Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Sotaro Kimura
PPTX, PDF
833 views
Spark Structured Streaming with Kafka
Hadoopソースコードリーディング 第24回での発表資料
Engineering
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Downloaded 11 times
1
/ 33
2
/ 33
3
/ 33
4
/ 33
5
/ 33
6
/ 33
7
/ 33
8
/ 33
9
/ 33
10
/ 33
11
/ 33
12
/ 33
13
/ 33
14
/ 33
15
/ 33
16
/ 33
17
/ 33
18
/ 33
19
/ 33
20
/ 33
21
/ 33
22
/ 33
23
/ 33
24
/ 33
25
/ 33
26
/ 33
27
/ 33
28
/ 33
29
/ 33
30
/ 33
31
/ 33
32
/ 33
33
/ 33
More Related Content
PPTX
Modern stream processing by Spark Structured Streaming
by
Sotaro Kimura
PPTX
Spark Structured StreamingでKafkaクラスタのデータをお手軽活用
by
Sotaro Kimura
PDF
利用者主体で行う分析のための分析基盤
by
Sotaro Kimura
PDF
最近のストリーム処理事情振り返り
by
Sotaro Kimura
PPTX
スキーマ 付き 分散ストリーム処理 を実行可能な FlinkSQLClient の紹介
by
Sotaro Kimura
PDF
シンプルでシステマチックな Linux 性能分析方法
by
Yohei Azekatsu
PPTX
Kafkaを活用するためのストリーム処理の基本
by
Sotaro Kimura
PDF
性能測定道 実践編
by
Yuto Hayamizu
Modern stream processing by Spark Structured Streaming
by
Sotaro Kimura
Spark Structured StreamingでKafkaクラスタのデータをお手軽活用
by
Sotaro Kimura
利用者主体で行う分析のための分析基盤
by
Sotaro Kimura
最近のストリーム処理事情振り返り
by
Sotaro Kimura
スキーマ 付き 分散ストリーム処理 を実行可能な FlinkSQLClient の紹介
by
Sotaro Kimura
シンプルでシステマチックな Linux 性能分析方法
by
Yohei Azekatsu
Kafkaを活用するためのストリーム処理の基本
by
Sotaro Kimura
性能測定道 実践編
by
Yuto Hayamizu
What's hot
PDF
db tech showcase_2014_A14_Actian Vectorで得られる、BIにおける真のパフォーマンスとは
by
Koji Shinkubo
PDF
DeltaCubeにおけるユニークユーザー集計高速化(実践編)
by
BrainPad Inc.
PDF
Presto As A Service - Treasure DataでのPresto運用事例
by
Taro L. Saito
PDF
「Oracle Database + Java + Linux」 環境における性能問題の調査手法 ~ミッションクリティカルシステムの現場から~ Part.1
by
Shogo Wakayama
PDF
性能測定道 事始め編
by
Yuto Hayamizu
PPTX
Dbts2012 unconference wttrw_yazekatsu_publish
by
Yohei Azekatsu
PDF
シンプルでシステマチックな Oracle Database, Exadata 性能分析
by
Yohei Azekatsu
PDF
簡単!AWRをEXCELピボットグラフで分析しよう♪
by
Yohei Azekatsu
PPTX
EmbulkとDigdagとデータ分析基盤と
by
Toru Takahashi
PDF
Re:dash Use Cases at iPROS
by
Jumpei Yokota
PDF
噛み砕いてKafka Streams #kafkajp
by
Yahoo!デベロッパーネットワーク
PDF
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
PPTX
Amazon Redshiftの開発者がこれだけは知っておきたい10のTIPS / 第18回 AWS User Group - Japan
by
Koichi Fujikawa
PDF
スキーマつきストリーム データ処理基盤、 Confluent Platformとは?
by
Sotaro Kimura
PDF
ISUCON夏期講習2015_2 実践編
by
SATOSHI TAGOMORI
PDF
Gearpump, akka based Distributed Reactive Realtime Engine
by
Sotaro Kimura
PDF
Logをs3とredshiftに格納する仕組み
by
Ken Morishita
PDF
Embulkを活用したログ管理システム
by
Akihiro Ikezoe
PDF
hscj2019_ishizaki_public
by
Kazuaki Ishizaki
PDF
Tez on EMRを試してみた
by
Satoshi Noto
db tech showcase_2014_A14_Actian Vectorで得られる、BIにおける真のパフォーマンスとは
by
Koji Shinkubo
DeltaCubeにおけるユニークユーザー集計高速化(実践編)
by
BrainPad Inc.
Presto As A Service - Treasure DataでのPresto運用事例
by
Taro L. Saito
「Oracle Database + Java + Linux」 環境における性能問題の調査手法 ~ミッションクリティカルシステムの現場から~ Part.1
by
Shogo Wakayama
性能測定道 事始め編
by
Yuto Hayamizu
Dbts2012 unconference wttrw_yazekatsu_publish
by
Yohei Azekatsu
シンプルでシステマチックな Oracle Database, Exadata 性能分析
by
Yohei Azekatsu
簡単!AWRをEXCELピボットグラフで分析しよう♪
by
Yohei Azekatsu
EmbulkとDigdagとデータ分析基盤と
by
Toru Takahashi
Re:dash Use Cases at iPROS
by
Jumpei Yokota
噛み砕いてKafka Streams #kafkajp
by
Yahoo!デベロッパーネットワーク
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
Amazon Redshiftの開発者がこれだけは知っておきたい10のTIPS / 第18回 AWS User Group - Japan
by
Koichi Fujikawa
スキーマつきストリーム データ処理基盤、 Confluent Platformとは?
by
Sotaro Kimura
ISUCON夏期講習2015_2 実践編
by
SATOSHI TAGOMORI
Gearpump, akka based Distributed Reactive Realtime Engine
by
Sotaro Kimura
Logをs3とredshiftに格納する仕組み
by
Ken Morishita
Embulkを活用したログ管理システム
by
Akihiro Ikezoe
hscj2019_ishizaki_public
by
Kazuaki Ishizaki
Tez on EMRを試してみた
by
Satoshi Noto
Similar to Spark Structured Streaming with Kafka
PDF
Discretized Streams: Fault-Tolerant Streaming Computation at Scaleの解説
by
Katsunori Kanda
PDF
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
PPTX
StreamGraph
by
Altech Takeno
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
PDF
Sparkのクエリ処理系と周辺の話題
by
Takeshi Yamamuro
PDF
Spark Streaming の基本とスケールする時系列データ処理 - Spark Meetup December 2015/12/09
by
MapR Technologies Japan
PDF
Dataworks Summit 2017 SanJose StreamProcessing - Hadoop Source Code Reading #...
by
Yahoo!デベロッパーネットワーク
PDF
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
PPT
Asakusa Enterprise Batch Processing Framework for Hadoop
by
Takashi Kambayashi
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
PDF
Sparkストリーミング検証
by
BrainPad Inc.
PDF
マイニング探検会#10
by
Yoji Kiyota
PDF
Azure データサービスデザイン検討 (2015/10)
by
Koichiro Sasaki
PDF
Strem処理(Spark Streaming + Kinesis)とOffline処理(Hive)の統合
by
SmartNews, Inc.
PDF
Java8 Stream APIとApache SparkとAsakusa Frameworkの類似点・相違点
by
hishidama
PDF
Scalaz-StreamによるFunctional Reactive Programming
by
Tomoharu ASAMI
PDF
A Deeper Understanding of Spark Internals (Hadoop Conference Japan 2014)
by
Hadoop / Spark Conference Japan
PPTX
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
PDF
SAIS/SIGMOD参加報告 in SAIS/DWS2018報告会@Yahoo! JAPAN
by
Yahoo!デベロッパーネットワーク
Discretized Streams: Fault-Tolerant Streaming Computation at Scaleの解説
by
Katsunori Kanda
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
StreamGraph
by
Altech Takeno
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
Sparkのクエリ処理系と周辺の話題
by
Takeshi Yamamuro
Spark Streaming の基本とスケールする時系列データ処理 - Spark Meetup December 2015/12/09
by
MapR Technologies Japan
Dataworks Summit 2017 SanJose StreamProcessing - Hadoop Source Code Reading #...
by
Yahoo!デベロッパーネットワーク
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
Asakusa Enterprise Batch Processing Framework for Hadoop
by
Takashi Kambayashi
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
Sparkストリーミング検証
by
BrainPad Inc.
マイニング探検会#10
by
Yoji Kiyota
Azure データサービスデザイン検討 (2015/10)
by
Koichiro Sasaki
Strem処理(Spark Streaming + Kinesis)とOffline処理(Hive)の統合
by
SmartNews, Inc.
Java8 Stream APIとApache SparkとAsakusa Frameworkの類似点・相違点
by
hishidama
Scalaz-StreamによるFunctional Reactive Programming
by
Tomoharu ASAMI
A Deeper Understanding of Spark Internals (Hadoop Conference Japan 2014)
by
Hadoop / Spark Conference Japan
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
SAIS/SIGMOD参加報告 in SAIS/DWS2018報告会@Yahoo! JAPAN
by
Yahoo!デベロッパーネットワーク
More from Sotaro Kimura
PPTX
Custom management apps for Kafka
by
Sotaro Kimura
PDF
Kinesis Analyticsの適用できない用途と、Kinesis Firehoseの苦労話
by
Sotaro Kimura
PDF
Stream dataprocessing101
by
Sotaro Kimura
PPTX
Apache NiFiと 他プロダクトのつなぎ方
by
Sotaro Kimura
PPTX
Hadoop基盤上のETL構築実践例 ~多様なデータをどう扱う?~
by
Sotaro Kimura
PPTX
JVM上でのストリーム処理エンジンの変遷
by
Sotaro Kimura
PDF
リアルタイム処理エンジン Gearpumpの紹介
by
Sotaro Kimura
Custom management apps for Kafka
by
Sotaro Kimura
Kinesis Analyticsの適用できない用途と、Kinesis Firehoseの苦労話
by
Sotaro Kimura
Stream dataprocessing101
by
Sotaro Kimura
Apache NiFiと 他プロダクトのつなぎ方
by
Sotaro Kimura
Hadoop基盤上のETL構築実践例 ~多様なデータをどう扱う?~
by
Sotaro Kimura
JVM上でのストリーム処理エンジンの変遷
by
Sotaro Kimura
リアルタイム処理エンジン Gearpumpの紹介
by
Sotaro Kimura
Spark Structured Streaming with Kafka
1.
Spark Structured Streaming
with Kafka Hadoopソースコードリーディング 第24回 Kimura, Sotaro(@kimutansk)
2.
自己紹介 • Kimura, Sotaro(@kimutansk) –
データエンジニア雑用係 @ ドワンゴ • オンプレ~クラウド、インフラ~個別機能 • バッチ~ストリーム、開発~プロマネ – すなわち雑用係 – 好きな技術分野 • ストリーム処理(主にJVM上) • 分散システム – ストリーム処理で最近やらかした失敗 • Spark StreamingをSSH接続>起動して 実行ツールのセッション切れてログロスト
3.
本資料の前提 • 本資料の内容は Logical Planの流れを確認して作成しているため、 Physical
Planに変換した場合に成り立たないケース もあります。 – Logical > Physicalへの変換について詳しい方が いらっしゃったら適宜補足をいただけると・・・
4.
アジェンダ • Spark Structured
Streamingとは? • Spark Structured Streamingの用語 • Spark Strucutred Streamingの実行の流れ • Kakfa用コンポーネントの構成
5.
Spark Strucutred Streamingとは?
6.
Spark Structured Streamingとは? •
Spark SQL上でストリーム処理アプリケーションを 簡単に組むためのコンポーネント – Spark2.2系でProduction Ready! – バッチ処理と同様の方法でストリーム処理を記述可能 • バッチ処理で読み込んだデータとストリームのJoinも可能! – Scala/Java/PythonのDataset/DataFrame APIで記述 – Dataset/DataFrameを用いることで 構造化データとして最適化された状態で動作 • メモリ使用量の節約 • ベクトル演算によるCPUリソースの有効活用
7.
Spark Structured Streamingとは? •
注意点 – Spark Streamingと同様マイクロバッチ方式であり、 レコード単位で処理するストリーム処理ではない。 – Sparkの新実行エンジンDrizzleとは独立した別の機能 • https://github.com/amplab/drizzle-spark – Spark2.3.0で継続的に実行する方式についての提案も 挙がっているが、現状の進み具合から おそらくSpark2.3.0では無理? • [SPARK-20928] Continuous Processing Mode for Structured Streaming
8.
簡単なアプリケーション例 // Sparkアプリケーション生成 val spark
= SparkSession .builder .appName("StructuredNetworkWordCount") .getOrCreate() import spark.implicits._ // ローカルポート上にソケットを生成してデータを待ち受け val lines = spark.readStream .format("socket") .option("host", "localhost") .option("port", 9999) .load()
9.
簡単なアプリケーション例 // 入力データを単語毎に分割 val words
= lines.as[String].flatMap(_.split(" ")) // 入力単語毎にカウント val wordCounts = words.groupBy("value").count() // 集計結果を毎回すべてコンソールに出力するStreamingQueryを生成 val streamingQuery = wordCounts.writeStream .outputMode("complete") // 出力モードを指定 .format("console") .start() // アプリケーションが外部から停止されるまで実行 streamingQuery.awaitTermination()
10.
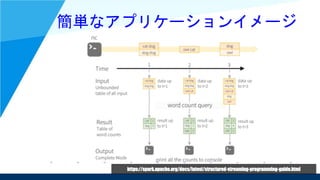
簡単なアプリケーションイメージ https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
11.
Spark Strucutred Streamingの用語
12.
用語説明(アプリケーション例) • Source – データの入力元 •
Sink – データの出力先 • Streaming Query – 1連の処理単位。出力先1つ、入力元1個以上持つ。 • Output Mode – Sinkへ出力する際の出力方式 • Append(結果を1回出力)/Complete(毎回全出力) Update(更新があった結果のみ出力)の3モードが存在
13.
用語説明(その他) • EventTime – データの時刻を示す値 通常はデータの特定カラムを用いるが、 処理タイミング(ProcessingTime)を用いることも可能 •
Offset – Sourceのどこまでを処理したか? を示す概念 • Checkpoint – Structured Streamingの実行状態を保存する先 – Query毎にパスを指定し、その場所に保存
14.
用語説明(その他) • Trigger – マイクロバッチを実行するタイミング制御 1回実行と、定期実行の指定が可能 •
Watermark – 遅れデータを除去するための機構 前回マイクロバッチ処理データのEventTimeが基準と • BatchId – マイクロバッチのシーケンス番号 初回が1で、1ずつインクリメントされる Checkpointから復旧した場合、引き継ぐ
15.
Spark Strucutred Streamingの実行の流れ
16.
実行の流れ(前提) • Sparkは以下の流れで実行されており、 Spark Strucured
Streamingも同様。 • マイクロバッチごとに以下が実行 – Code • アプリケーションコード – Logical Plan • アプリケーションコードから生成 • データの依存性グラフ – Physical Plan • Logical Planから生成 • 処理をStageに区切り、Partitionに分割してExecutor上で実行
17.
実行の流れ(概要) • マイクロバッチごとの処理は StreamExecutionクラスで起動 – StreamingQuery=Sink1個につき1インスタンス存在 –
各StreamingQueryの以下を実施 • 起動時の状態復旧 • Checkpointの管理 – Stateful Operatorの状態については除外 • マイクロバッチの定期起動 • Logical Planの生成 – Sourceの状態に応じたLogical Planの最適化も実施 • Watermarkの管理
18.
StreamExecutionの管理する状態 • StreamExecutionでは以下のCheckpointを管理 – Metadata •
初回起動時に割り振られるQueryの識別子 – Offset • Sourceのどこまでを処理したかを管理する状態値 • Source毎に形式は異なる • Offsetは自前で管理 – BatchCommitLog • どのBatchまで終了したかを管理する状態値 – ※StatefulOperatorの状態は直接管理しないため除外
19.
実行の流れ(StreamExecution) • StreamExecution#runBatchesで以下が実行 • 起動時、前回の状態を復旧 •
以下繰り返し(Trigger設定次第では1回のみ) – 次のマイクロバッチのLogical Planを作成 – 新規データがSourceに存在する場合のみ、バッチ実行 – バッチ実行時、完了済みとCheckpointを更新 – BatchIdをインクリメント
20.
実行の流れ(詳細:状態復旧) • StreamExecution#populateStartOffsetsで以下が実行 – BatchCommitLog最終値+1を次実行するBatchIdとして読込 –
OffsetLogの最終値を次のバッチの取得対象として読込 – OffsetLogの最終値-1をCommitしたOffsetとして読込 • 後述のように、 SourceへのCommitは「次のバッチ作成」時に行われるため、 「取得してない」か「取得したがCommitしてない」の扱い。 – OffsetLogの最終値=BatchCommitLogの最終値の場合 Sourceからデータの取得>破棄を実施。
21.
実行の流れ(詳細:状態復旧) • 「 Sourceからデータの取得>破棄」を行う理由 –
OffsetLogの最終値=BatchCommitLogの最終値の場合、 Spark側として処理完了したものの、 Sourceに対してCommitせずに完了したことを表すため。 • 繰り返しになるが、SourceへのCommitはSparkとして 処理完了したタイミングとは異なるタイミングで実施。 – Source側がCommitされたから復旧したケースを 考慮していると思われる。 • その場合、そのまま実行すると復旧した範囲を無視して、 その次のデータを読み込んでCommitという流れとなるため。
22.
実行の流れ(詳細:次バッチ作成) • StreamExecution#constructNextBatchで以下が実行 – Sourceから最新のOffsetを取得 –
新規データが存在した場合、Watermarkを更新 – 最新OffsetをOffsetLogに書込 – 前回バッチで処理したOffsetまでをSourceにcommit • 前述のように、 「該当のバッチが完了したタイミング」ではなく、 次のバッチ構築のタイミングでCommitを行っている。 – (※何故こうしているかはまだ読み取れていません)
23.
実行の流れ(詳細:次バッチ作成) – Watermarkの更新 • 前回のバッチ実行時の最新EventTime値
- Delay値を基準 – 以下のようなコードで指定可能 – 出力されるOffset値の形式 • Sourceに依存する。 Sourceコンポーネント側で生成。 – Kafkaについては後述。 – 保存されるLogの世代 – 「spark.sql.streaming.minBatchesToRetain」で指定(Def:100) exampleDataFrame.withWatermark('eventTime', "10 minute") # eventTimeカラムを用いてWatermark設定、許容遅延を10分に設定
24.
実行の流れ(詳細:バッチ実行) • StreamExecution#runBatchで以下が実行 – 前回Offset~最新OffsetまでのデータをSourceから取得 •
ただし、新規データが存在する場合のみ – 新規データ未存在Sourceを省くようLogical Planを更新 – 「QueryPlanning」フェーズとしてPlanを作成&更新 • StatefulOperatorのPlan生成はこのフェーズで実施 – Sourceを基に結果を取得 • DataSetとして取得しているため、実体はExecutor上のみ – Sinkに出力結果を出力
25.
実行の流れ(詳細:後処理) • StreamExecution#runBatchesで以下が実行 – BatchCommitLogに完了したBatchIdを追加 –
BatchIdをインクリメント
26.
確認中のポイント • StatefulOperatorの状態の読込書込タイミング – Physical
Plan上での具体的な実行プランが不明 • Source/SinkへのアクセスのPhysical Plan上への 落とし込んだ際の動作
27.
Kakfa用コンポーネントの構成
28.
Kafka用コンポーネント一覧 • 代表的なコンポーネント一覧 – KafkaSource –
KafkaSink – KafkaSourceProvider • Spark Structured Streamingのformat指定時に紐付けるクラス – KafkaSourceOffset – KafkaOffsetReader • Logical Plan作成時にOffset取得に使用されるクラス
29.
KafkaSource/Sinkのロードフロー • KafkaSourceProviderが「DataSourceRegister」の Serviceに登録されており、ServiceLoaderでロード – デフォルトではcsv/jdbc/json/parquet/console等が存在
30.
Kafka用コンポーネント固有箇所 • KafkaSource – Offsetを基にデータを取得するRDDを作成 •
DataFrame上のスキーマは以下 – key/value/topic/partition/offset/timestamp/timestampType • KafkaSink – DataFrameを用いてデータを書き込み • ※KafkaClientは「kafka-client-0.10系」を使用
31.
Kafka用コンポーネント固有箇所 • KafkaSourceOffset – Topic-PartitionとOffsetのペアのリスト –
CheckpointのOffsetLogとして読込書込が行われる。 • 内容例 v1 {"batchWatermarkMs":0,"batchTimestampMs":1506805200115,"conf":{"spark.sql.shuf fle.partitions":"200"}} {"common_event":{"2":318574460,"5":318572400,"4":318579256,"1":318600441,"3":318 558444,"6":318540065,"0":318576508}}
32.
Kafka用コンポーネント固有箇所 • KafkaOffsetReader – KafkaのOffsetを取得 –
実行状態によって以下のパターンの取得を実施 • Latest – 次バッチ生成時の最新Offset取得 – 初回起動時に初期Offset設定が「latest」の場合 • Earliest – 初回起動時に初期Offset設定が「earliest」の場合
33.
まとめ • Spark Strucured
Streamingは Source/Sink/Offsetという形で 各コンポーネントを抽象化して使用 – コンポーネント毎の固有個所は意外に少ない • 上記はSourceRegisterに登録して適用 • Offsetは自前で管理しており、 KafkaのOffset管理の機構は未使用
Download








![Spark Structured Streamingとは?
• 注意点
– Spark Streamingと同様マイクロバッチ方式であり、
レコード単位で処理するストリーム処理ではない。
– Sparkの新実行エンジンDrizzleとは独立した別の機能
• https://github.com/amplab/drizzle-spark
– Spark2.3.0で継続的に実行する方式についての提案も
挙がっているが、現状の進み具合から
おそらくSpark2.3.0では無理?
• [SPARK-20928]
Continuous Processing Mode for Structured Streaming](https://image.slidesharecdn.com/20171129sparkstructuredstreamingwithkafka-171130000435/85/Spark-Structured-Streaming-with-Kafka-7-320.jpg)

![簡単なアプリケーション例
// 入力データを単語毎に分割
val words = lines.as[String].flatMap(_.split(" "))
// 入力単語毎にカウント
val wordCounts = words.groupBy("value").count()
// 集計結果を毎回すべてコンソールに出力するStreamingQueryを生成
val streamingQuery = wordCounts.writeStream
.outputMode("complete") // 出力モードを指定
.format("console")
.start()
// アプリケーションが外部から停止されるまで実行
streamingQuery.awaitTermination()](https://image.slidesharecdn.com/20171129sparkstructuredstreamingwithkafka-171130000435/85/Spark-Structured-Streaming-with-Kafka-9-320.jpg)






















































![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)






















