Downloaded 680 times



















![35© Cloudera, Inc. All rights reserved.
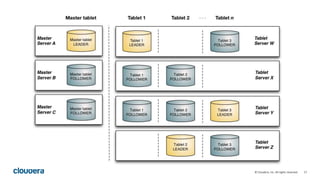
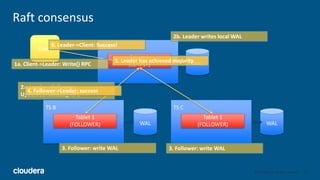
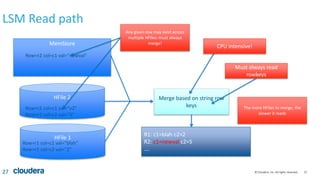
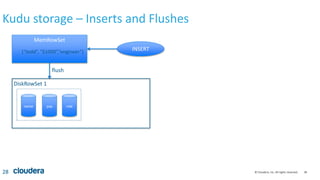
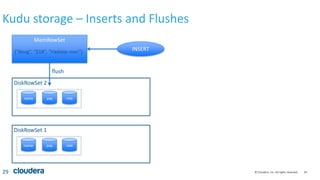
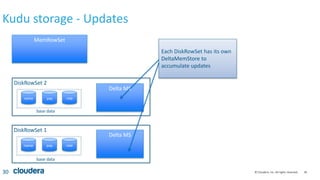
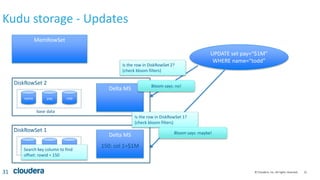
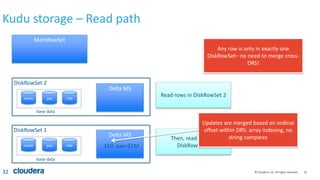
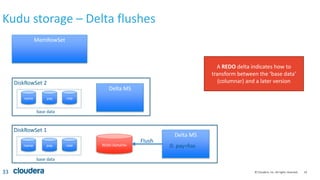
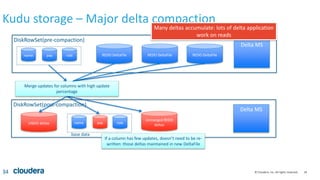
Kudu storage – RowSet Compactions
35
DRS 1 (32MB)
[PK=alice], [PK=joe], [PK=linda], [PK=zach]
DRS 2 (32MB)
[PK=bob], [PK=jon], [PK=mary] [PK=zeke]
DRS 3 (32MB)
[PK=carl], [PK=julie], [PK=omar] [PK=zoe]
DRS 4 (32MB) DRS 5 (32MB) DRS 6 (32MB)
[alice, bob, carl,
joe]
[jon, julie, linda,
mary]
[omar, zach, zeke,
zoe]
Reorganize rows to avoid rowsets
with overlapping key ranges](https://image.slidesharecdn.com/kudunychugsep2015-151012220649-lva1-app6891/85/Kudu-New-Hadoop-Storage-for-Fast-Analytics-on-Fast-Data-35-320.jpg)




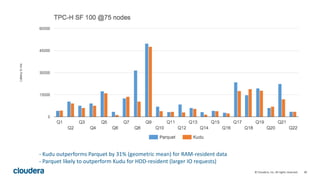
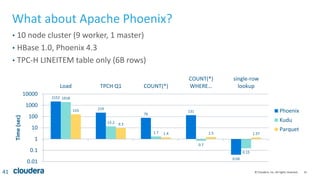
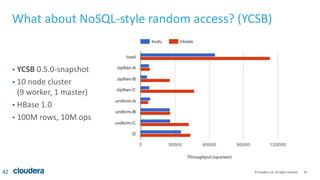








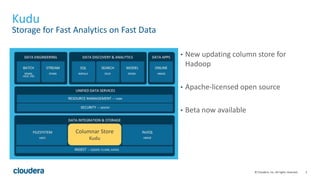
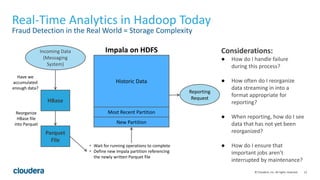
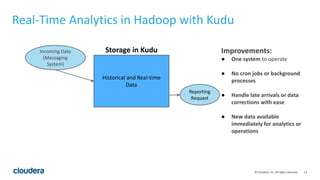
The document discusses Kudu, an open source storage system for Hadoop that is designed to enable both transactional and analytic workloads. Kudu uses a columnar storage format and provides ACID transactions for fast analytics on fast data. It aims to address gaps in Hadoop for workloads that require simultaneous random access and scanning of data. Benchmarks show Kudu can perform TPC-H queries within 2x of Parquet storage, with low latency for reads and writes on solid state drives.







































































































