Downloaded 12 times







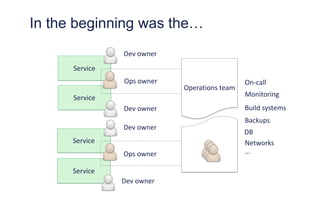






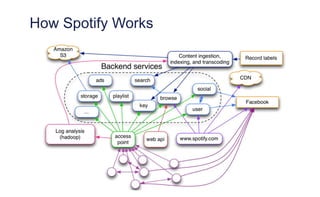
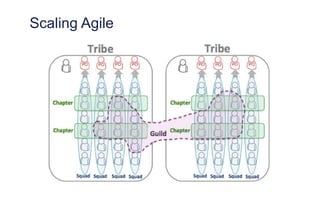
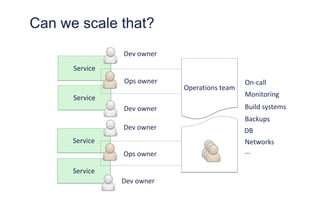



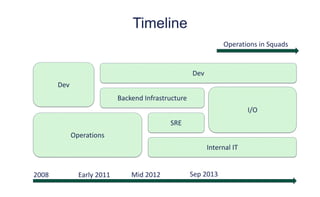
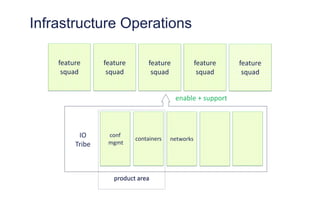



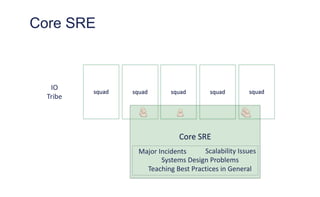

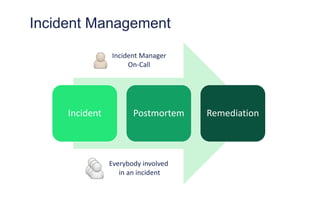






The document outlines the evolution of operations engineering at Spotify, highlighting significant growth since 2011, with the operations team now supporting over 60 million users and numerous services. It emphasizes the importance of a squad-based structure, aiming for autonomy and efficiency in addressing operations alongside development. Areas for improvement are identified, including unclear expectations and communication challenges between teams.


































![[Russian] Team Canvas + On Culture and Teams](https://cdn.slidesharecdn.com/ss_thumbnails/ttc-russiankey-160629134954-thumbnail.jpg?width=640&height=640&fit=bounds)
































































