Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Atsushi Kurumada
PPTX, PDF
6,435 views
リクルートライフスタイルの考える ストリームデータの活かし方(Hadoop Spark Conference2016)
リクルートライフスタイルの考える ストリームデータの活かし方 ~AWS + Kafka + Spark Streaming~
Engineering
◦
Read more
16
Save
Share
Embed
Embed presentation
Download
Downloaded 70 times
1
/ 54
2
/ 54
3
/ 54
4
/ 54
5
/ 54
6
/ 54
7
/ 54
8
/ 54
9
/ 54
10
/ 54
11
/ 54
12
/ 54
13
/ 54
14
/ 54
15
/ 54
16
/ 54
17
/ 54
18
/ 54
19
/ 54
20
/ 54
21
/ 54
22
/ 54
23
/ 54
24
/ 54
25
/ 54
26
/ 54
27
/ 54
28
/ 54
29
/ 54
30
/ 54
31
/ 54
32
/ 54
33
/ 54
34
/ 54
35
/ 54
36
/ 54
37
/ 54
38
/ 54
39
/ 54
40
/ 54
41
/ 54
42
/ 54
43
/ 54
44
/ 54
45
/ 54
46
/ 54
47
/ 54
48
/ 54
49
/ 54
50
/ 54
51
/ 54
52
/ 54
53
/ 54
54
/ 54
More Related Content
PPTX
OSSプロジェクトへのコントリビューション はじめの一歩を踏み出そう!(Open Source Conference 2022 Online/Spring...
by
NTT DATA Technology & Innovation
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PPTX
HashMapとは?
by
Trash Briefing ,Ltd
PPTX
Apache Spark 2.4 and 3.0 What's Next?
by
NTT DATA Technology & Innovation
PDF
HDFS vs. MapR Filesystem
by
日本ヒューレット・パッカード株式会社
PPTX
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
OSSプロジェクトへのコントリビューション はじめの一歩を踏み出そう!(Open Source Conference 2022 Online/Spring...
by
NTT DATA Technology & Innovation
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
HashMapとは?
by
Trash Briefing ,Ltd
Apache Spark 2.4 and 3.0 What's Next?
by
NTT DATA Technology & Innovation
HDFS vs. MapR Filesystem
by
日本ヒューレット・パッカード株式会社
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
What's hot
PDF
Javaの進化にともなう運用性の向上はシステム設計にどういう変化をもたらすのか
by
Yoshitaka Kawashima
PDF
CRDT in 15 minutes
by
Shingo Omura
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
PPTX
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
PDF
入門 Kubeflow ~Kubernetesで機械学習をはじめるために~ (NTT Tech Conference #4 講演資料)
by
NTT DATA Technology & Innovation
PDF
データ分析を支える技術 データ分析基盤再入門
by
Satoru Ishikawa
PDF
Foss4G Japan 2021 シェープファイルの真の後継規格 FlatGeobufの普及啓蒙活動
by
Kanahiro Iguchi
PPTX
PFNにおける研究開発(2022/10/19 東大大学院「融合情報学特別講義Ⅲ」)
by
Preferred Networks
PDF
LakeTahoe
by
Yahoo!デベロッパーネットワーク
PPTX
データ分析基盤を支えるエンジニアリング
by
Recruit Lifestyle Co., Ltd.
PDF
ベイズ推定とDeep Learningを使用したレコメンドエンジン開発
by
LINE Corporation
PDF
YugabyteDBを使ってみよう - part2 -(NewSQL/分散SQLデータベースよろず勉強会 #2 発表資料)
by
NTT DATA Technology & Innovation
PDF
ワタシはSingletonがキライだ
by
Tetsuya Kaneuchi
PDF
10年効く分散ファイルシステム技術 GlusterFS & Red Hat Storage
by
Etsuji Nakai
PDF
ネットワーク運用自動化の実際〜現場で使われているツールを調査してみた〜
by
Taiji Tsuchiya
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
AWS Black Belt Online Seminar 2018 AWS上の位置情報
by
Amazon Web Services Japan
PDF
データ基盤の従来~最新の考え方とSynapse Analyticsでの実現
by
Ryoma Nagata
PDF
マイクロにしすぎた結果がこれだよ!
by
mosa siru
Javaの進化にともなう運用性の向上はシステム設計にどういう変化をもたらすのか
by
Yoshitaka Kawashima
CRDT in 15 minutes
by
Shingo Omura
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
入門 Kubeflow ~Kubernetesで機械学習をはじめるために~ (NTT Tech Conference #4 講演資料)
by
NTT DATA Technology & Innovation
データ分析を支える技術 データ分析基盤再入門
by
Satoru Ishikawa
Foss4G Japan 2021 シェープファイルの真の後継規格 FlatGeobufの普及啓蒙活動
by
Kanahiro Iguchi
PFNにおける研究開発(2022/10/19 東大大学院「融合情報学特別講義Ⅲ」)
by
Preferred Networks
LakeTahoe
by
Yahoo!デベロッパーネットワーク
データ分析基盤を支えるエンジニアリング
by
Recruit Lifestyle Co., Ltd.
ベイズ推定とDeep Learningを使用したレコメンドエンジン開発
by
LINE Corporation
YugabyteDBを使ってみよう - part2 -(NewSQL/分散SQLデータベースよろず勉強会 #2 発表資料)
by
NTT DATA Technology & Innovation
ワタシはSingletonがキライだ
by
Tetsuya Kaneuchi
10年効く分散ファイルシステム技術 GlusterFS & Red Hat Storage
by
Etsuji Nakai
ネットワーク運用自動化の実際〜現場で使われているツールを調査してみた〜
by
Taiji Tsuchiya
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
AWS Black Belt Online Seminar 2018 AWS上の位置情報
by
Amazon Web Services Japan
データ基盤の従来~最新の考え方とSynapse Analyticsでの実現
by
Ryoma Nagata
マイクロにしすぎた結果がこれだよ!
by
mosa siru
Similar to リクルートライフスタイルの考える ストリームデータの活かし方(Hadoop Spark Conference2016)
PDF
リクルートのビッグデータ活用基盤とデータ活用に向けた取組み
by
Recruit Technologies
PDF
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
PDF
リクルートのビッグデータ活用基盤とデータ活用に向けた取組み
by
Recruit Technologies
PDF
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
PDF
Developers Summit 2018: ストリームとバッチを融合したBigData Analytics ~事例とデモから見えてくる、これからのデー...
by
オラクルエンジニア通信
PPTX
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
PDF
ビッグデータ・オープンデータ活用の現状〜ビッグデータ活用概要編〜
by
Takafumi Nakanishi
PPTX
ビッグデータ活用支援フォーラム
by
Recruit Technologies
PDF
クラウドストレージの基礎知識(Cloudian white paper)
by
CLOUDIAN KK
PDF
AWS初心者向けWebinar AWSでBig Data活用
by
Amazon Web Services Japan
PPTX
WebDB Forum 2012 基調講演資料
by
Recruit Technologies
PDF
業界での勝ち組になるためのビッグデータの取り組み~ここから始めよう!~
by
IBM Systems @ IBM Japan, Ltd.
PPTX
ビッグデータ&データマネジメント展
by
Recruit Technologies
PPT
Big data解析ビジネス
by
Mie Mori
PDF
『ビッグデータ時代を勝ち抜くデータマネジメント』 セミナー資料
by
Akihiko Uchino
PDF
リクルート式ビッグデータ活用術
by
Recruit Technologies
PPT
Big data harvardbusiessreview20121112
by
Dennis Sugahara
PPTX
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
PDF
[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop
by
Insight Technology, Inc.
PPTX
巨大なサービスと膨大なデータを支えるプラットフォーム
by
Tetsutaro Watanabe
リクルートのビッグデータ活用基盤とデータ活用に向けた取組み
by
Recruit Technologies
変わる!? リクルートグループのデータ解析基盤
by
Recruit Technologies
リクルートのビッグデータ活用基盤とデータ活用に向けた取組み
by
Recruit Technologies
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
Developers Summit 2018: ストリームとバッチを融合したBigData Analytics ~事例とデモから見えてくる、これからのデー...
by
オラクルエンジニア通信
ビッグデータ処理データベースの全体像と使い分け 2018年version
by
Tetsutaro Watanabe
ビッグデータ・オープンデータ活用の現状〜ビッグデータ活用概要編〜
by
Takafumi Nakanishi
ビッグデータ活用支援フォーラム
by
Recruit Technologies
クラウドストレージの基礎知識(Cloudian white paper)
by
CLOUDIAN KK
AWS初心者向けWebinar AWSでBig Data活用
by
Amazon Web Services Japan
WebDB Forum 2012 基調講演資料
by
Recruit Technologies
業界での勝ち組になるためのビッグデータの取り組み~ここから始めよう!~
by
IBM Systems @ IBM Japan, Ltd.
ビッグデータ&データマネジメント展
by
Recruit Technologies
Big data解析ビジネス
by
Mie Mori
『ビッグデータ時代を勝ち抜くデータマネジメント』 セミナー資料
by
Akihiko Uchino
リクルート式ビッグデータ活用術
by
Recruit Technologies
Big data harvardbusiessreview20121112
by
Dennis Sugahara
ビッグデータ処理データベースの全体像と使い分け - 2017年 Version -
by
Tetsutaro Watanabe
[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop
by
Insight Technology, Inc.
巨大なサービスと膨大なデータを支えるプラットフォーム
by
Tetsutaro Watanabe
リクルートライフスタイルの考える ストリームデータの活かし方(Hadoop Spark Conference2016)
1.
リクルートライフスタイルの考える ストリームデータの活かし方 ~AWS + Kafka
+ Spark Streaming~ 車田 篤史 ネットビジネス本部 アーキテクト1グループ データ基盤チーム 堤 崇行 ITサービス・ペイメント事業本部 放送・情報サービス事業部 情報ビジネス統括部
2.
1. リクルートスタイルにおけるビッグデータとは 2. ビッグデータの過去・現在・未来 3.
Waterプロジェクトとは 4. ポンパレモールでの利用例 5. 技術詳細&ストリーム処理Tips 6. まとめ アジェンダ1
3.
• 車田 篤史(くるまだ
あつし) • 1999年 信号機メーカーで回路設計とか組込みLinuxやってました • 2011年 広告配信系のインフラ(HadoopとかDWH)をやってました • 2015年 リクルートライフスタイル入社 • データ基盤チームでビッグデータと日々向かい合っています • 趣味:カメラ、時計・万年筆・英国靴・オーディオ機器 https://www.facebook.com/atsushi.kurumada 自己紹介2
4.
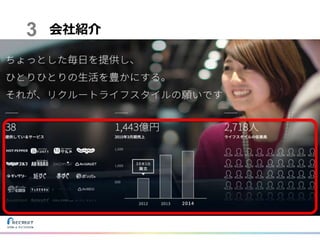
会社紹介3
5.
堤 崇行 (つつみ
たかゆき) • 所属 – 株式会社NTTデータ • 経歴 – 2011年 Webアプリ開発者 – 2012年 データ活用(分析基盤、サーバーサイド開発) • 最近使っている技術 – Apache Spark, Ansible, Scala, Python, Haskell(趣味) 自己紹介4
6.
リクルートライフスタイル様の ビジネスパートナーとして データの価値創出や戦略を共に考え データ活用の世界観を共に描いていけるよう サポートしています。 会社紹介5
7.
リクルートライフスタイルのミッション6
8.
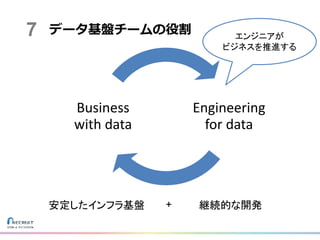
データ基盤チームの役割 Engineering for data Business with data エンジニアが ビジネスを推進する 安定したインフラ基盤
継続的な開発+ 7
9.
• 容量(Volume) – データ量の制限なく保存できる •
集約(Variety) – 多様なデータが1箇所に集まっている • 鮮度(Velocity) – 保存データをすぐに利用できる • 活用 – データを活用できなかったら意味が無い ビッグデータにおける普遍的テーマ8
10.
• 容量 – 日々増加し続けるデータ量 (数十TB規模に増加、行動ログは1,000億レコード規模) •
集約 – RDB/ファイル等にデータが点在している • 鮮度 – 集計処理に時間がかかる • 活用 – あまり活用できていない… リクルートライフスタイルの過去9
11.
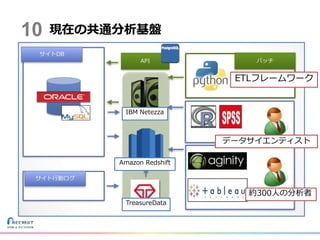
現在の共通分析基盤 約300人の分析者 データサイエンティスト IBM Netezza Amazon Redshift TreasureData ETLフレームワーク 10
12.
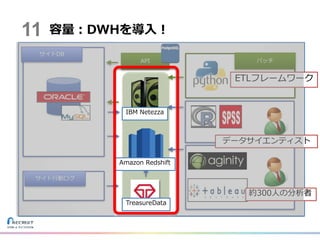
容量:DWHを導入! 約300人の分析者 データサイエンティスト IBM Netezza Amazon Redshift TreasureData ETLフレームワーク 11
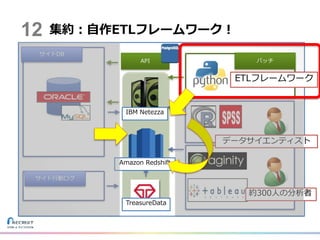
13.
集約:自作ETLフレームワーク! 約300人の分析者 データサイエンティスト IBM Netezza Amazon Redshift TreasureData ETLフレームワーク 12
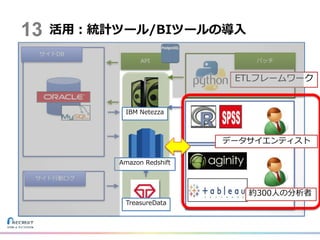
14.
活用:統計ツール/BIツールの導入 約300人の分析者 データサイエンティスト IBM Netezza Amazon Redshift TreasureData ETLフレームワーク 13
15.
☆まだまだ課題はたくさん… 14
16.
• 集約 – レガシーなリソースからもデータが取得できる –
過去〜直近のデータも一様に取得できる – データハブ基盤が必要! • 鮮度 – リアルタイムにデータを集計・利用したい – ストリーム処理基盤が必要! Waterプロジェクトを立ち上げ! 乗り越えるべき課題15
17.
• 「蛇口をひねれば新鮮な水が出てくる」 • Kafkaを使用したデータハブ基盤の構築 •
Sparkを使用したストリーム処理基盤の構築 • 「データから創出できるサービス」を検討し、 エンジニアがビジネスに貢献する! Waterプロジェクトとは16
18.
vs ☆検証→開発→運用環境を即座に構築できる! ☆キャパシティ設計可能なサービスは便利! (DynamoDB/API Gateway等) 検討したもの(クラウド or
オンプレミス)17
19.
vs ☆コアテクノロジーについてはOSSを採用 ☆汎用性の高いハブ基盤を目指した! 検討したもの(データハブ基盤)18
20.
vs ☆ (MLlib等)コンポーネントが多い! ☆ 今後の展開を見据えてSpark
Streaming 検討したもの(ストリーム処理基盤)19
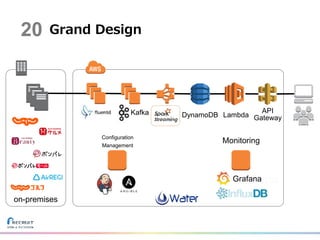
21.
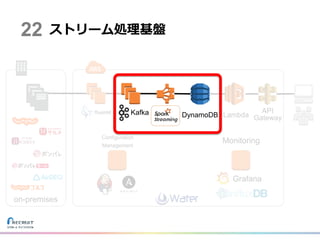
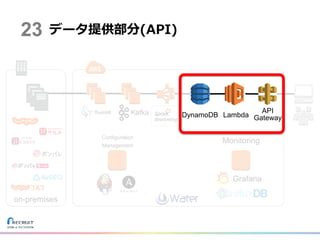
Grand Design DynamoDB Lambda API Gateway Kafka on-premises Configuration Management Monitoring Grafana 20
22.
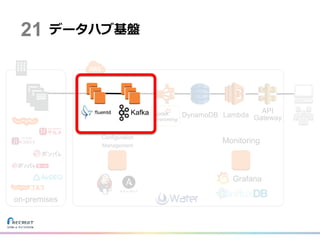
データハブ基盤 DynamoDB Lambda API Gateway on-premises Configuration Management Monitoring Grafana 21 Kafka
23.
ストリーム処理基盤 Lambda API Gateway on-premises Configuration Management Monitoring Grafana 22 Kafka DynamoDB
24.
データ提供部分(API) Kafka on-premises Configuration Management Monitoring Grafana 23 DynamoDB Lambda API Gateway
25.
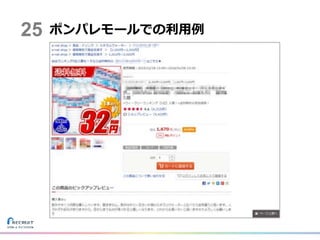
• 鮮度の高いデータを活用することで創出できる サービス案を検討してみた – 「みんなが注目している」商品を知りたい! –
売り切れてしまう前に手に入れたい! – 興味を持っている(商品を見ている)人に伝えたい! ポンパレモール(ECサイト)上で 「xx人が見ています」をテストケースとして構築! ビジネス要件24
26.
ポンパレモールでの利用例25
27.
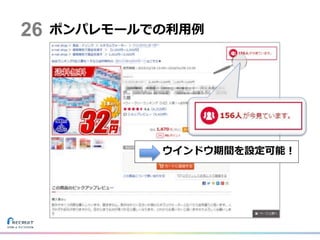
ポンパレモールでの利用例26 ウインドウ期間を設定可能!
28.
ちなみに効果は? • A/Bテストの結果、 ☆104%(スマホ) ☆115%(PC) 27
29.
☆技術詳細&ストリーム処理Tips! 28
30.
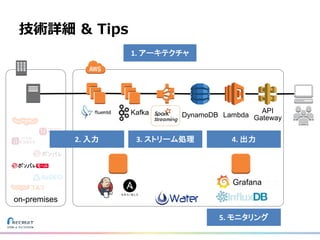
技術詳細 & Tips DynamoDB
Lambda API Gateway Kafka on-premises Grafana 2. 入力 3. ストリーム処理 4. 出力 5. モニタリング 1. アーキテクチャ
31.
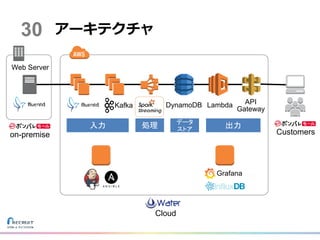
アーキテクチャ DynamoDB Lambda API Gateway Kafka Web
Server Grafana on-premise Customers Cloud 30 入力 処理 データ ストア 出力
32.
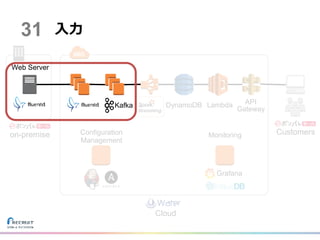
Cloud Customerson-premise 入力 DynamoDB Lambda API Gateway Configuration Management Monitoring Grafana 31 Kafka Web
Server
33.
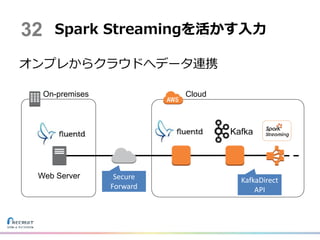
オンプレからクラウドへデータ連携 Spark Streamingを活かす入力 Secure Forward Web Server Kafka On-premises
Cloud 32 KafkaDirect API
34.
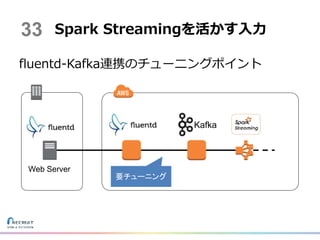
fluentd-Kafka連携のチューニングポイント Spark Streamingを活かす入力 Web Server Kafka 33 要チューニング
35.
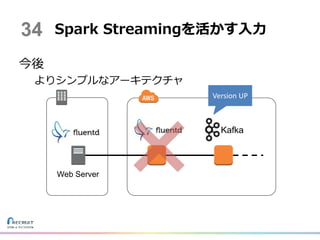
今後 よりシンプルなアーキテクチャ Spark Streamingを活かす入力 Web Server Kafka Version
UP 34
36.
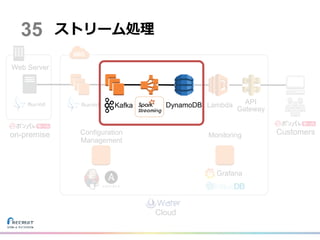
on-premise Customers Cloud ストリーム処理 Lambda API Gateway Web
Server Configuration Management Monitoring Grafana 35 DynamoDBKafka
37.
パーティション数 36 Spark Streaming
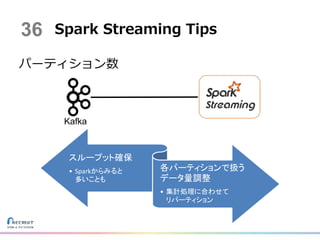
Tips Kafka スループット確保 • Sparkからみると 多いことも 各パーティションで扱う データ量調整 • 集計処理に合わせて リパーティション
38.
ログ設定 37 Spark Streaming
Tips Log Log ログ出力の定常的なチューニングが必要 • ローテーション • パージタイミング • エラーレベル 記憶域を 圧迫 とは要求レベルが異なるので別管理 新 詳細に残す 古 捨てる メトリクスは別途残す
39.
• Spark Streamingアプリの開発 –
理想 • 開発者のPCで実装・デバッグができる • テスト環境で本番同様に実行できる – 現実 • スペック不足による停止か環境問題か判別が難しい • 本番相当のテストまで問題を回収しきれない – 対策 • ロジックテストとシステムテストを切り分ける – ロジック部のテストができるよう関数化する – システムテストはAWSで本番同等の環境を用意する Spark Streaming活用時のポイント38
40.
• ストリーム処理を動かし続けるポイント – 理想 •
ストリーム処理は止まらず稼働を続ける – 現実 • Spark外の入出力部分起因のエラーも発生 • 1つ1つのエラーに対応すると 処理が終わらなくなり全体が停止する – 対策 • ストリーム処理向けエラーハンドリング – 握りつぶすエラーと 対応するエラーを選別する Spark Streaming活用時のポイント39 1224 h + 1111 Jobs !
41.
• 動き続けるストリーム処理の定義 – 理想 •
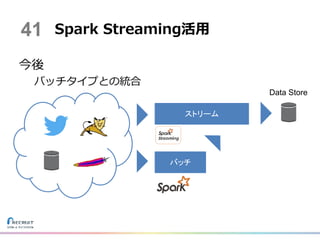
ストリーム処理は止まらず稼働を続ける – 現実 • 停止は発生する • ストリーム処理の停止とシステム全体の停止は異なる – 対策 • ビジネス要件を満たす稼働状況を定義し 影響を小さくするアーキテクチャにする – 情報鮮度の許容範囲を定める – ストリーム処理停止を出力部の停止に伝搬させない Spark Streaming活用時のポイント40
42.
今後 バッチタイプとの統合 Spark Streaming活用41 バッチ ストリーム Data Store
43.
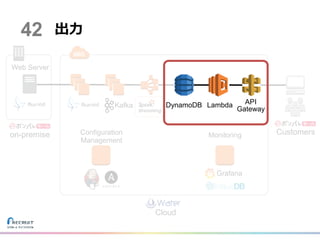
on-premise Customers Cloud 出力 Kafka Web Server Configuration Management Monitoring Grafana 42 DynamoDB
Lambda API Gateway
44.
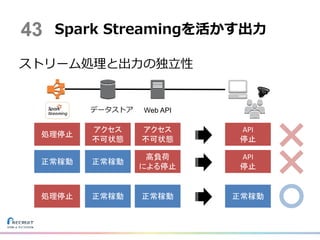
ストリーム処理と出力の独立性 Spark Streamingを活かす出力 データストア Web
API アクセス 不可状態 処理停止 API 停止 アクセス 不可状態 高負荷 による停止 正常稼動 正常稼動 API 停止 正常稼動処理停止 正常稼動 正常稼動 43
45.
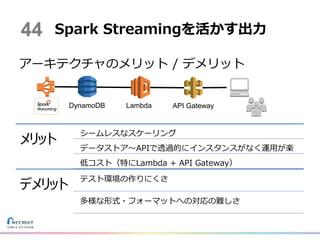
アーキテクチャのメリット / デメリット 44
Spark Streamingを活かす出力 DynamoDB Lambda API Gateway メリット シームレスなスケーリング データストア〜APIで透過的にインスタンスがなく運用が楽 低コスト(特にLambda + API Gateway) デメリット テスト環境の作りにくさ 多様な形式・フォーマットへの対応の難しさ
46.
• データストアとしてDynamoDBを選んだ理由 – データをUpdateする実装のため 書き込みと呼び出し常時発生 –
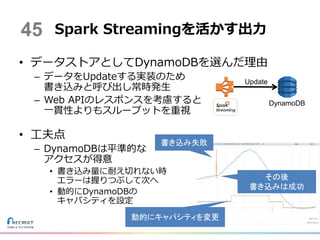
Web APIのレスポンスを考慮すると 一貫性よりもスループットを重視 • 工夫点 – DynamoDBは平準的な アクセスが得意 • 書き込み量に耐え切れない時 エラーは握りつぶして次へ • 動的にDynamoDBの キャパシティを設定 Spark Streamingを活かす出力 DynamoDB 45 動的にキャパシティを変更 書き込み失敗 Update その後 書き込みは成功
47.
今後 Spark Streamingを活かす出力 DynamoDB 46 Lambda API
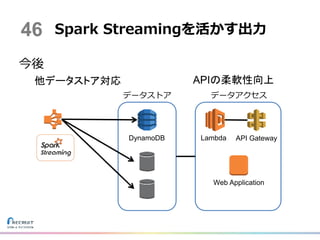
Gateway 他データストア対応 APIの柔軟性向上 Web Application データストア データアクセス
48.
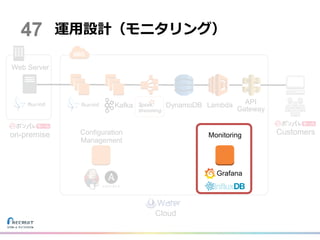
on-premise Customers Cloud 運用設計(モニタリング) DynamoDB Lambda
API Gateway Kafka Web Server Configuration Management 47 Monitoring Grafana
49.
時系列DBを利用した性能の観測・可視化 運用設計48 Grafana Dashboards AWS
CloudWatch Dashboards DynamoDB Lambda API Gateway Kafka
50.
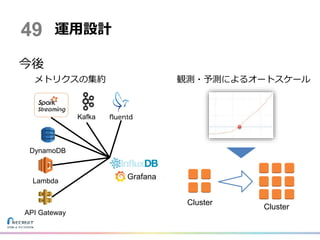
今後 運用設計49 Grafana DynamoDB Lambda API Gateway Kafka メトリクスの集約 観測・予測によるオートスケール Cluster Cluster
51.
振り返り • 少人数で機動力持って出来た! – 検証を重ねるべき部分は時間をかけつつ、短期で作り上げた •
「なかったら作る」の姿勢 – プロダクトとプロダクトの隙間は自分で埋める • OSSに対する取り組み – コアテクノロジーはOSSを使い、とことん性能検証 • AWSを選んだ理由 – 「AWSを使いこなす」はゴールではない – スケーラブルなインフラ&汎用的なサービスは使っていく • 性能観測についての取り組み – OSSを選択した以上、性能に対する取り組みは非常に重要 – 各種メトリクスを利用していく事で改善に取り組んだ 50
52.
• まだ道は半ばです! • やってみたいこと –
データソースを増やしてハブ化を推進! – 横展開 – 新しいサービスを作りたい! – 基盤を使ってサービス完成までの時間を短縮したい! • エンジニアがビジネスを創出する環境を作る! これから51
53.
WE ARE HIRING!52
54.
ご清聴ありがとうございました 53
Editor's Notes
#8
それでは、リクルートライフスタイルが、どのようなミッションを持って事業を行っているか、をお伝えしたいと思います。 「ちょっとした毎日を提供し、ひとりひとりの生活を豊かにする。 それが、リクルートライフスタイルの願いです」 私たちデータ基盤チームは、ビッグデータで支えるべく、日々改善に取り組んでいます。
Download









































































![[INSIGHT OUT 2011] b21 ひとつのデータベース技術では生き残れない part2 no sql, hadoop](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011b21part2nosqlhadoop-111114020909-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
