Download to read offline






![Start with local mode first
Use only one instance in cluster, submit your jar with this:
/home/hadoop/spark/bin/spark-submit
--class com.adform.dspr.SimilarityJob
--master local[16]
--driver-memory 4G
--conf spark.default.parallelism=112
SimilarityJob.jar
--remote
--input s3://adform-dsp-warehouse/data/facts/impressions/dt=20150109/*
--output s3://dev-adform-data-engineers/tmp/spark/2days
--similarity-threshold 300](https://image.slidesharecdn.com/sparkintro-150226141658-conversion-gate01/85/Spark-intro-by-Adform-Research-8-320.jpg)



![Spark shell
/home/hadoop/spark/bin/spark-shell
--master <yarn|local[*]>
--deploy-mode client
--num-executors 7
--executor-memory 4G
--executor-cores 16
--driver-memory 4G
--conf spark.default.parallelism=112
--conf spark.task.maxFailures=4](https://image.slidesharecdn.com/sparkintro-150226141658-conversion-gate01/85/Spark-intro-by-Adform-Research-13-320.jpg)
![Spark shell
• In spark shell you don’t need to instantiate spark context, it is already
intantiated, but you can create another one if you like
• Type scala expressions and see what is happening
• Note the lazy evaluation, to force expression evaluation fore
debugging use action functions like [expression].take(n) or
[expression].count to see if your statements are OK](https://image.slidesharecdn.com/sparkintro-150226141658-conversion-gate01/85/Spark-intro-by-Adform-Research-14-320.jpg)


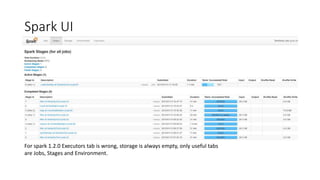
Spark is well-suited for interactive data analysis and machine learning workloads. It can be developed locally in an IDE or the Spark shell before deploying to EMR. When deploying, build a fat JAR, upload it to S3, and run a bootstrap script to install and configure Spark on the cluster before submitting jobs with Spark's APIs. The Spark UI and Ganglia monitoring are useful for debugging jobs running on EMR.