Downloaded 17 times








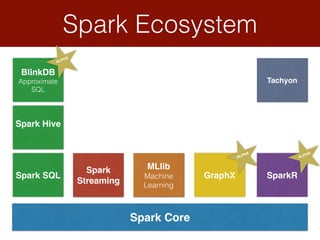


![RDD Word Count
val sc = new SparkContext()
val input: RDD[String] = sc.textFile("/tmp/word.txt")
val words: RDD[(String, Long)] = input
.flatMap(line => line.toLowerCase.split("s+"))
.map(word => word -> 1L)
.cache()
val wordCountsRdd: RDD[(String, Long)] = words
.reduceByKey(_ + _)
.sortByKey()
val wordCounts: Array[(String, Long)] = wordCountsRdd.collect()](https://image.slidesharecdn.com/sparkintroscalaug-150326162834-conversion-gate01/85/Intro-to-Apache-Spark-12-320.jpg)
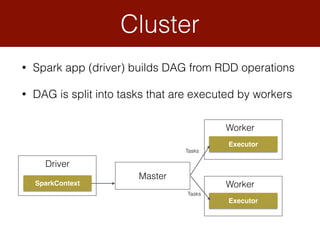
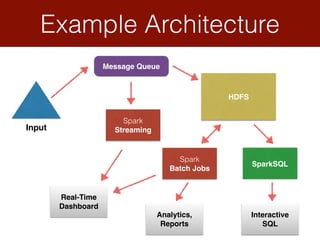


Spark is a framework for clustered in-memory data processing. It was developed at UC Berkeley and is now an Apache top-level project. Spark uses cluster-wide memory to speed up computations on large data. The core abstraction in Spark is the resilient distributed dataset (RDD), which acts as a fault-tolerant collection of objects across a cluster. Spark also provides APIs for batch processing, streaming, SQL, machine learning, and graph processing.





























































![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)