実行サンプル(Scala)
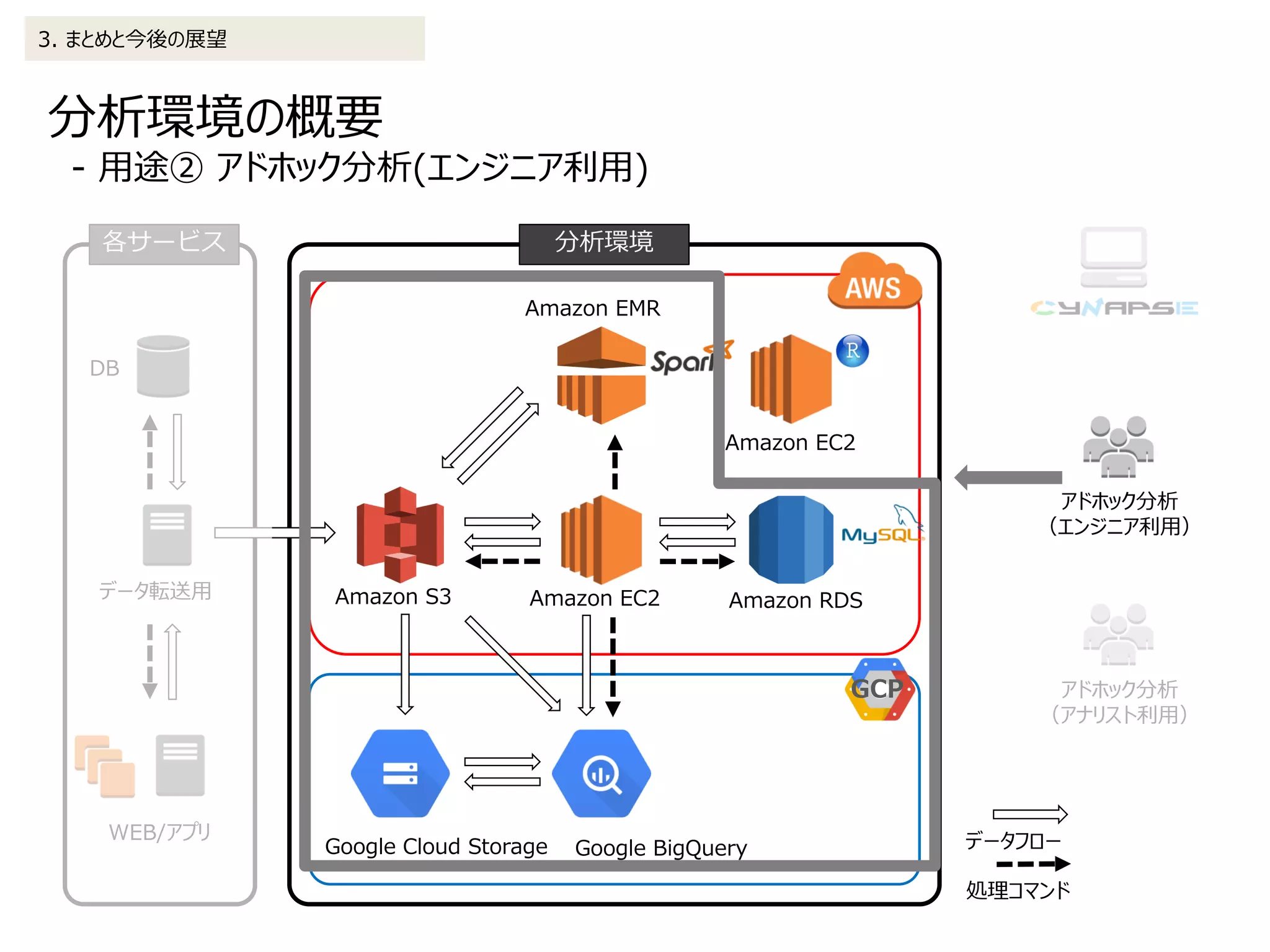
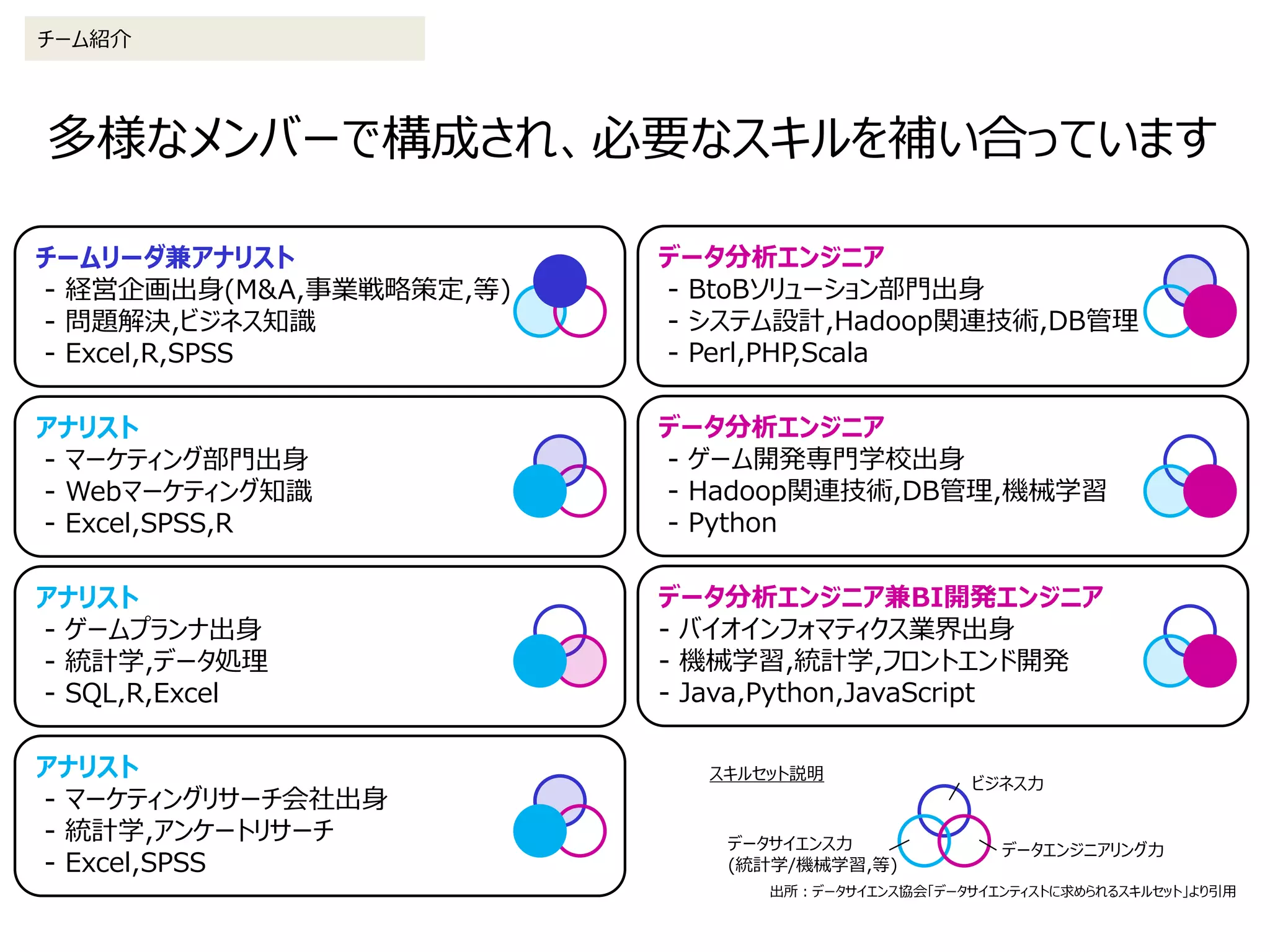
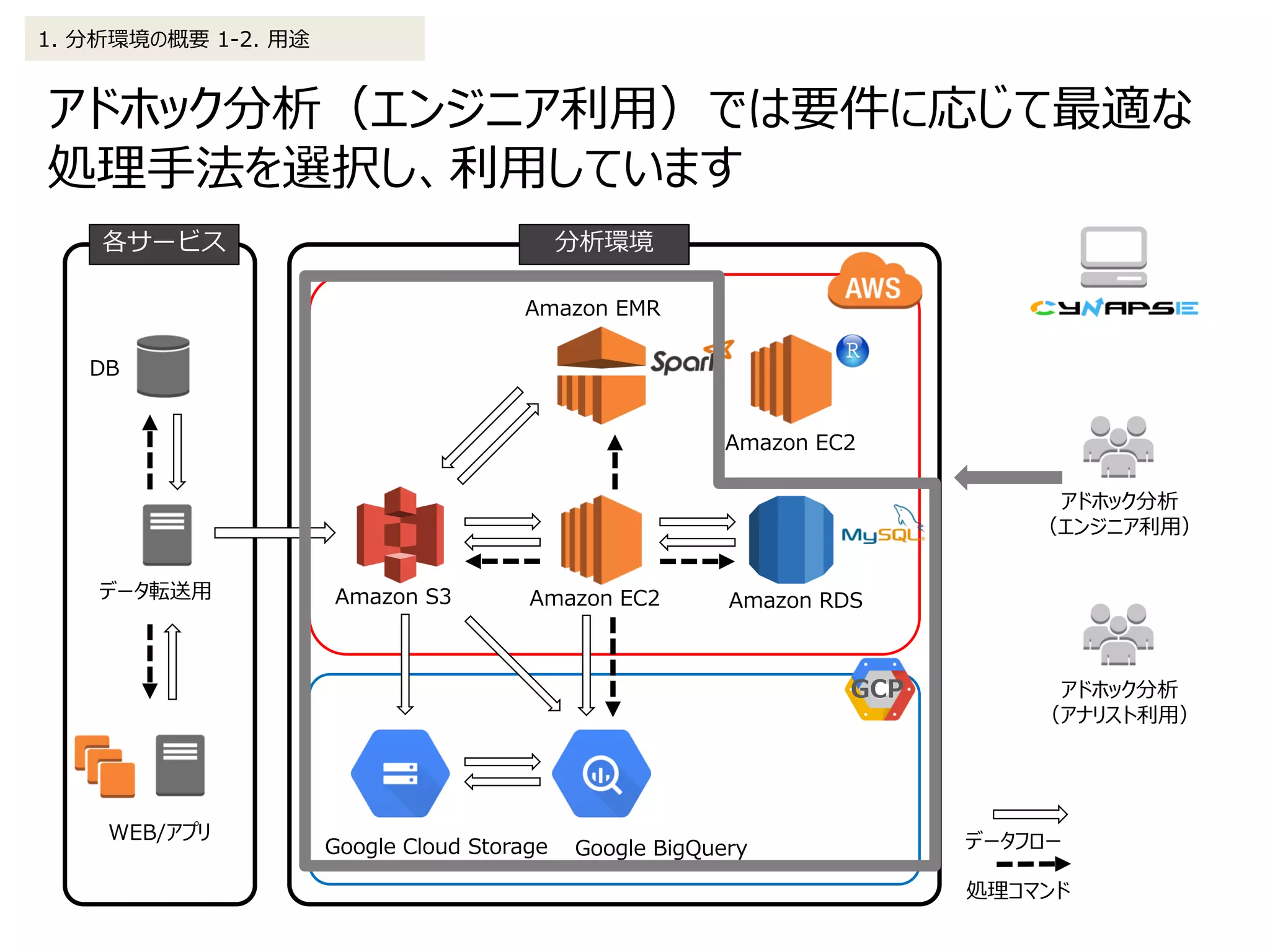
2. データ処理の詳細 2-2.アドホック分析(エンジニア利用)
> spark-shell
// ケースクラス定義
case class Login(user_id: Int, regist_dt: String, level: Int)
case class Sales(user_id: Int, item_id: Int, price: Int, regist_dt: String)
// データ取り込み(RDD)
val loginRDD = sc.textFile("s3://xxxxxxxxx/xxx/xxx/login/201601/*")
val salesRDD = sc.textFile("s3://xxxxxxxxx/xxx/xxx/sales/*")
// データフレーム作成
val loginDF = loginRDD.map{ data =>
val tmpData = data.split("¥t")
val user_id = tmpData(0).toInt
val regist_dt = tmpData(1)
val level = tmpData(4).toInt
Login(user_id, regist_dt, level)
}.toDF
val salesDF = salesRDD.map{ data =>
val tmpData = data.split("¥t")
val user_id = tmpData(0).toInt
val item_id = tmpData(1).toInt
val price = tmpData(2).toInt
val regist_dt = tmpData(4)
Sales(user_id, item_id, price , regist_dt)
}.toDF
// テーブル登録
loginDF.registerTempTable("login_table")
salesDF.registerTempTable("sales_table")
// クエリ発行
val resultQuery = sqlContext.sql(s"""
SELECT login.user_id,SUM(sales.price)
FROM login_table login JOIN sales_table sales ON (login.user_id = sales.user_id)
WHERE login.regist_dt LIKE '2016-01-01%'
AND login.level = 100
AND sales.regist_dt LIKE '2015-12%'
GROUP BY login.user_id
""")
// 結果表示
resultQuery.show
読み込むデータのcaseクラスを定義
S3からデータを取り込みRDDを生成
RDDからDataFrameを生成
DataFrameを一時テーブルに登録
sqlメソッド(Spark SQL)でクエリを発行
結果を表示
2016/1/1にログインしたレベル100のユーザが2015/12に購入した金額の集計
実行サンプル(BigQuery)
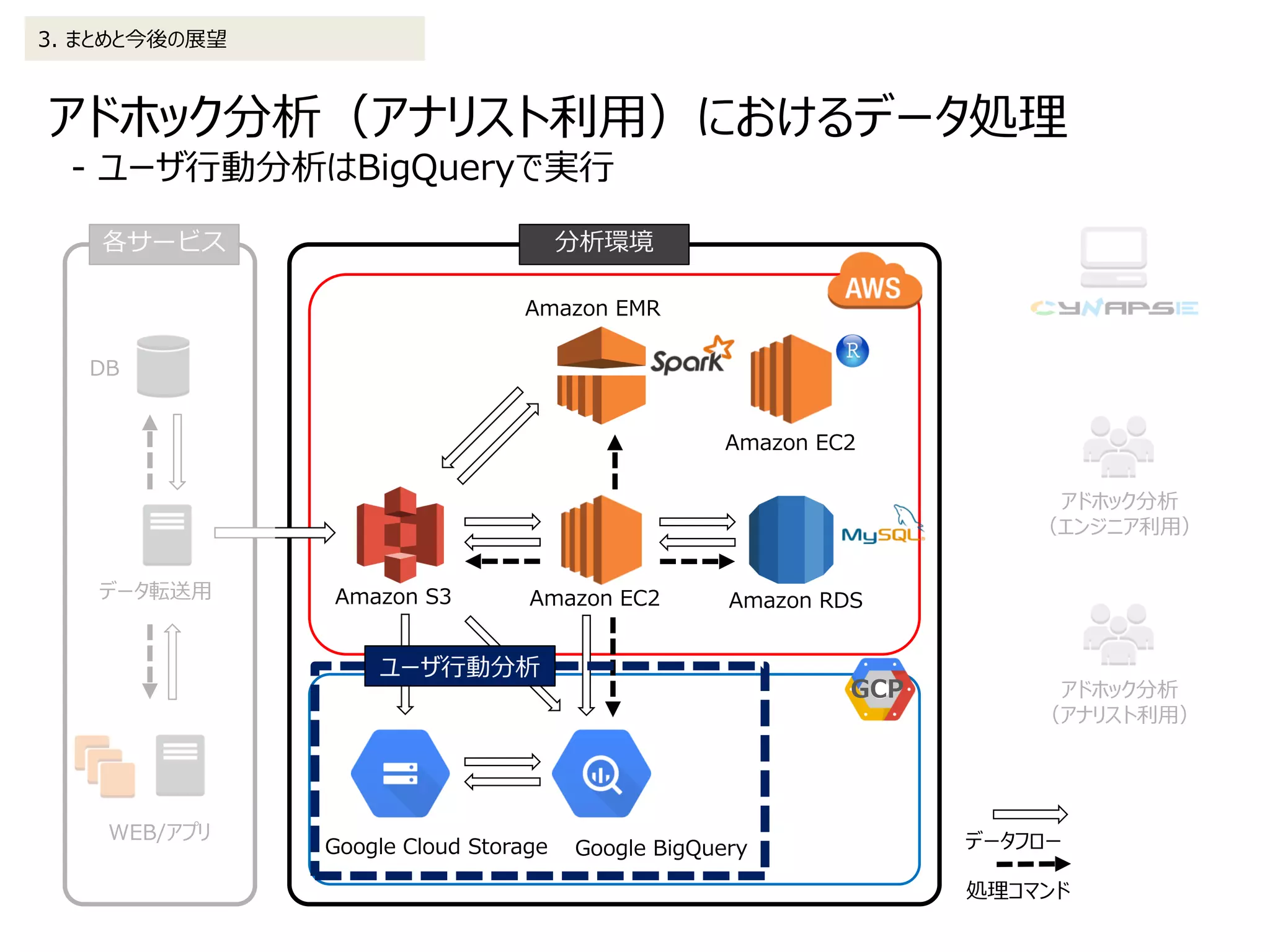
2. データ処理の詳細 2-3.アドホック分析(アナリスト利用)
SELECT
a.user_id,
SUM(b.price)
FROM
TABLE_QUERY(login,'REGEXP_MATCH(table_id, r"^aaa_20160101")') a
JOIN EACH
TABLE_QUERY(sales,'REGEXP_MATCH(table_id, r"^aaa_201512")') b
ON
a.user_id = b.user_id
GROUP EACH BY
a.user_id;
• 日付分割されたテーブルを正規表現で必要な単位に連結
⇒BiqQueryは従量課金のため無駄なデータ走査を発生させない
[ポイント]
2016/1/1にログインしたユーザが2015/12に購入した金額の集計

















![共通フォーマットを使用する利点は下記2つです
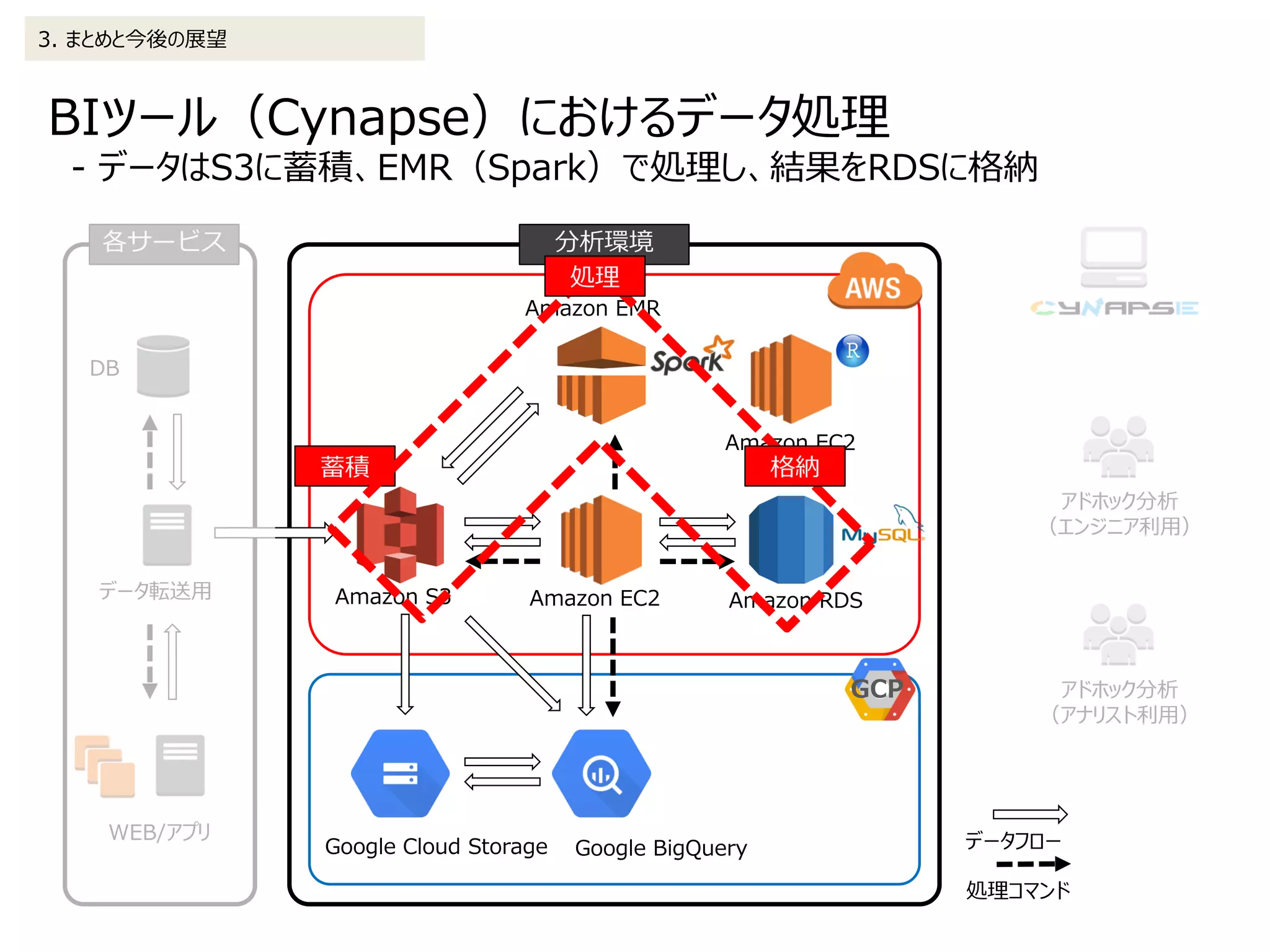
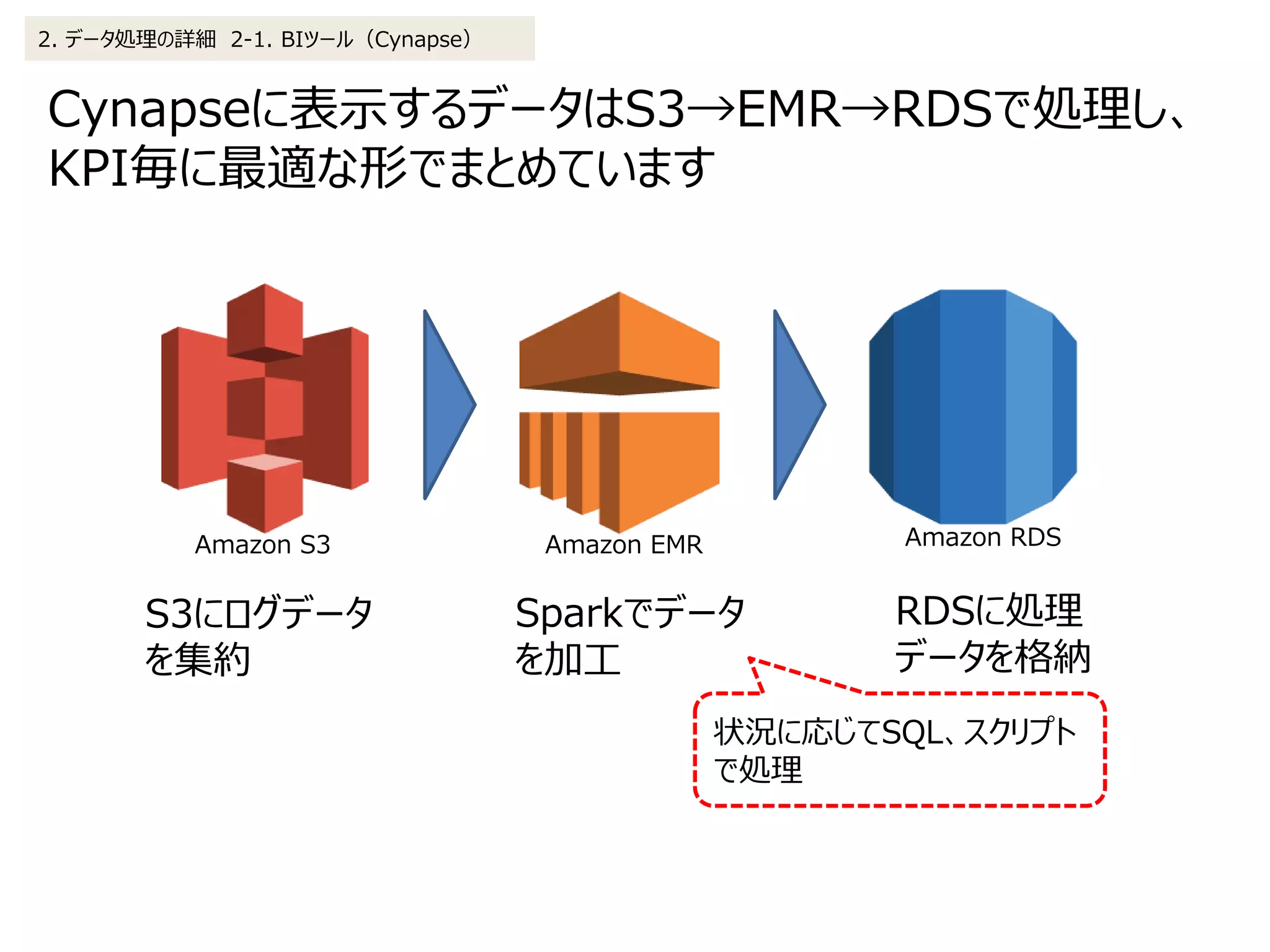
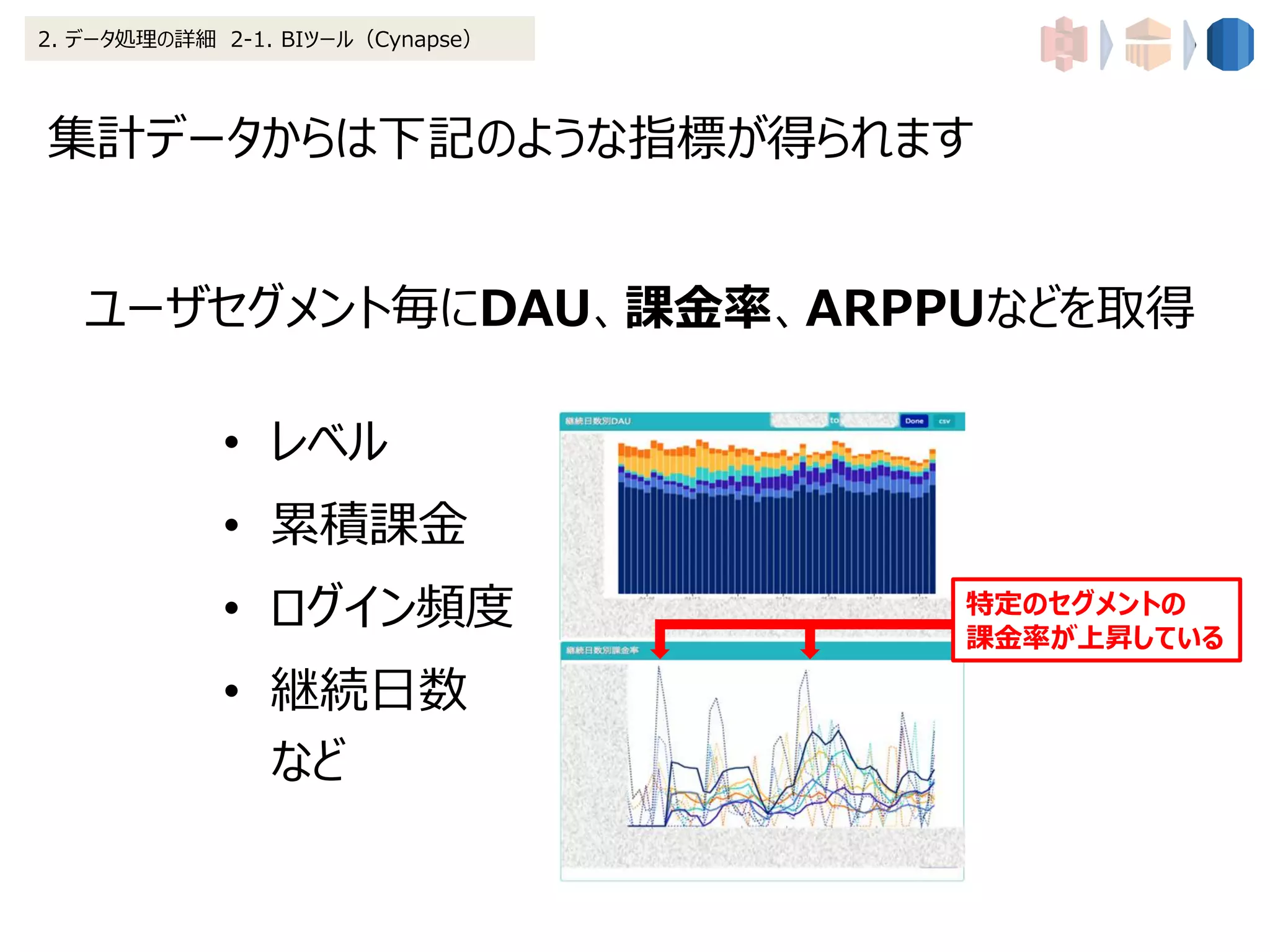
2. データ処理の詳細 2-1. BIツール(Cynapse)
・汎用的なバッチを作成することで新タイトルリリース時の対応がほぼ
必要なくなる
⇒リリース直後から分析が開始できる
[よくある問題]
複雑なデータ構造のためKPIを取得する分析実装が間に合わず、施策投入
のタイミングを逃してしまう
・必要なデータの所在や形式を特定するのが容易になる
⇒アドホック分析や、業務引き継ぎ等で無駄な作業がなくなる
[よくある問題]
分析要件に応じたデータを探すのが一苦労](https://image.slidesharecdn.com/201618dlforslideshare-160217234907/75/Spark-BigQuery-23-2048.jpg)

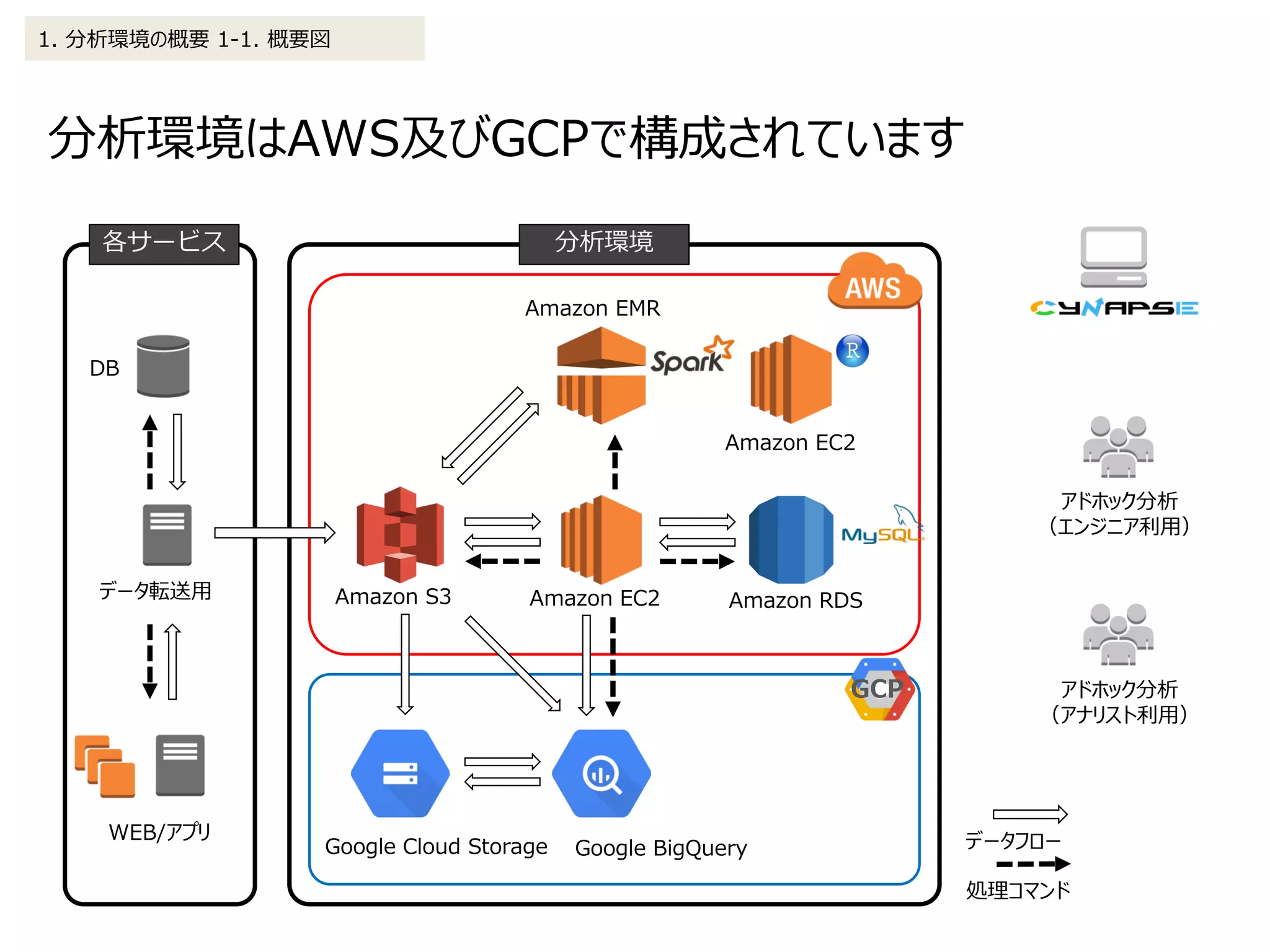
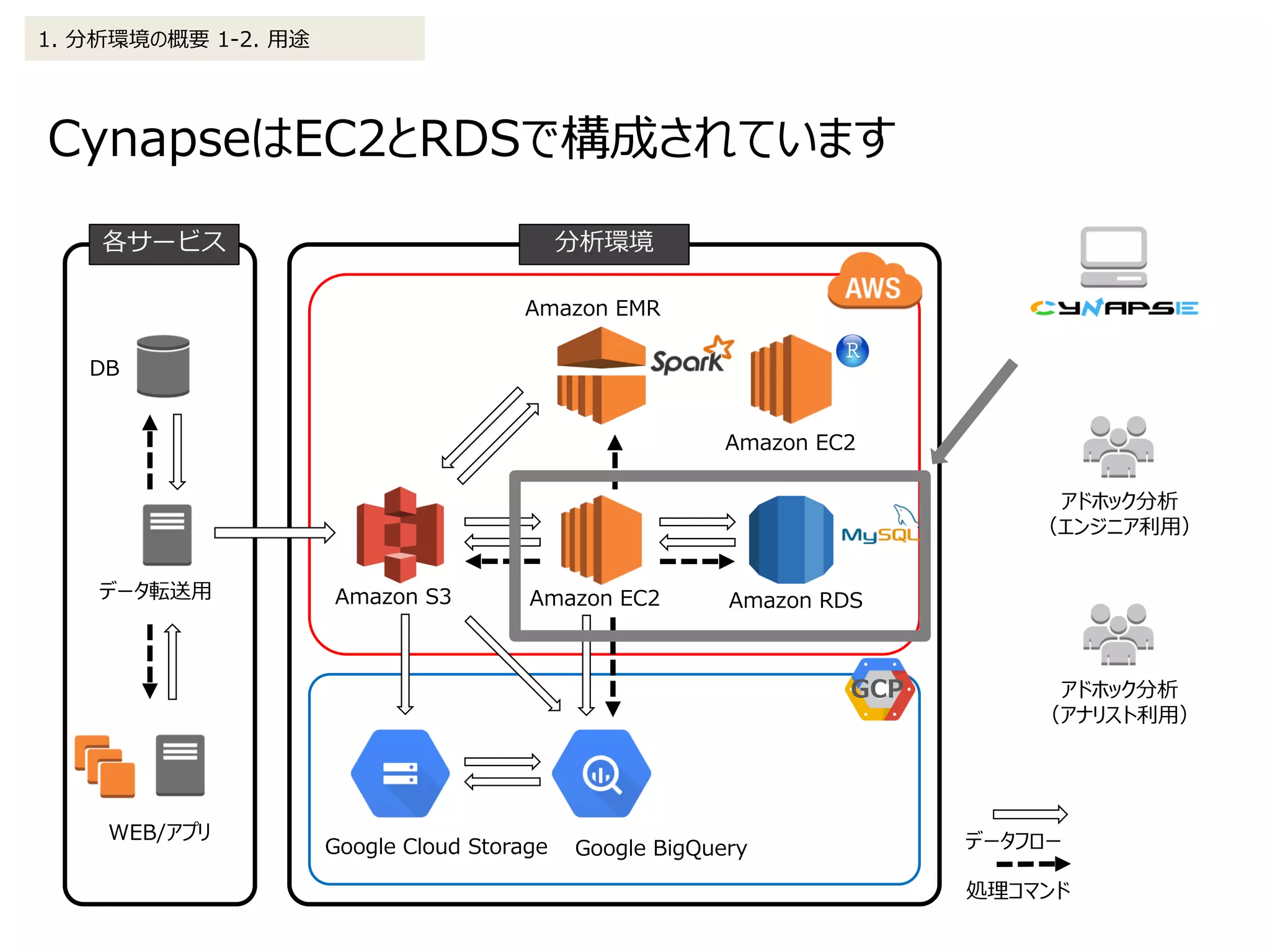
![Cynapseに表示するログデータをEMR(Spark)で処理する
場合は下記フローとなります
2. データ処理の詳細 2-1. BIツール(Cynapse)
(1)EMR(Spark)を起動、及びJSONで定義した処理((2)以降)を実行
(2)Sparkクラスタに設定ファイル、実行ファイルをS3から展開
(3)前処理及び集計処理実行
(4)処理完了(S3に結果を出力)
s3://XXXXXX/XXX/OUTPUT/retention/20160101/xxxxxxx
aws emr create-cluster --name "spark-cynapse-fmt"¥
--release-label emr-4.2.0¥
--log-uri "s3://xxxxxxx/emr_logs/"¥
--enable-debugging¥
--applications Name=Hadoop Name=Hive Name=Spark¥
--ec2-attributes KeyName=xxxxxx¥
--instance-type m3.xlarge¥
--instance-count 3¥
--use-default-roles¥
--auto-terminate¥
--steps "file:///xxxx/xxxx/xxxx/daily_batch.json"
[
{
"Name": "Download Files",
"Type": "Spark",
"ActionOnFailure": "CONTINUE",
"Args": [
"--deploy-mode",
"cluster",
"s3://xxxxx/xxxxx/download_files.py"
]
},
・
・
・
{
"Name": "Sumup",
"Type": "Spark",
"ActionOnFailure": "CONTINUE",
"Args": [
"--deploy-mode",
"client",
"file:///xxxxx/xxxxx/run.py"
]
}
]](https://image.slidesharecdn.com/201618dlforslideshare-160217234907/75/Spark-BigQuery-25-2048.jpg)









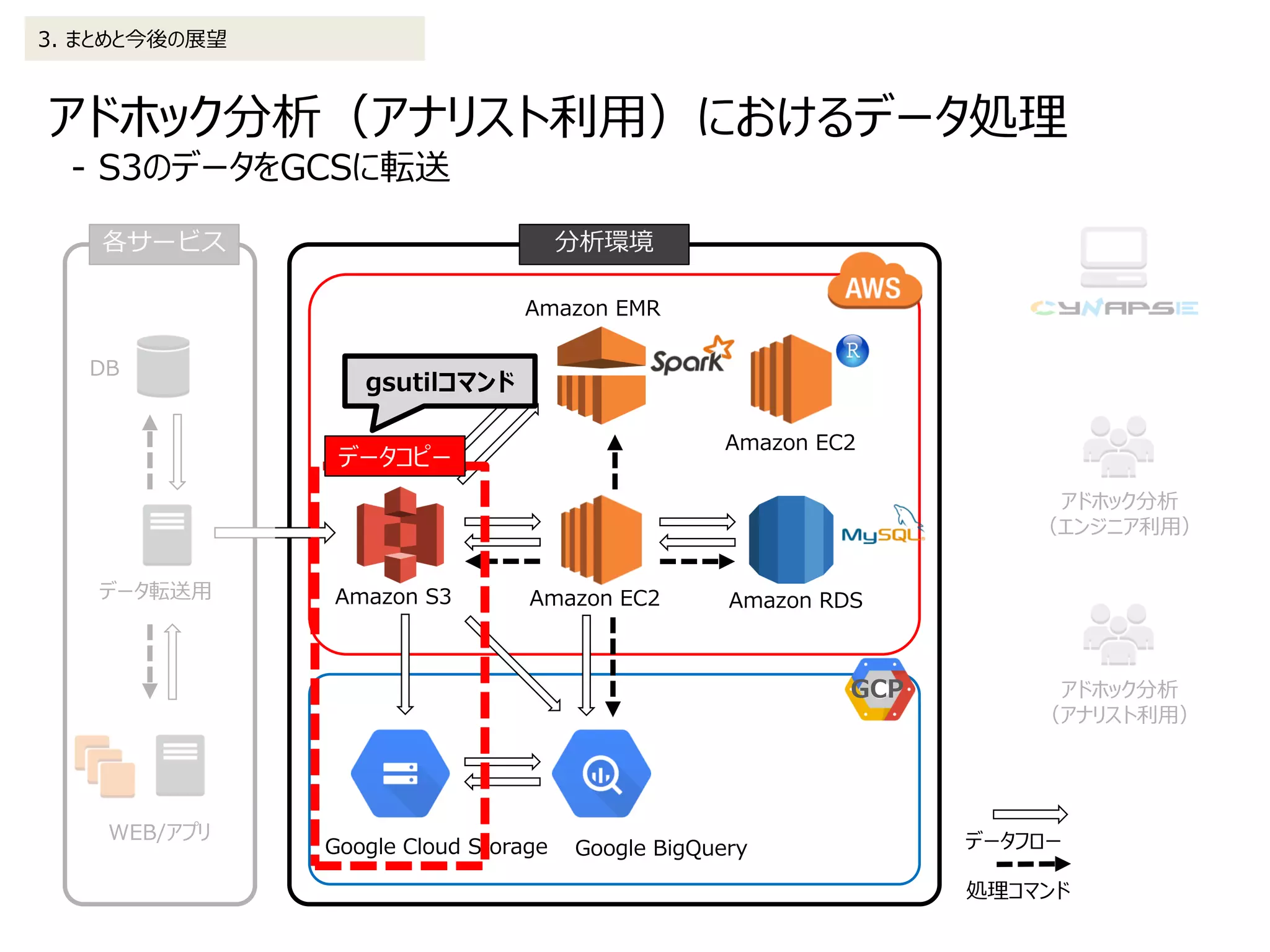
![使用するデータは下記の手順でBigQueryに格納しています
2. データ処理の詳細 2-3. アドホック分析(アナリスト利用)
• テーブルは日付単位で分ける
(コンテンツコード_YYYYMMDD)
(1)S3からGCSにデータコピー(google-cloud-sdkを利用)
※赤字部分はスクリプトで動的に変更
(2)GCSからBigQueryにデータをロード(google-cloud-sdkを利用)
※赤字部分はスクリプトで動的に変更
gsutil -m cp s3://xxxxxx/<コンテンツID>/<テーブル名>/<YYYYMM>/*<YYYYMMDD>* gs://xxxxxx/<コンテンツID>/<
テーブル名>/<YYYYMM>/<YYYYMMDD>/
bq load --source_format=CSV --field_delimiter=‘¥t’ <データセット名>.<コンテンツID>_<YYYYMMDD> gs://xxxxxxx/<コ
ンテンツID>/<テーブル名>/<YYYYMM>/<YYYYMMDD>/* /home/xxxx/batch/gcp/fmt/schema/<フォーマットバージョン
>/<テーブル名>.json
[
{
"name": "user_id",
"type": "INTEGER"
},
・
・
・
{
"name": "regist_date",
"type": "STRING"
}
]
[ポイント]
JSONでスキーマ定義](https://image.slidesharecdn.com/201618dlforslideshare-160217234907/75/Spark-BigQuery-36-2048.jpg)
![実行サンプル(BigQuery)
2. データ処理の詳細 2-3. アドホック分析(アナリスト利用)
SELECT
a.user_id,
SUM(b.price)
FROM
TABLE_QUERY(login,'REGEXP_MATCH(table_id, r"^aaa_20160101")') a
JOIN EACH
TABLE_QUERY(sales,'REGEXP_MATCH(table_id, r"^aaa_201512")') b
ON
a.user_id = b.user_id
GROUP EACH BY
a.user_id;
• 日付分割されたテーブルを正規表現で必要な単位に連結
⇒BiqQueryは従量課金のため無駄なデータ走査を発生させない
[ポイント]
2016/1/1にログインしたユーザが2015/12に購入した金額の集計](https://image.slidesharecdn.com/201618dlforslideshare-160217234907/75/Spark-BigQuery-37-2048.jpg)


![単語の出現頻度をRMeCabで集計するサンプル
2. データ処理の詳細 2-3. アドホック分析(アナリスト利用)
(1)単語の出現頻度を計算する。
q2_words <- RMeCabFreq("q2.txt")
(2)結果表示を「名詞」、「動詞」、「形容詞」だけにする。
q2_words_results <- q2_words[(q2_words$Info1 == "名詞" | q2_words$Info1 == "動詞" | q2_words$Info1
== "形容詞"),]
(3)件数が多いものから降順にソートする。
q2_words_sort <- q2_words_results[order(-q2_words_results$Freq),]
(4)上位50件を表示
head(q2_words_sort,50)](https://image.slidesharecdn.com/201618dlforslideshare-160217234907/75/Spark-BigQuery-40-2048.jpg)
![連続する単語の出現頻度をRMeCabで集計するサンプル
(3単語を集計)
2. データ処理の詳細 2-3. アドホック分析(アナリスト利用)
(1)出現頻度を計算する。
q2_3gram <- Ngram("q2.txt", type=1, pos=c("名詞","動詞","形容詞"), N=3)
(2)件数が多いものから降順にソートする。
q2_3gram_sort <- q2_3gram[order(-q2_3gram$Freq),]
(3)上位50件を表示
head(q2_3gram_sort,50)
[アバター-保存-数] 1000
[キャラ-本編-配信] 900
[他-イケメン-シリーズ] 800
[ほしい-衣装-箱] 750
[早い-配信-する] 500
(e.g. 要望アンケート)](https://image.slidesharecdn.com/201618dlforslideshare-160217234907/75/Spark-BigQuery-41-2048.jpg)