株式会社ブレインパッドが行ったApache Sparkのパフォーマンス検証作業に関する資料です。詳細は、ブレインパッド公式ブログ「Platinum Data Blog」をご覧ください。URL:http://blog.brainpad.co.jp/










![Copyright © BrainPad Inc. All Rights Reserved. 15
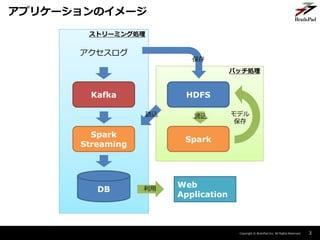
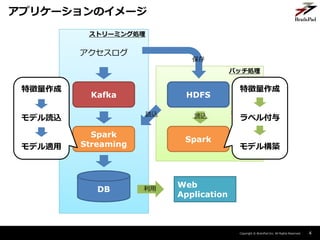
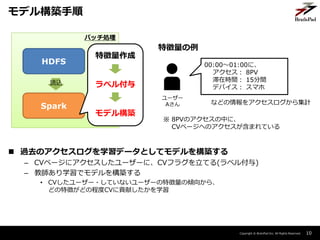
ストリーミング処理での特徴量作成
ストリーミング処理
アクセスログ
Kafka
Spark
Streaming
DB
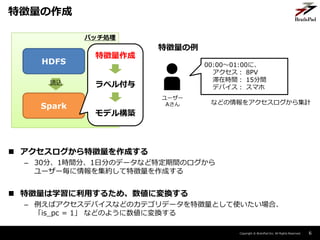
特徴量作成
モデル読込
モデル適用
Window集計
– 間隔・期間を指定して実行する集計
• 5分毎に30分間のログを集計など
– 01:00 に 00:30 ~ 01:00 のデータ集計
– 01:05 に 00:35 ~ 01:05 のデータ集計
– ストリーミング処理では
Window集計で特徴量を作成する
// streams: DStream[String]
val userSessionData = streams.window(
windowDuration = Minutes(5),
slideDuration = Minutes(30)
).map { line =>
// 特徴量作成
}](https://image.slidesharecdn.com/spark-application-150529040219-lva1-app6891/85/Spark-15-320.jpg)
![Copyright © BrainPad Inc. All Rights Reserved.
保存されたモデルを適宜読み込んで適用
17
モデルの保存と読み込み
val is = new ObjectInputStream(fs.open(modelFilePath))
val model = is.readObject().asInstanceOf[LogisticRegressionModel]
// 結果を0,1ではなく、スコアで出力
model.clearThreshold()
// 学習の際には LabeledPoint を利用したが、
// モデル適用の際にはラベル付与されていない特徴量を利用
val predictions = userSessionData.map{ case (key, features) =>
(key, model.predict(features))
}](https://image.slidesharecdn.com/spark-application-150529040219-lva1-app6891/85/Spark-17-320.jpg)





































































![[db tech showcase Tokyo 2014] B22: Hadoop Rush!! HDFSからデータを自在に取得、加工するにはどうする? ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b22hadooprushhdfs-141119235245-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




















