2. 何故Gearpumpが必要なのか?
• リアルタイムストリーム処理に求めたい性質
①Keep the data moving
② Query using StreamSQL
③ Handle stream imperfections
④ Generate predictable outcomes
⑤ Integrate stored and streaming data
⑥ Guarantee data safety and availabilit
⑦ Partition and scale applications automatically
⑧ Process and Respond Instantaneously
• 『Meet The 8 Requirements of Real-Time Stream Processing (2006)』
• 上記の性質を満たすストリーム処理基盤が必要
• Apache Flinkも同様の性質をもつ
だが、小規模のCheckpointに区切る方式
4
4. Gearpumpの構成
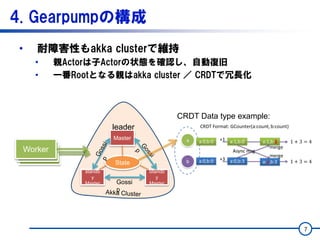
• 耐障害性もakkaclusterで維持
• 親Actorは子Actorの状態を確認し、自動復旧
• 一番Rootとなる親はakka cluster / CRDTで冗長化
7
WorkerWorkerWorker
Master
standb
y
Master
Standb
y
Master
State
Gossi
p
CRDT Data type example:
leader






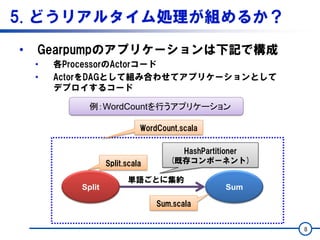
![5. どうリアルタイム処理が組めるか?
• Split.scala
9
class Split(taskContext : TaskContext, conf: UserConfig) extends Task(taskContext, conf) {
import taskContext.{output, self}
// 1. 自分自身にStartメッセージを通知。
override def onStart(startTime : StartTime) : Unit = {
self ! Message("start")
}
// 2. 文章を単語に分割し、空文字を除去した上で下流に送信
override def onNext(msg : Message) : Unit = {
Split.TEXT_TO_SPLIT.lines.foreach { line =>
line.split("[¥¥s]+").filter(_.nonEmpty).foreach { msg =>
output(new Message(msg, System.currentTimeMillis()))
}
}
// 3. 次メッセージを自分に対して送信するタスクを仕掛ける
import scala.concurrent.duration._
taskContext.scheduleOnce(Duration(100, TimeUnit.MILLISECONDS))(self ! Message("continue",
System.currentTimeMillis()))
}
}](https://image.slidesharecdn.com/20160130introductionofgearpump-160130213835/85/Gearpump-10-320.jpg)
![5. どうリアルタイム処理が組めるか?
• Sum.scala
10
class Sum (taskContext : TaskContext, conf: UserConfig) extends Task(taskContext, conf) {
private[wordcount] val map : mutable.HashMap[String, Long] = new mutable.HashMap[String, Long]()
private[wordcount] var wordCount : Long = 0
private var snapShotTime : Long = System.currentTimeMillis()
private var snapShotWordCount : Long = 0
private var scheduler : Cancellable = null
override def onStart(startTime : StartTime) : Unit = {
// 1. 起動時に状態出力タスクを仕掛ける。
scheduler = taskContext.schedule(new FiniteDuration(5, TimeUnit.SECONDS),
new FiniteDuration(30, TimeUnit.SECONDS))(reportWordCount)
}
override def onNext(msg : Message) : Unit = {
if (null == msg) {
return
}
// 2. 受信したメッセージから単語を取得し、総受信回数と単語ごとの受信回数をカウント
val current = map.getOrElse(msg.msg.asInstanceOf[String], 0L)
wordCount += 1
map.put(msg.msg.asInstanceOf[String], current + 1)
}](https://image.slidesharecdn.com/20160130introductionofgearpump-160130213835/85/Gearpump-11-320.jpg)
![5. どうリアルタイム処理が組めるか?
• WordCount.scala
11
object WordCount extends AkkaApp with ArgumentsParser {
private val LOG: Logger = LogUtil.getLogger(getClass)
val RUN_FOR_EVER = -1
// 1. 起動時のCLIから読み込む項目と形式、注釈、必須/オプショナル、デフォルト値を定義
override val options: Array[(String, CLIOption[Any])] = Array(
"split" -> CLIOption[Int]("<how many split tasks>", required = false, defaultValue = Some(1)),
"sum" -> CLIOption[Int]("<how many sum tasks>", required = false, defaultValue = Some(1))
)
def application(config: ParseResult) : StreamApplication = {
// 2. CLIから読み込んだ設定項目を用いてProcessorを生成
val splitNum = config.getInt("split")
val sumNum = config.getInt("sum")
val split = Processor[Split](splitNum)
val sum = Processor[Sum](sumNum)
// 3. メッセージのProcessor間の割り振りを行うPartitionerを生成
val partitioner = new HashPartitioner
// 4. ProcessorとPartitionerを用いてDAGを作成
val app = StreamApplication("wordCount", Graph(split ~ partitioner ~> sum), UserConfig.empty)
app
}
非常に直観的にグラフが
組める!](https://image.slidesharecdn.com/20160130introductionofgearpump-160130213835/85/Gearpump-12-320.jpg)























![[Postgre sql9.4新機能]レプリケーション・スロットの活用](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql9-140909012453-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[INSIGHT OUT 2011] B27 SQL Anywhereの先進のセルフヒーリング技術について(glenn paulley)](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011b27sqlanywhereglennpaulley-111114012436-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










