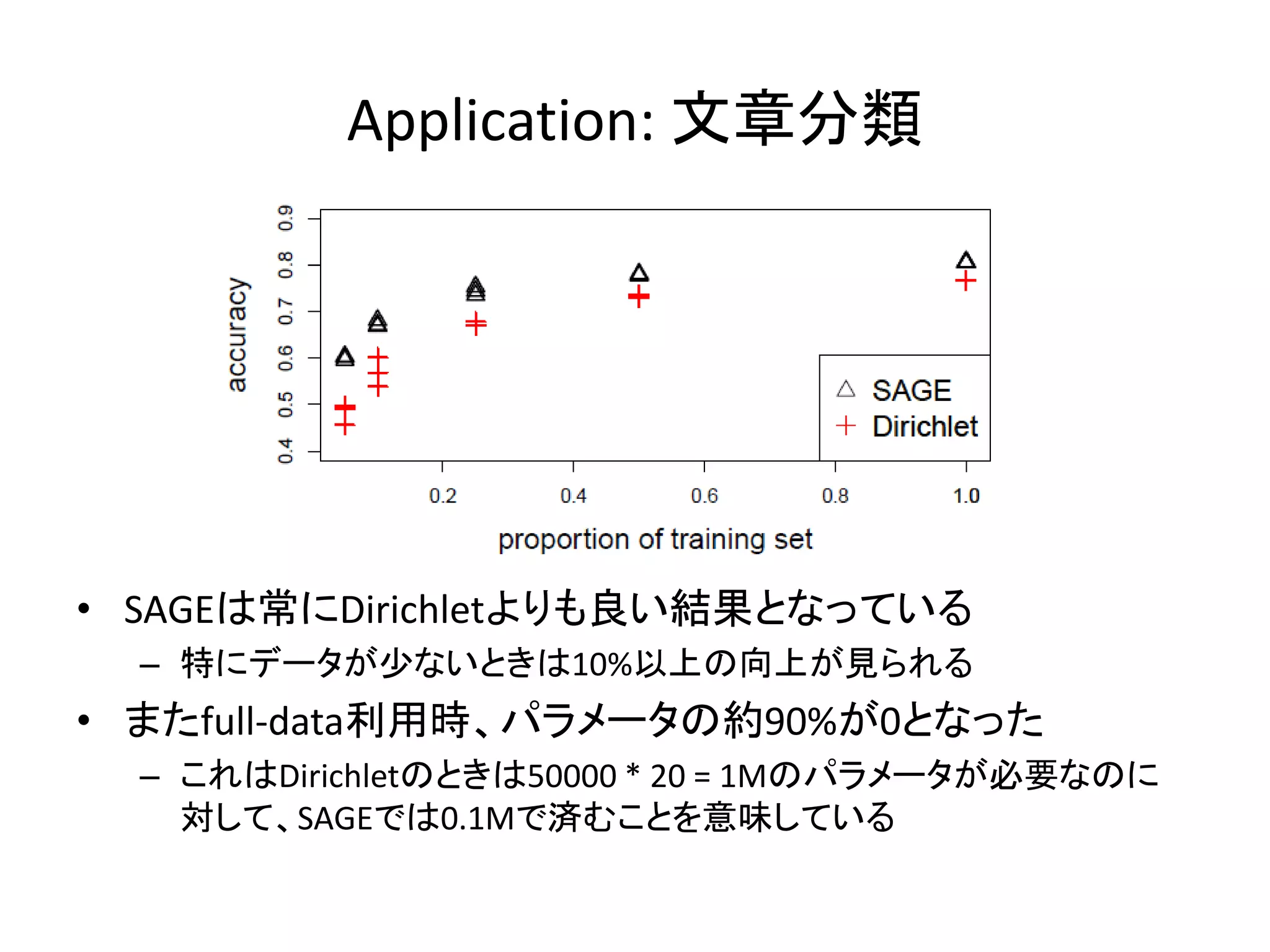
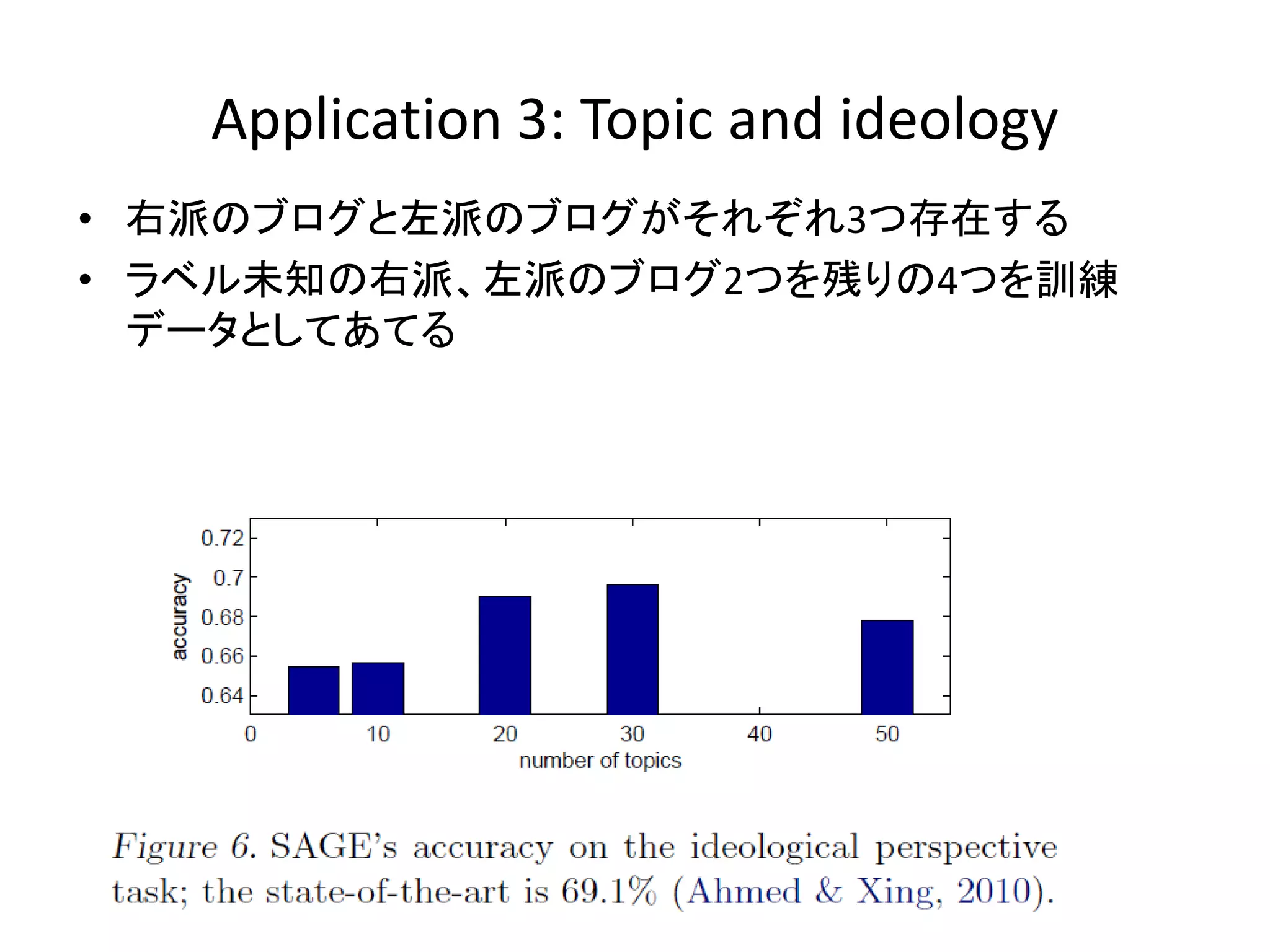
Application: 文章分類 • SAGEは常にDirichletよりも良い結果となっている
– 特にデータが尐ないときは10%以上の向上が見られる • またfull-data利用時、パラメータの約90%が0となった – これはDirichletのときは50000 * 20 = 1Mのパラメータが必要なのに 対して、SAGEでは0.1Mで済むことを意味している
21.
Latent Variable Models
• LDAと同様に以下のような文章生成モデルを考える • For each document – ∼ () () – For each () • sample topic ∼ ( ) () • sample word ∼ ( |, ) ( , ∝ exp( + ) ) cf. LDA(Blei+ 2003)
22.
Inference • 以下の変分下限を最適化する • ここでに関しては •
, , = ()と分解できることを仮定する • ここで , ()の変分推定の式はLDAと同じになる、また ()の推定は前述の導出と同じになる
23.
Estimation of •
ここでの推定の時に = 0となったら< >も動かなくな るため、Mステップでは複数回反復を行わず、一回だけ更新 を行う
24.
Application 2: Sparse
topic models • ベンチマークデータとしてNIPSデータセットを利用する • 文章の20%をテストデータとする • ストップワードの除去は行わない • perplexityを比較するとトピック数が多いときSAGEの方が小さくなる • またトピック数を10から50にしていったときパラメータの非ゼロ重みの数は 5%から1%へと減っている
25.
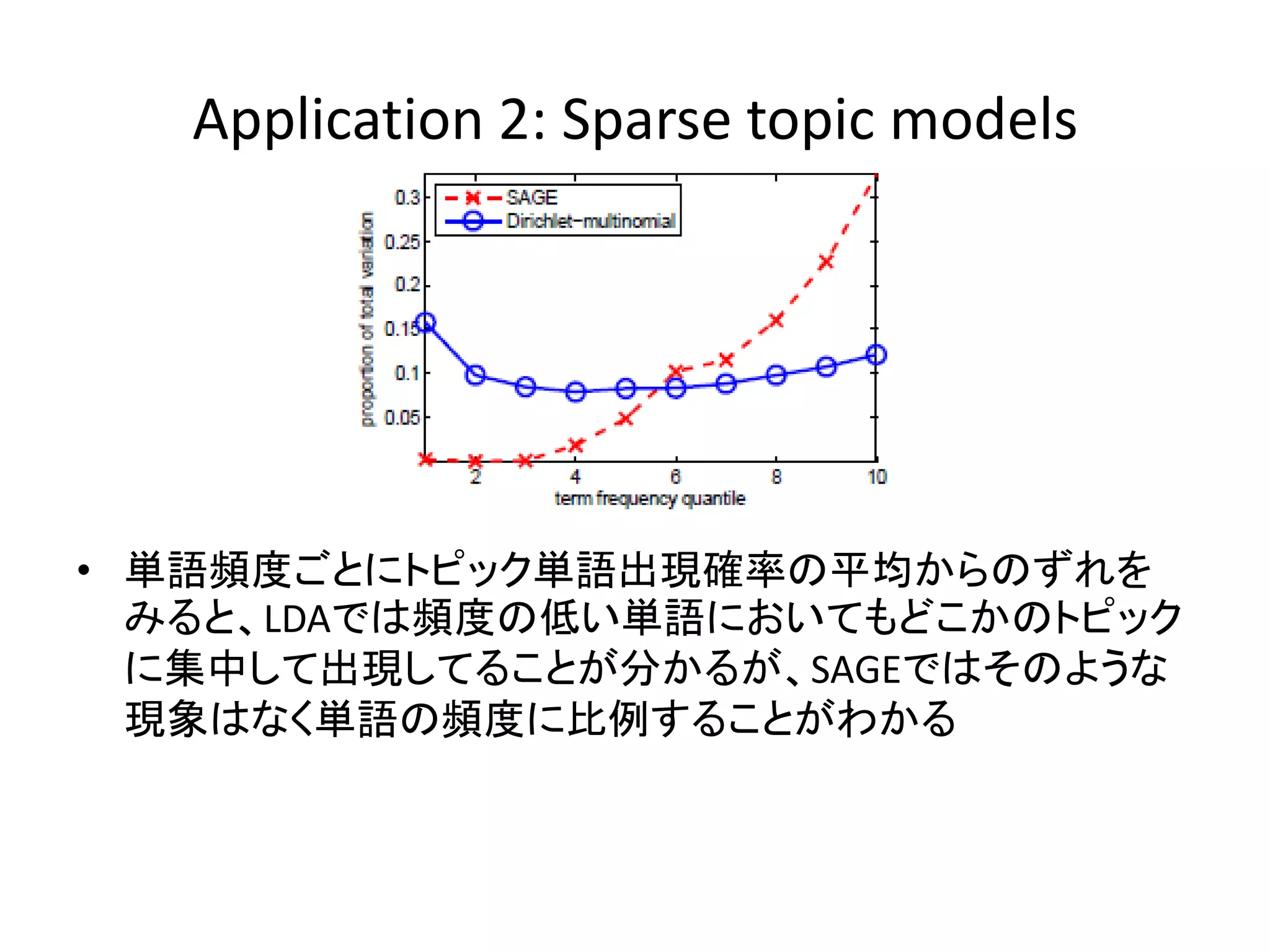
Application 2: Sparse
topic models • 単語頻度ごとにトピック単語出現確率の平均からのずれを みると、LDAでは頻度の低い単語においてもどこかのトピック に集中して出現してることが分かるが、SAGEではそのような 現象はなく単語の頻度に比例することがわかる
26.
Multifaceted generative models •
文章データは多くの場合単独で存在するわけではなく、レ ビューであれば評判情報や政治系のブログであれば支持政 党などの情報が付随している • このような複数の側面(Multi faceted)をもつデータに対して SAGEは有効に働く
27.
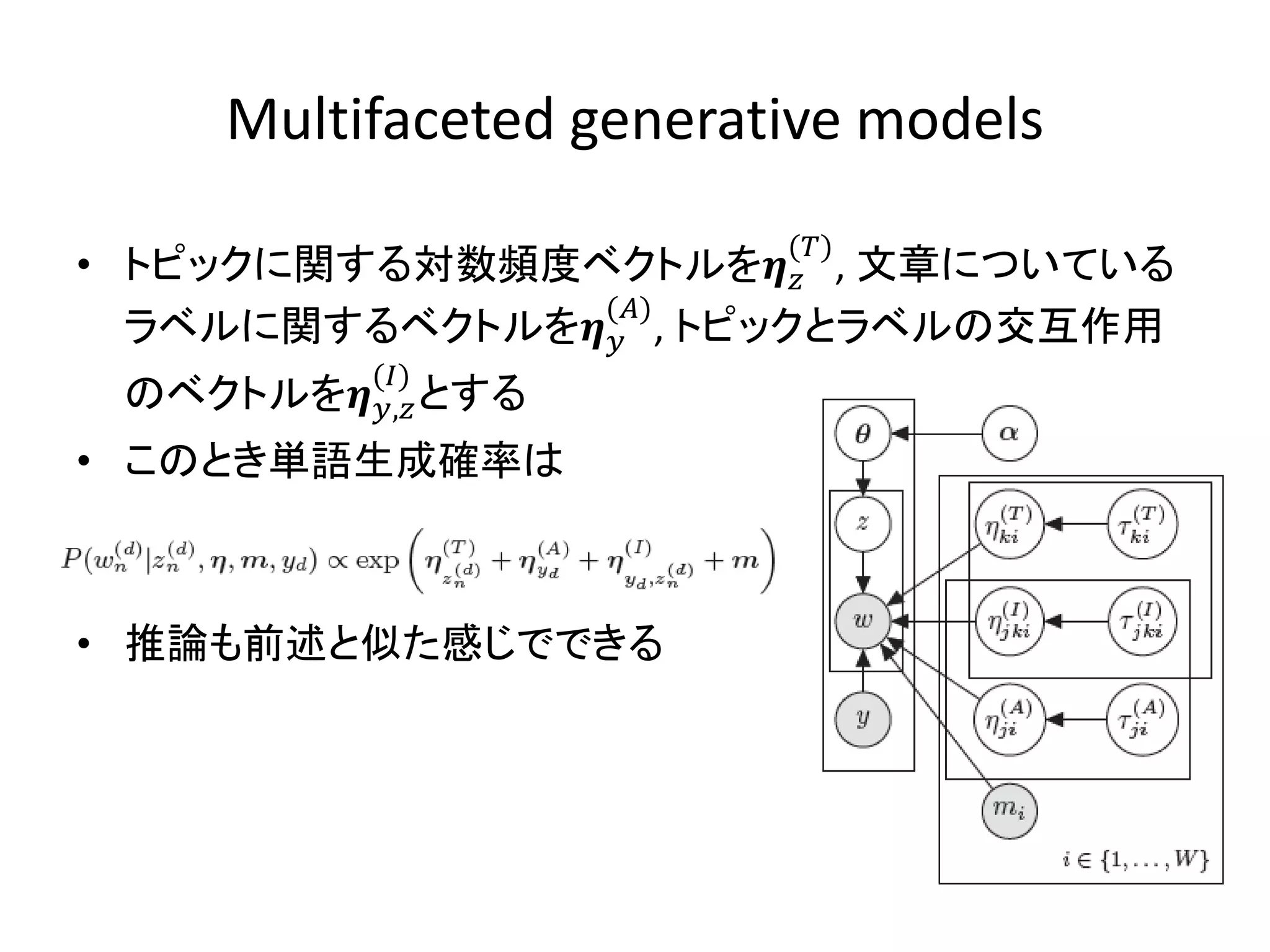
Multifaceted generative models
() • トピックに関する対数頻度ベクトルを , 文章についている () ラベルに関するベクトルを , トピックとラベルの交互作用 () のベクトルを, とする • このとき単語生成確率は • 推論も前述と似た感じでできる
28.
Application 3: Topic
and ideology • 右派のブログと左派のブログがそれぞれ3つ存在する • ラベル未知の右派、左派のブログ2つを残りの4つを訓練 データとしてあてる
29.
Application 4: Geolocation
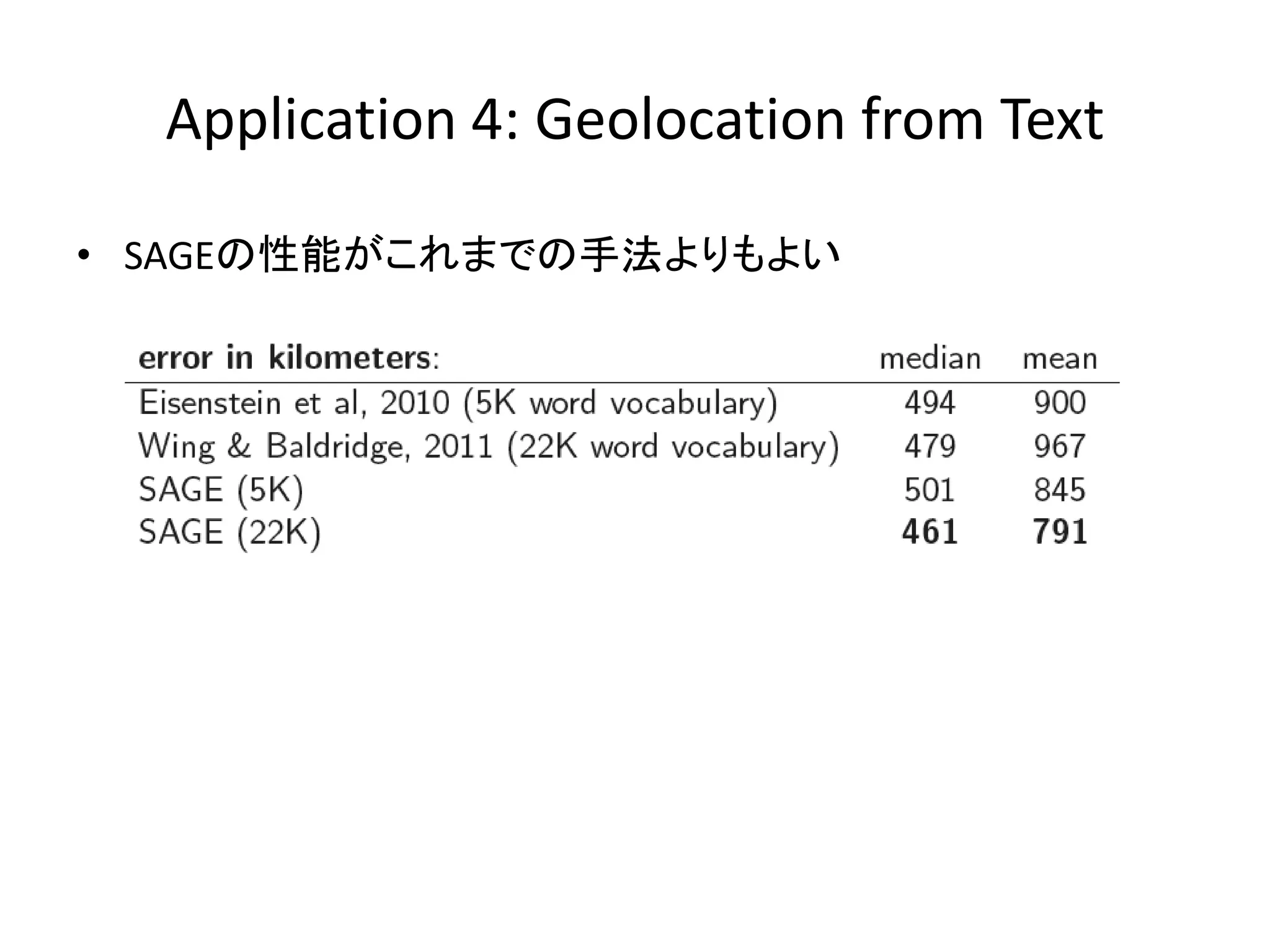
from Text • 文章および位置情報が与えられたときのトピックモデル – 隠れ変数として”region”があり、そこから文章と位置が生成される – 実験にはtwitterのテキストデータと位置情報を利用 [Eisenstein+ 2010, EMNLP]
30.
Application 4: Geolocation
from Text • SAGEの性能がこれまでの手法よりもよい
31.
Conclusion • 離散データのためのSAGEという新しいモデルを提案した • SAGEをNB分類器、トピックモデルに適応することにより、より
尐数の単語により表現されるシンプルなモデルが学習できる ことを示した • 複数の側面を持つ生成モデルにも適応を行った • 今後はより複雑なモデルである階層トピックモデル, 混合効 果モデルなどへの適応を考えたい
Download




















![Application 4: Geolocation from Text
• 文章および位置情報が与えられたときのトピックモデル
– 隠れ変数として”region”があり、そこから文章と位置が生成される
– 実験にはtwitterのテキストデータと位置情報を利用
[Eisenstein+ 2010, EMNLP]](https://image.slidesharecdn.com/icml2011-reading-sage-110715105023-phpapp01/75/Icml2011-reading-sage-29-2048.jpg)
















![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

















































