Downloaded 423 times







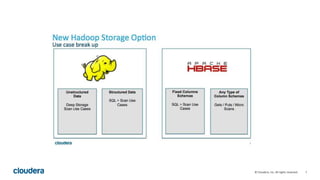

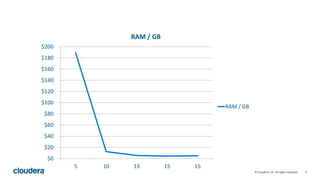
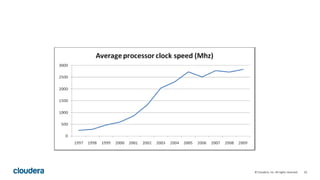


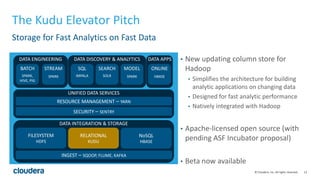

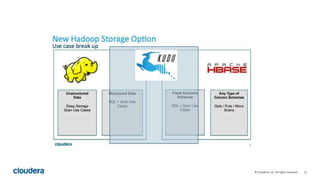





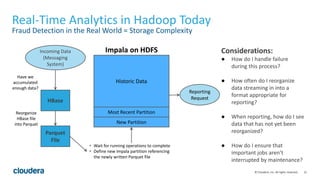
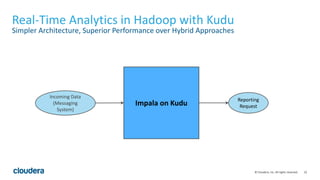


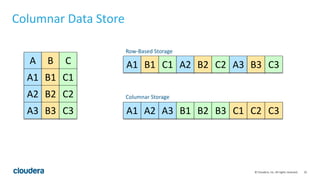


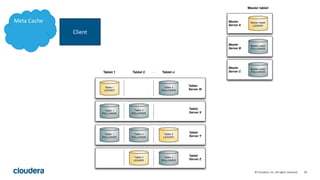
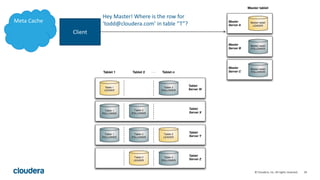
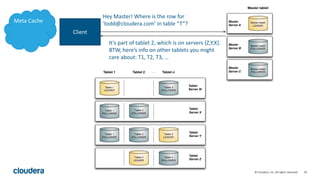
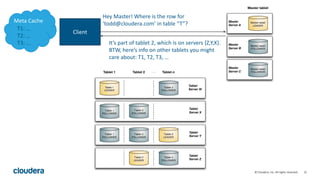
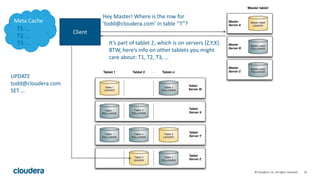




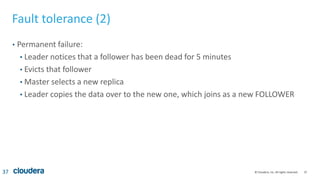


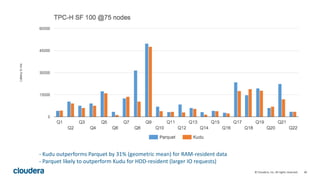
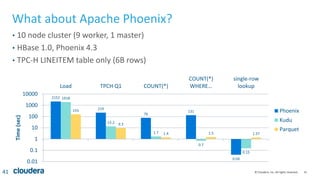
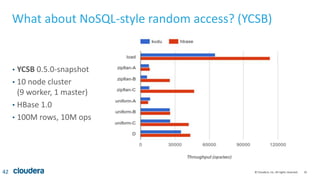

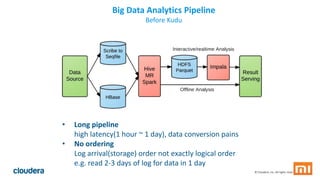
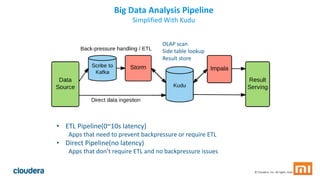

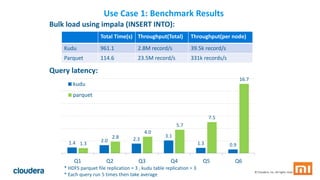










Kudu is a storage engine for Hadoop designed to address gaps in Hadoop's ability to handle workloads that require both high-throughput data ingestion and low-latency random access. It is a columnar storage engine that uses a log-structured merge tree to store data and provides APIs for NoSQL and SQL access. Kudu aims to provide high performance for both scans and random access through its columnar design and tablet architecture that partitions data across servers.















































































