MLlib-specific Contribution Guidelines
•Be widely known
• Be used and accepted
• academic citations and concrete use cases can help justify this
• Be highly scalable
• Be well documented
• Have APIs consistent with other algorithms in MLlib that accomplish the
same thing
• Come with a reasonable expectation of developer support.
8
[https://cwiki.apache.org/confluence/display/SPARK/Contributing+to+Spark]
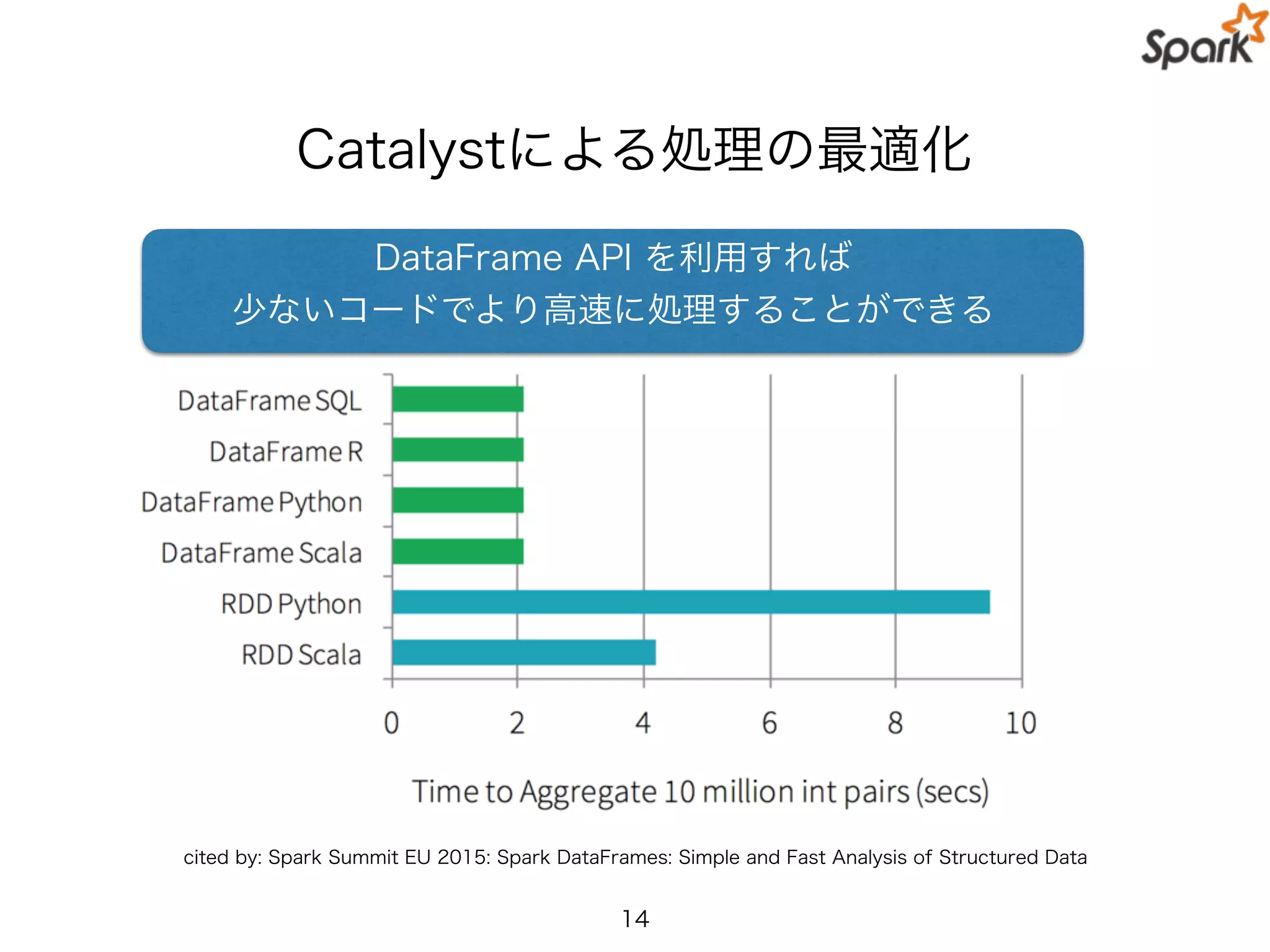
Catalystによる処理の最適化
14
cited by: SparkSummit EU 2015: Spark DataFrames: Simple and Fast Analysis of Structured Data
DataFrame API を利用すれば
少ないコードでより高速に処理することができる
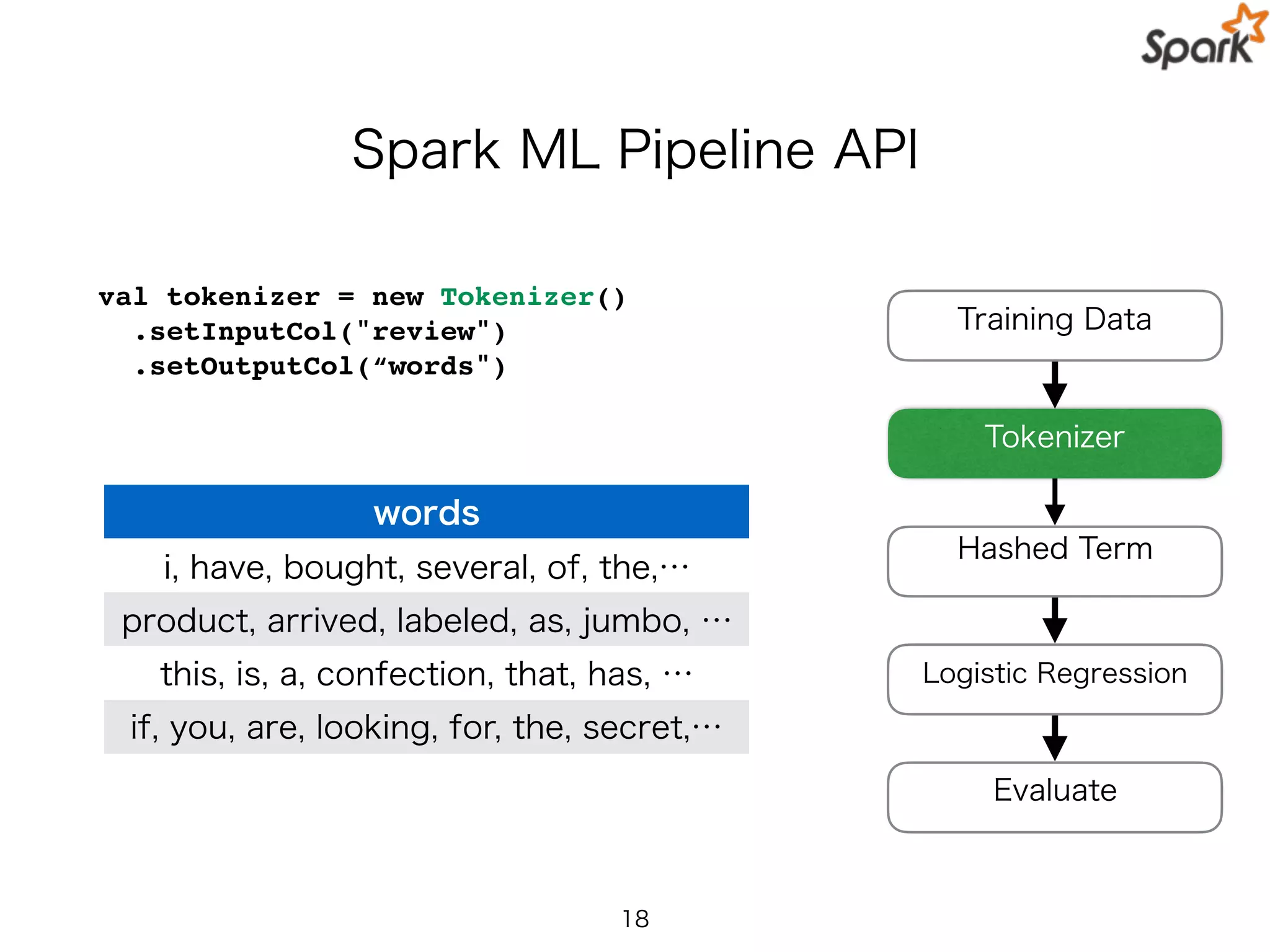
Spark ML PipelineAPI
val tokenizer = new Tokenizer()
.setInputCol("review")
.setOutputCol(“words")
18
Training Data
Hashed Term
Logistic Regression
Evaluate
Tokenizer
words
i, have, bought, several, of, the,…
product, arrived, labeled, as, jumbo, …
this, is, a, confection, that, has, …
if, you, are, looking, for, the, secret,…
19.
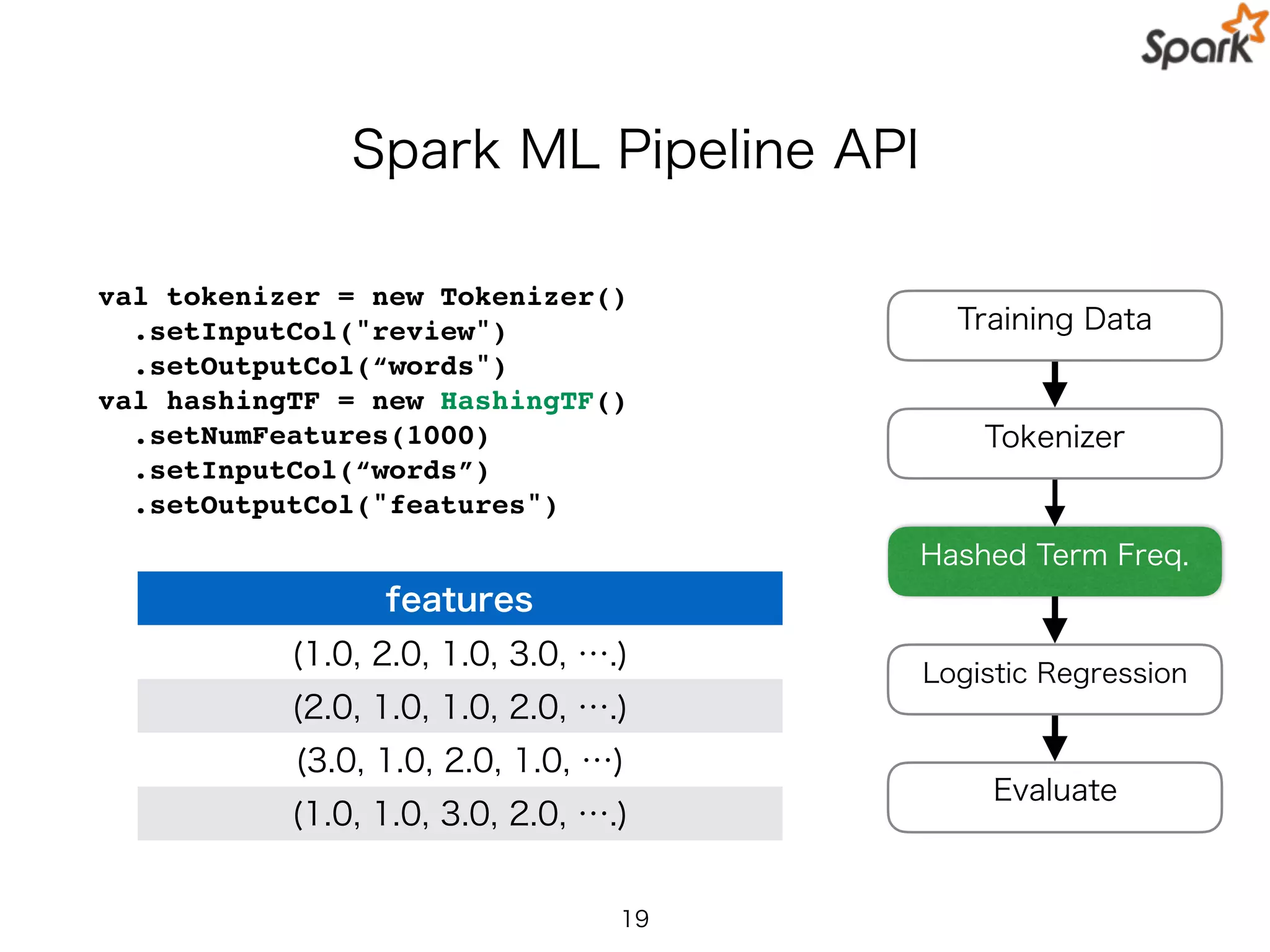
Spark ML PipelineAPI
val tokenizer = new Tokenizer()
.setInputCol("review")
.setOutputCol(“words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(“words”)
.setOutputCol("features")
19
Training Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
features
(1.0, 2.0, 1.0, 3.0, ….)
(2.0, 1.0, 1.0, 2.0, ….)
(3.0, 1.0, 2.0, 1.0, …)
(1.0, 1.0, 3.0, 2.0, ….)
20.
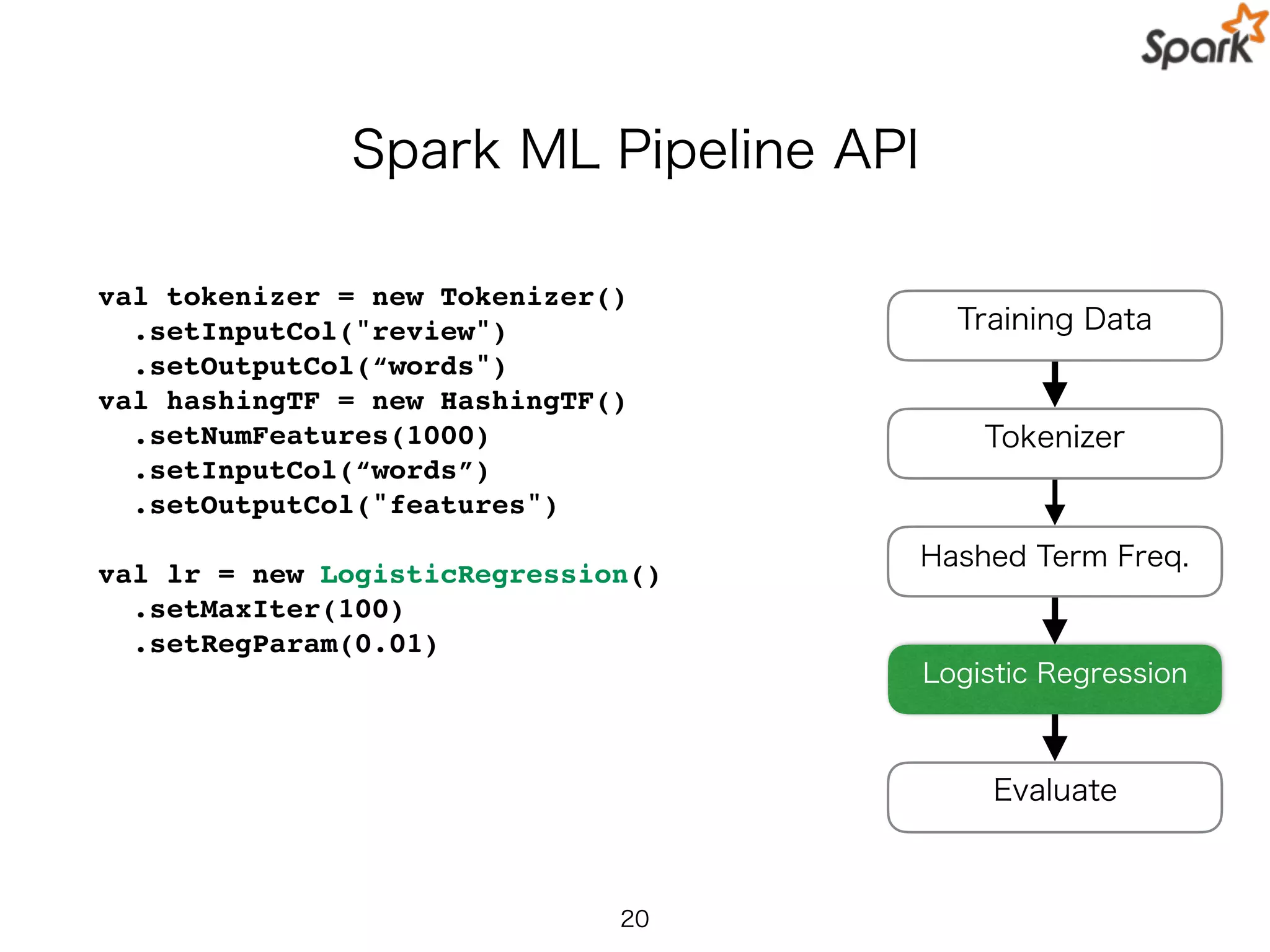
Spark ML PipelineAPI
val tokenizer = new Tokenizer()
.setInputCol("review")
.setOutputCol(“words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(“words”)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(100)
.setRegParam(0.01)
20
Training Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
21.
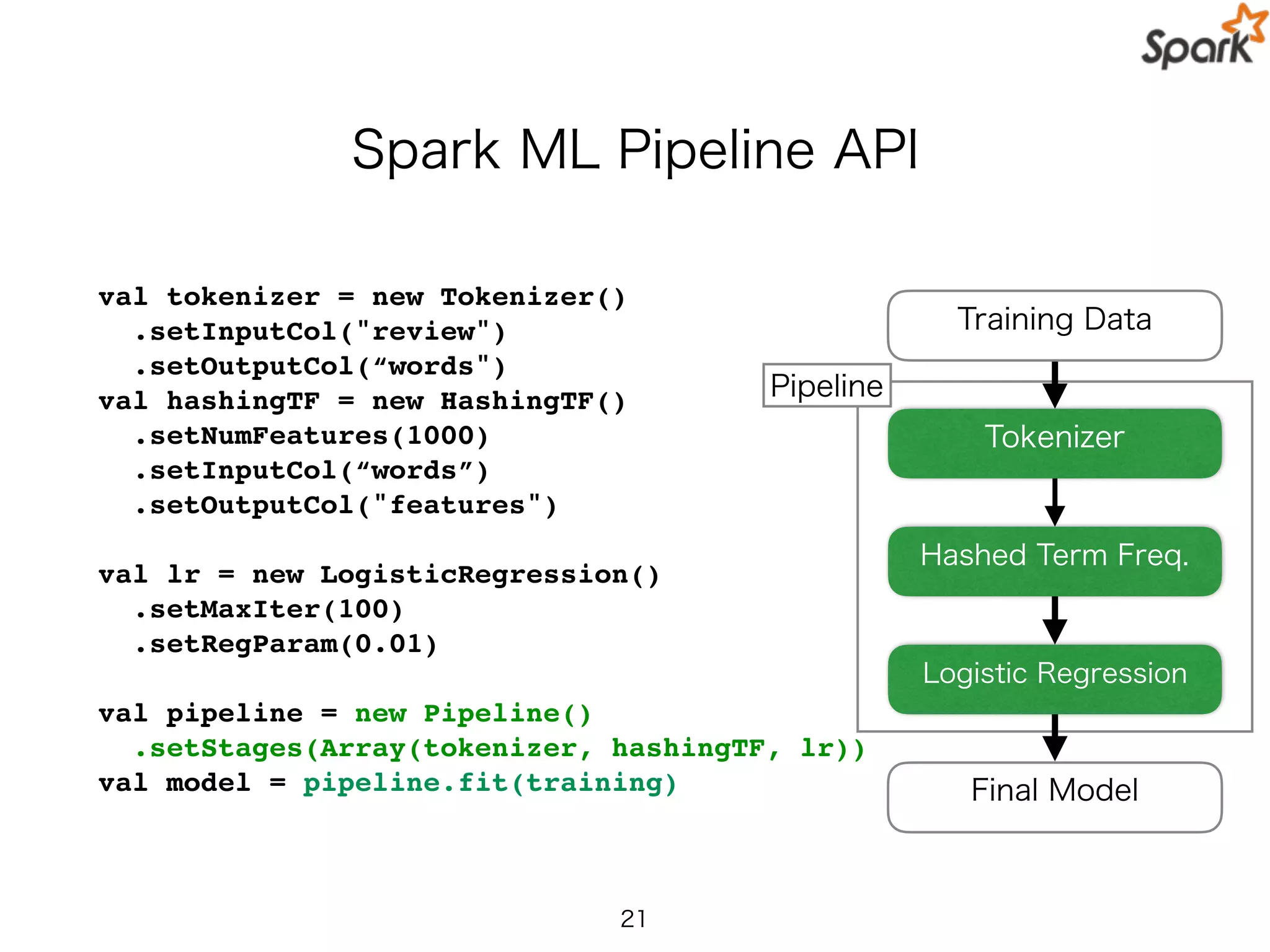
Spark ML PipelineAPI
val tokenizer = new Tokenizer()
.setInputCol("review")
.setOutputCol(“words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(“words”)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(100)
.setRegParam(0.01)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
val model = pipeline.fit(training)
21
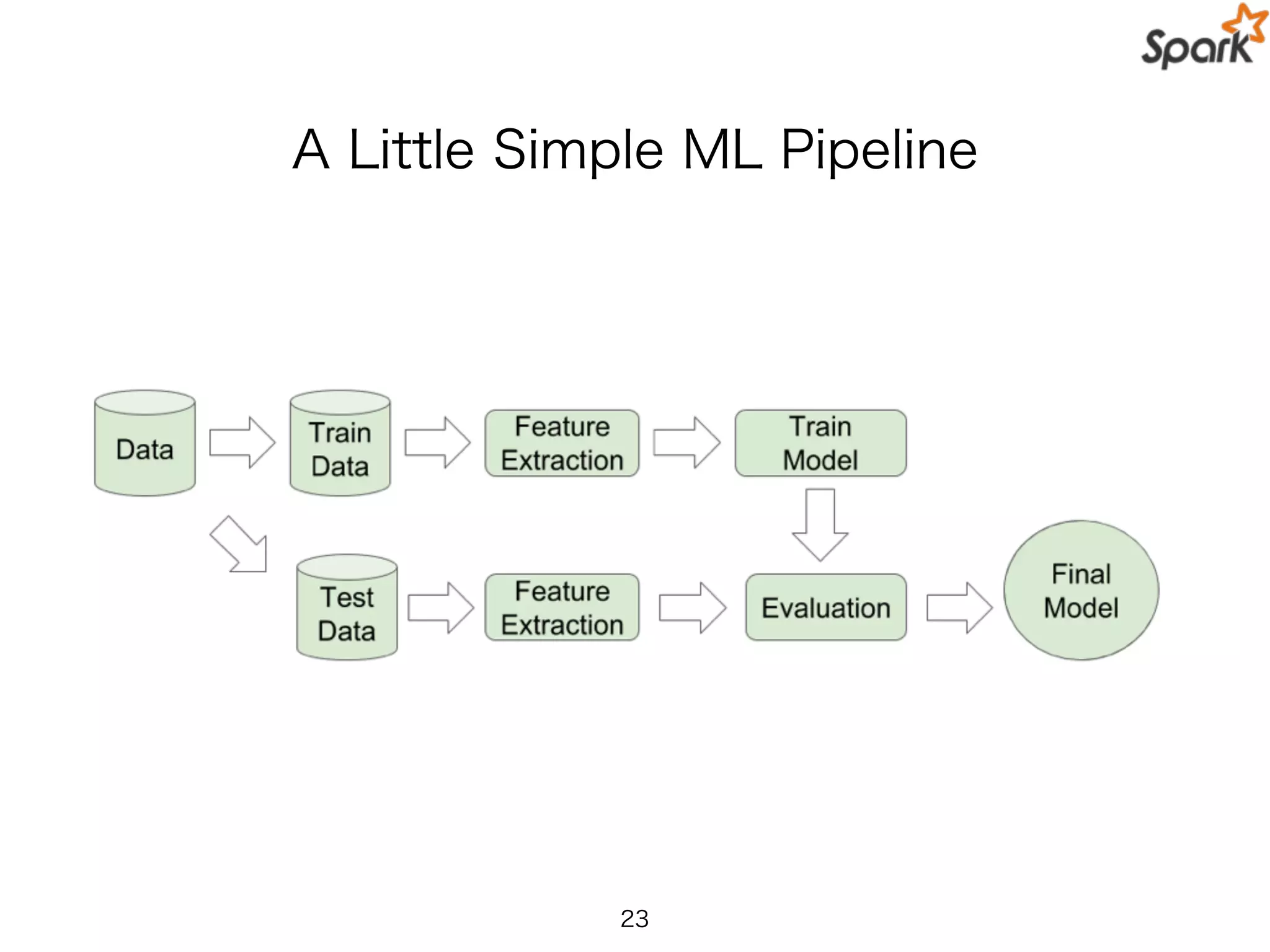
Pipeline
Training Data
Hashed Term Freq.
Logistic Regression
Final Model
Tokenizer
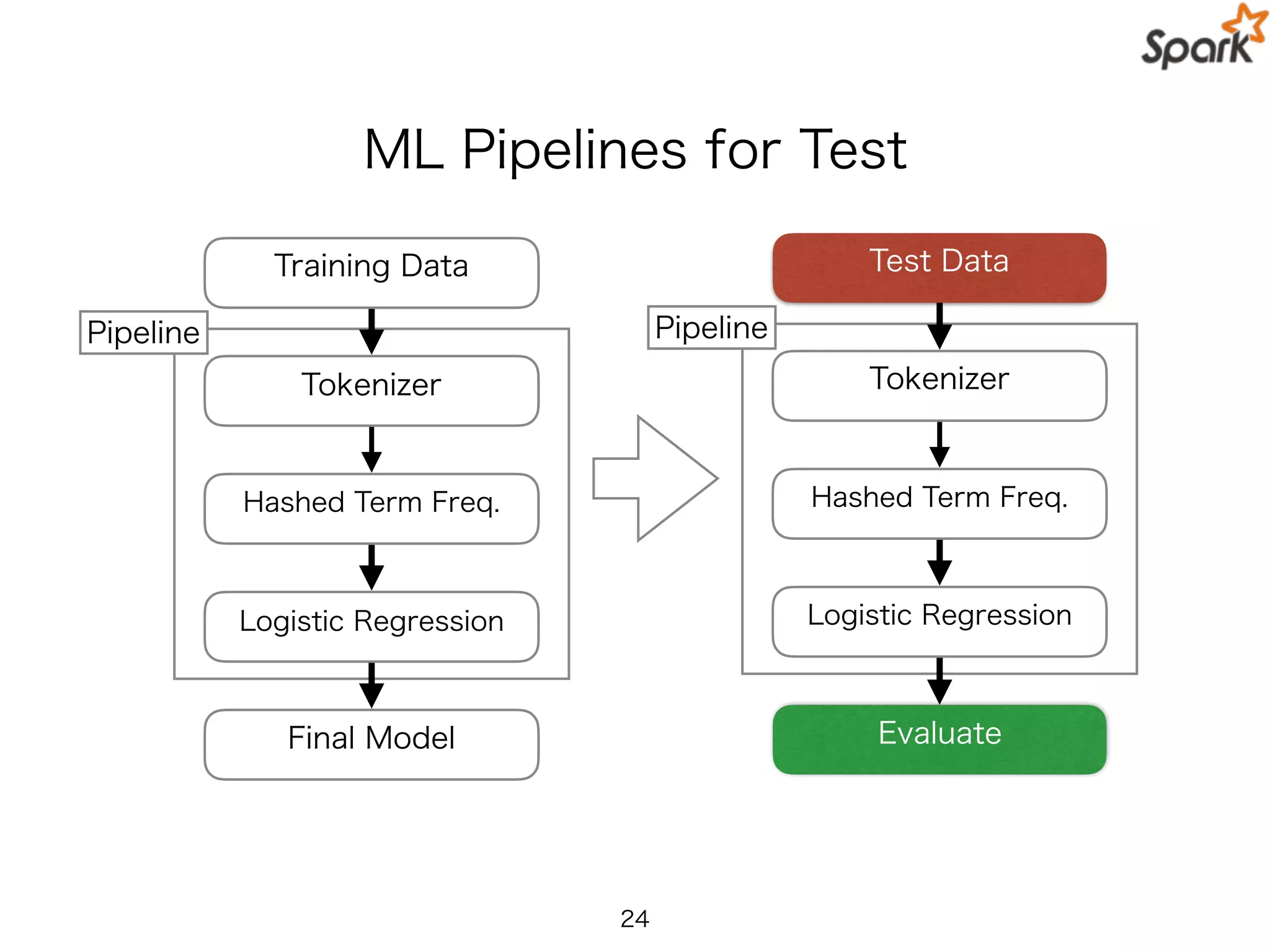
ML Pipelines forTest
24
Pipeline
Training Data
Hashed Term Freq.
Logistic Regression
Final Model
Tokenizer
Pipeline
Test Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
25.
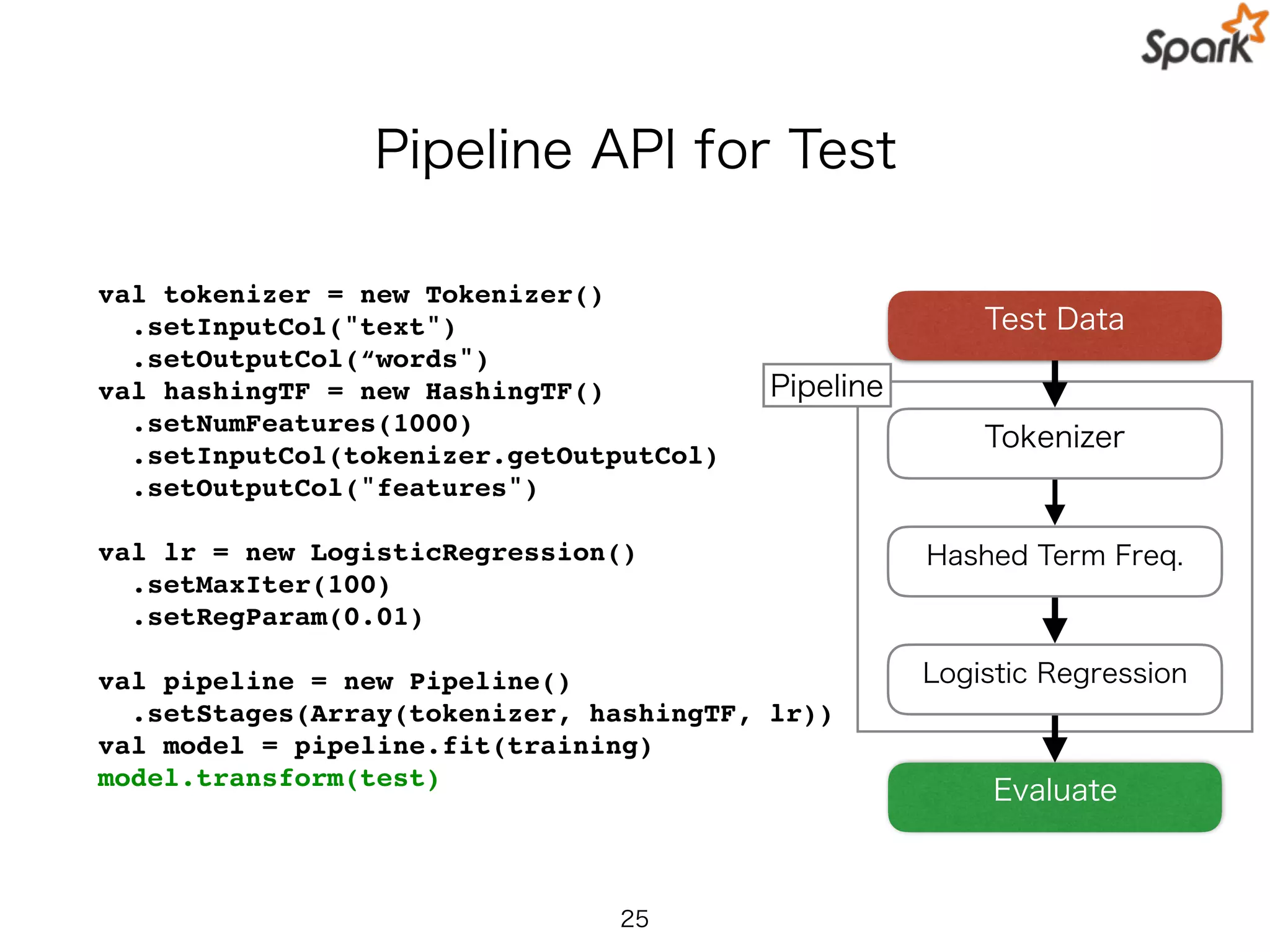
Pipeline API forTest
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol(“words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(100)
.setRegParam(0.01)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
val model = pipeline.fit(training)
model.transform(test)
25
Pipeline
Test Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
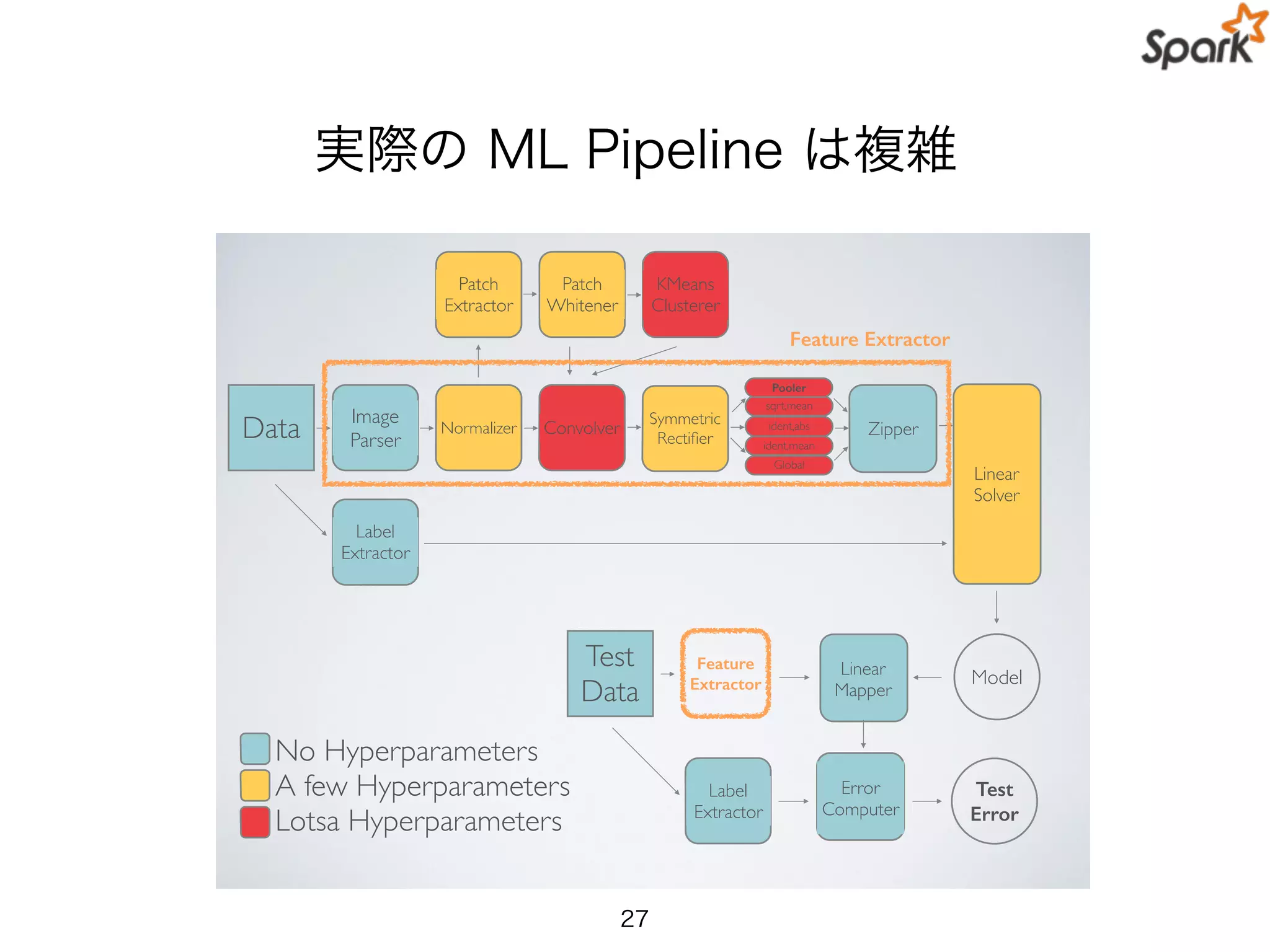
実際の ML Pipelineは複雑
27
Data Image!
Parser
Normalizer Convolver
sqrt,mean
Zipper
Linear
Solver
Symmetric!
Rectifier
ident,abs
ident,mean
Global
Pooler
Patch!
Extractor
Patch
Whitener
KMeans!
Clusterer
Feature Extractor
Label!
Extractor
Linear!
Mapper
Model
Test!
Data
Label!
Extractor
Feature
Extractor
Test
Error
Error!
Computer
No Hyperparameters!
A few Hyperparameters!
Lotsa Hyperparameters
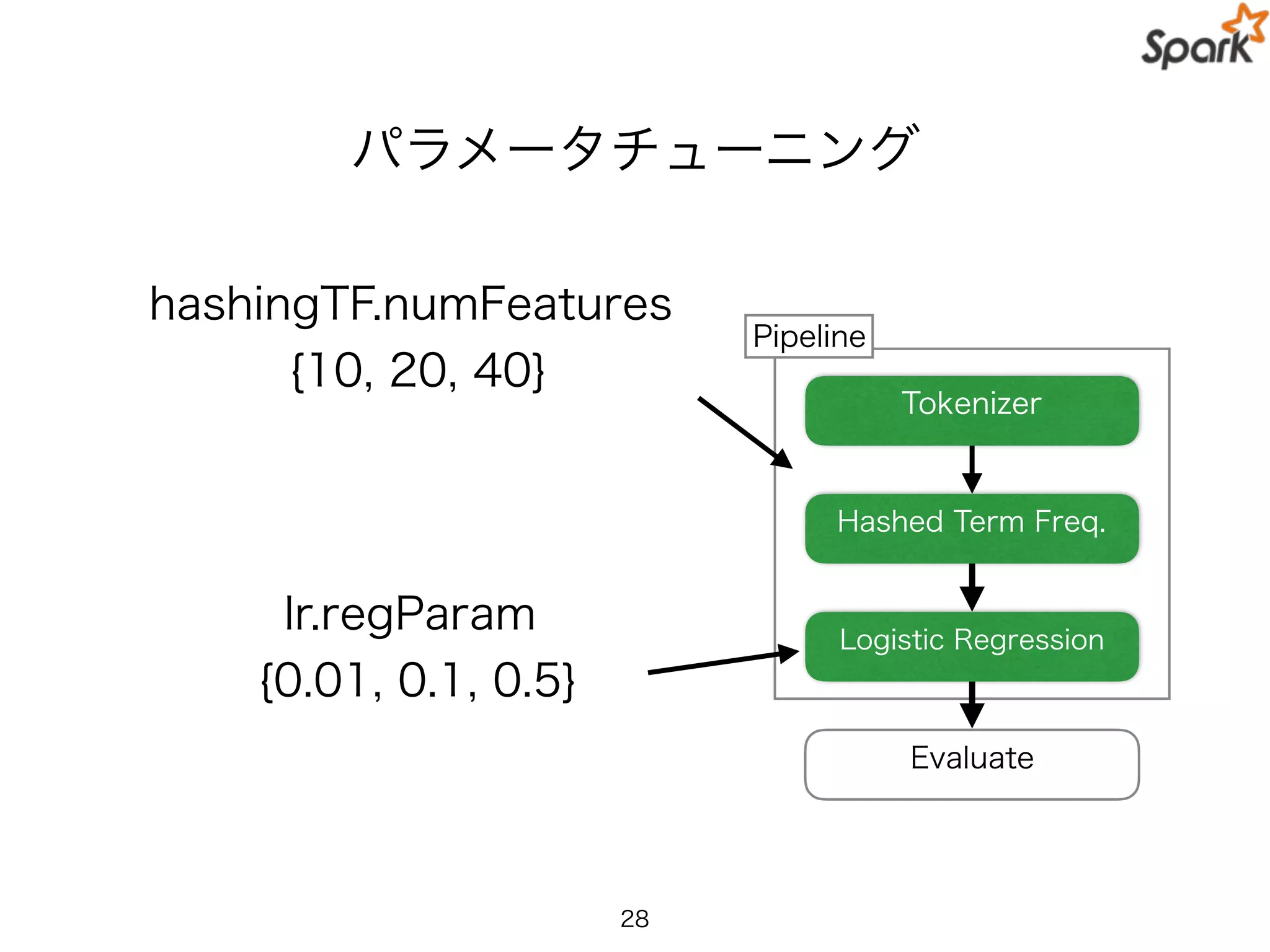
Practical Spark MLPipeline API
val paramGrid = new ParamGridBuilder()
.addGrid(hashingTF.numFeatures, Array(10, 20, 40))
.addGrid(lr.regParam, Array(0.01, 0.1, 0.5))
.build()
30
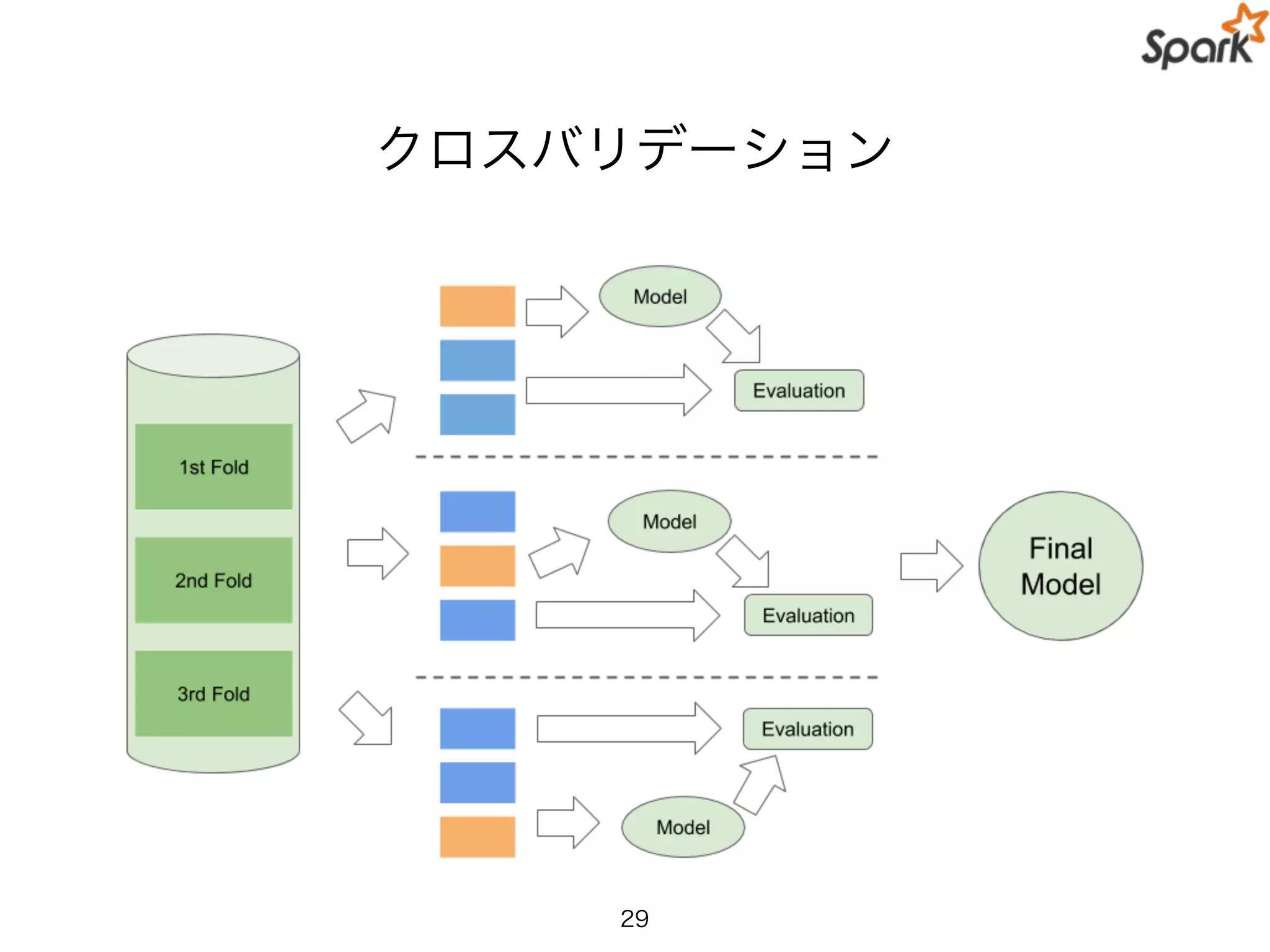
31.
Practical Spark MLPipeline API
val paramGrid = new ParamGridBuilder()
.addGrid(hashingTF.numFeatures, Array(10, 20, 40))
.addGrid(lr.regParam, Array(0.01, 0.1, 0.5))
.build()
val cv = new CrossValidator()
.setNumFolds(3)
.setEstimator(pipeline)
.setEstimatorParamMaps(paramGrid)
.setEvaluator(new BinaryClassificationEvaluator)
val cvModel = cv.fit(trainingDataset)
cvModel.transform(testDataset)
31
Parameter Tuning も Cross-Validation も
API が用意されているので複雑な PIpeline も簡単に定義
32.
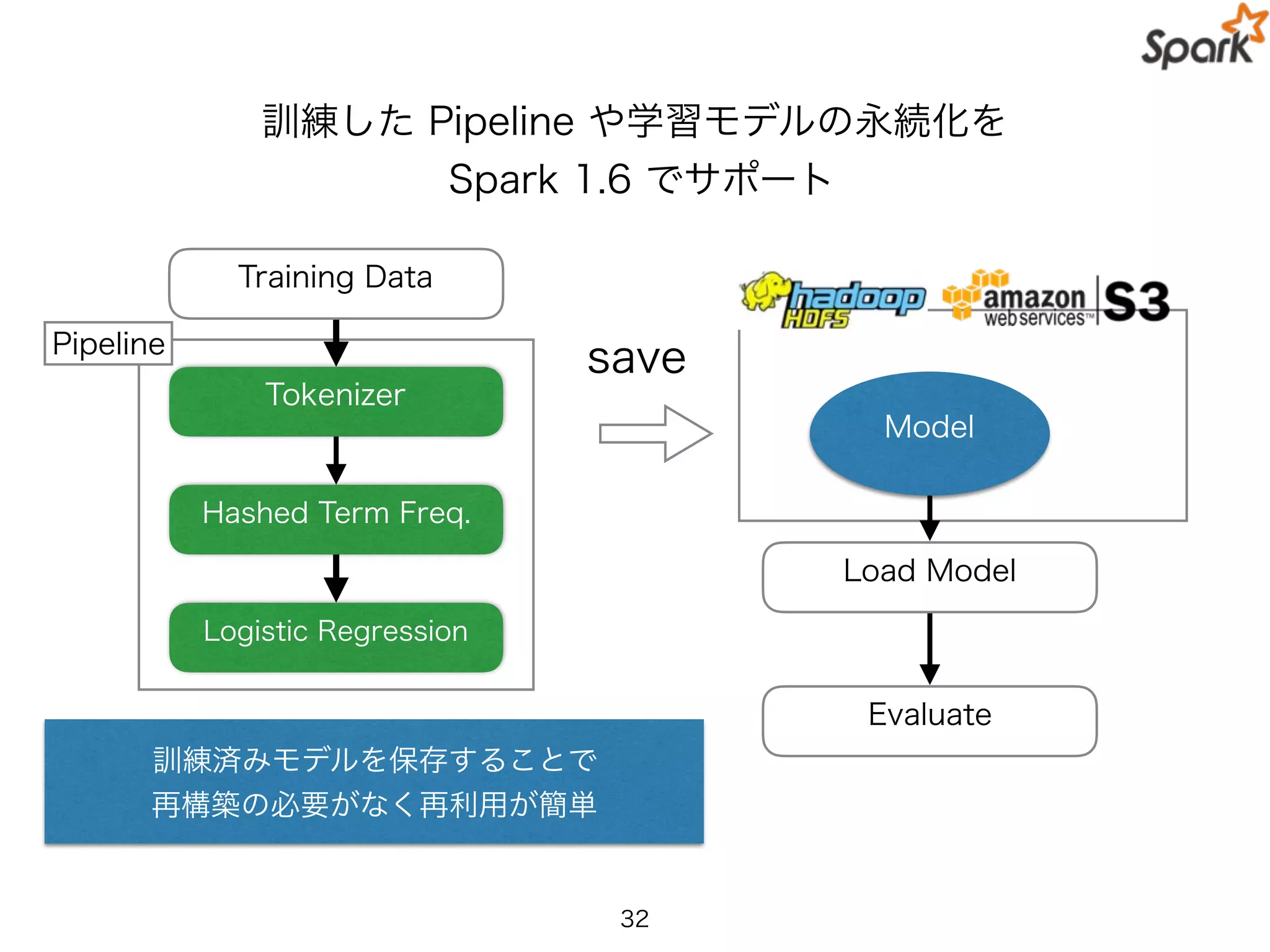
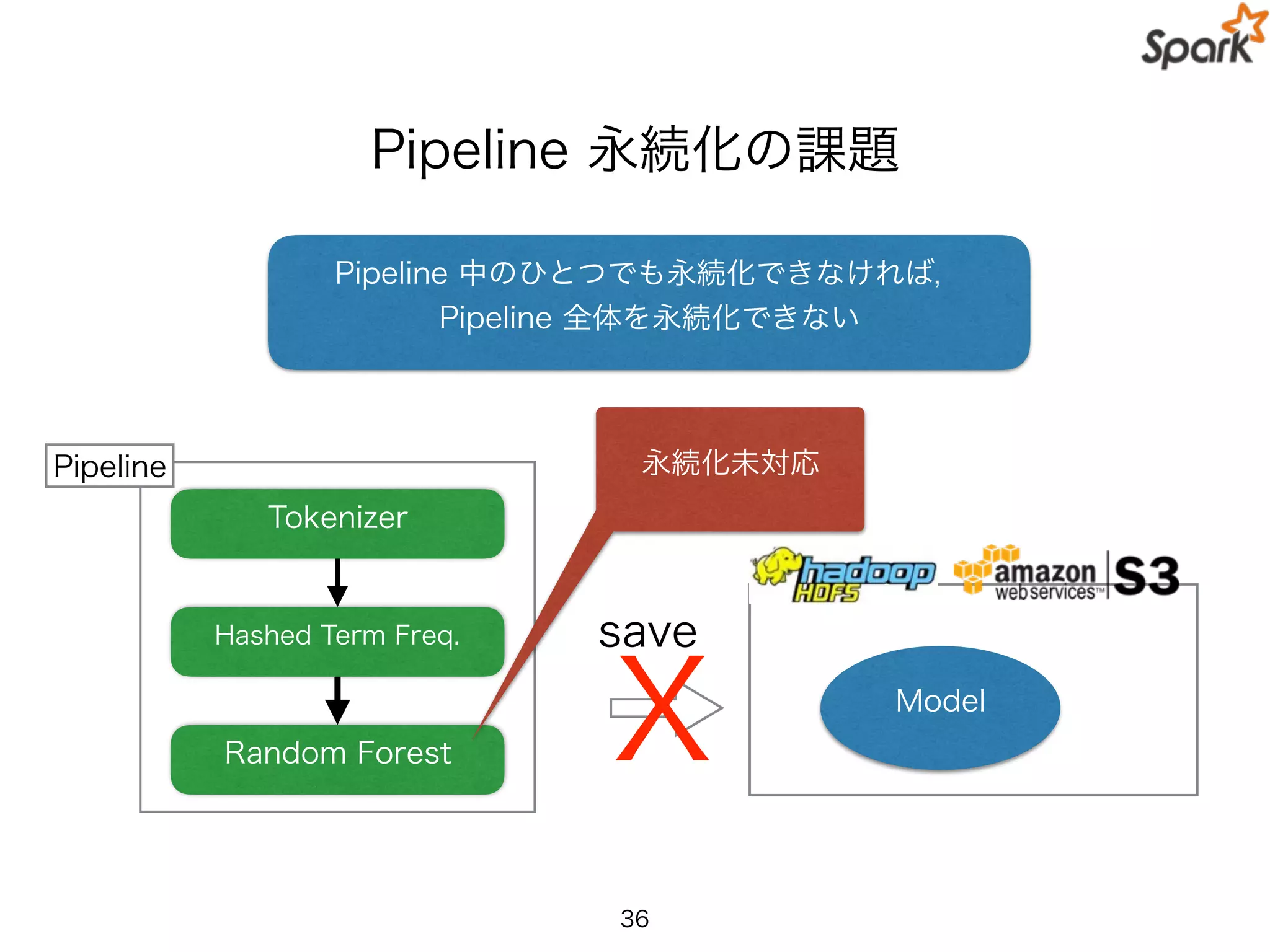
訓練した Pipeline や学習モデルの永続化を
Spark1.6 でサポート
32
Pipeline
Training Data
Hashed Term Freq.
Logistic Regression
Tokenizer
save
Model
Load Model
Evaluate
訓練済みモデルを保存することで
再構築の必要がなく再利用が簡単
33.
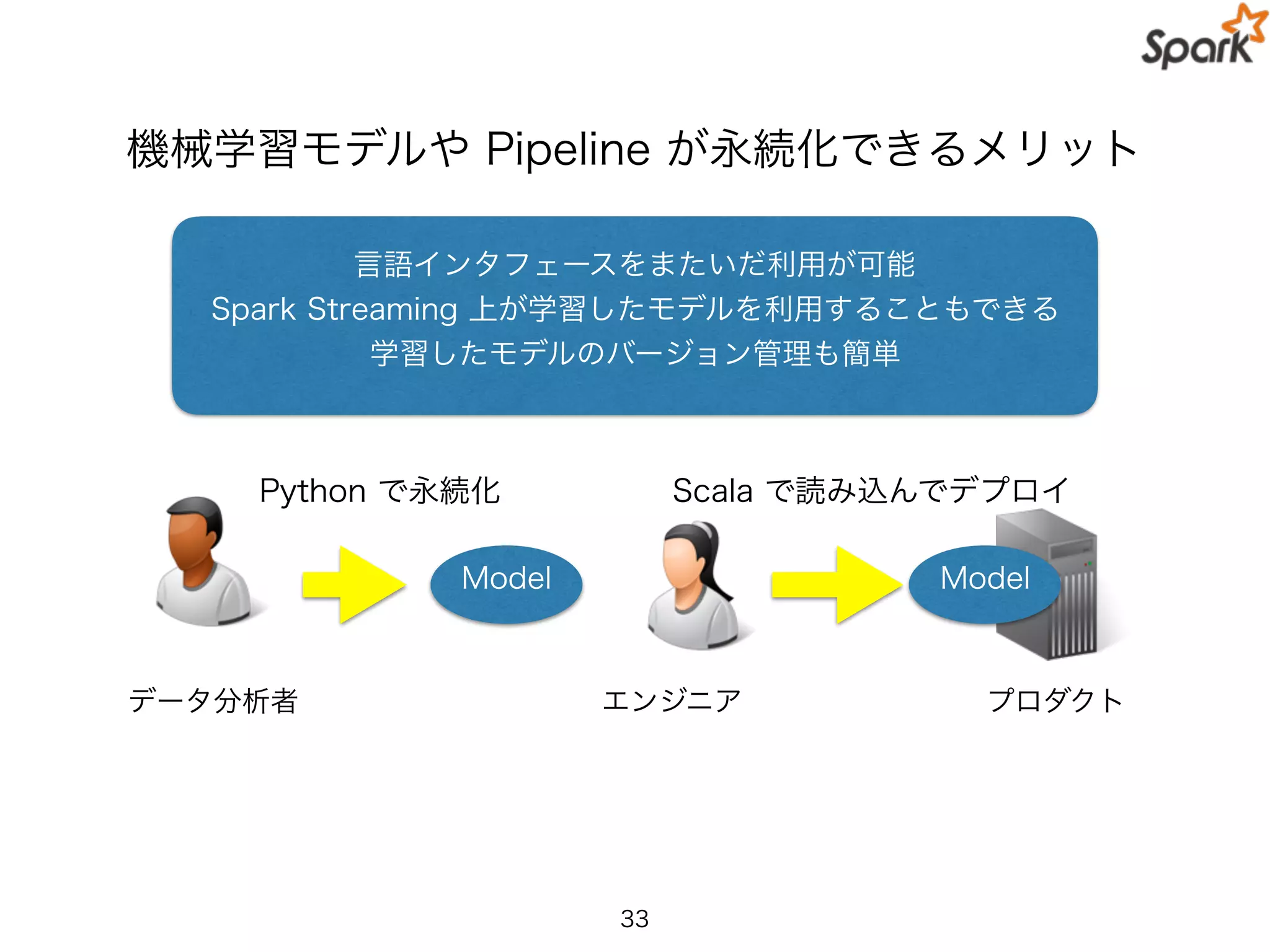
機械学習モデルや Pipeline が永続化できるメリット
33
データ分析者エンジニア
Model
プロダクト
Python で永続化 Scala で読み込んでデプロイ
言語インタフェースをまたいだ利用が可能
Spark Streaming 上が学習したモデルを利用することもできる
学習したモデルのバージョン管理も簡単
Model
Spark MLlib 2.0Roadmap
• Extended support for GLM model families and link functions
• Improve GLM scalability
• Tree partition by features
• Locality sensitive hashing (LSH)
• Deep learning: RBM/CNN
• Improved pipeline API
• Pipeline persistence
• Model serving
• Better SparkR coverage
• Project Tungsten integration
• Reorganize user guide
35






![MLlib-specific Contribution Guidelines
• Be widely known
• Be used and accepted
• academic citations and concrete use cases can help justify this
• Be highly scalable
• Be well documented
• Have APIs consistent with other algorithms in MLlib that accomplish the
same thing
• Come with a reasonable expectation of developer support.
8
[https://cwiki.apache.org/confluence/display/SPARK/Contributing+to+Spark]](https://image.slidesharecdn.com/2016-02-06spark-conference-japan-160209041021/75/2016-02-08-Spark-MLlib-Now-and-Beyond-Spark-Conference-Japan-2016-8-2048.jpg)




















































![[Oracle big data jam session #1] Apache Spark ことはじめ](https://cdn.slidesharecdn.com/ss_thumbnails/oraclebigdatajamsession1apachesparkquickstart-191127094941-thumbnail.jpg?width=640&height=640&fit=bounds)


























