Recommended
PPTX
PPTX
PPTX
PPSX
HBaseとSparkでセンサーデータを有効活用 #hbasejp
PPTX
SparkとJupyterNotebookを使った分析処理 [Html5 conference]
PPTX
PPTX
PPTX
PDF
SparkやBigQueryなどを用いた�モバイルゲーム分析環境
PPTX
Pythonで入門するApache Spark at PyCon2016
PPTX
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント
PPTX
BigDataUnivercity 2017年改めてApache Sparkとデータサイエンスの関係についてのまとめ
PDF
PPTX
PDF
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
PPTX
PPTX
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築
PDF
PDF
Sparkを用いたビッグデータ解析 〜 前編 〜
PDF
本当にあったHadoopの恐い話�Blockはどこへきえた? (Hadoop / Spark Conference Japan 2016 ライトニングトー...
PPTX
Spark Streamingを使ってみた ~Twitterリアルタイムトレンドランキング~
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
PPTX
Apache cassandraと apache sparkで作るデータ解析プラットフォーム
PPTX
PDF
データ分析に必要なスキルをつけるためのツール~Jupyter notebook、r連携、機械学習からsparkまで~
PDF
PDF
データ活用をもっともっと円滑に!�~データ処理・分析基盤編を少しだけ~
PDF
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
PDF
なぜApache HBaseを選ぶのか? #cwt2013
PPTX
HBase×Impalaで作るアドテク�「GMOプライベートDMP」@HBaseMeetupTokyo2015Summer
More Related Content
PPTX
PPTX
PPTX
PPSX
HBaseとSparkでセンサーデータを有効活用 #hbasejp
PPTX
SparkとJupyterNotebookを使った分析処理 [Html5 conference]
PPTX
PPTX
PPTX
What's hot
PDF
SparkやBigQueryなどを用いた�モバイルゲーム分析環境
PPTX
Pythonで入門するApache Spark at PyCon2016
PPTX
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント
PPTX
BigDataUnivercity 2017年改めてApache Sparkとデータサイエンスの関係についてのまとめ
PDF
PPTX
PDF
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
PPTX
PPTX
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築
PDF
PDF
Sparkを用いたビッグデータ解析 〜 前編 〜
PDF
本当にあったHadoopの恐い話�Blockはどこへきえた? (Hadoop / Spark Conference Japan 2016 ライトニングトー...
PPTX
Spark Streamingを使ってみた ~Twitterリアルタイムトレンドランキング~
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
PPTX
Apache cassandraと apache sparkで作るデータ解析プラットフォーム
PPTX
PDF
データ分析に必要なスキルをつけるためのツール~Jupyter notebook、r連携、機械学習からsparkまで~
PDF
PDF
データ活用をもっともっと円滑に!�~データ処理・分析基盤編を少しだけ~
PDF
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
Viewers also liked
PDF
なぜApache HBaseを選ぶのか? #cwt2013
PPTX
HBase×Impalaで作るアドテク�「GMOプライベートDMP」@HBaseMeetupTokyo2015Summer
PDF
「新製品 Kudu 及び RecordServiceの概要」 #cwt2015
PPTX
PDF
#cwt2016 Apache Kudu 構成とテーブル設計
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
PDF
忙しい人の5分で分かるMesos入門 - Mesos って何だ?
PDF
Apache Kudu - Updatable Analytical Storage #rakutentech
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. ちょっとだけコード(KafkaのStream作成部分)
object ActivitySummary{
def main(args: Array[String]){
val conf = new SparkConf().setAppName("ActivitySummary")
val ssc = new StreamingContext(conf,Seconds(5))
val kafkaParams = Map[String,String](“metadata.broker.list” -> “172.27.xxx.xx:9092,・・・")
val kafkaStream =
KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,Se
t("raw_tracking"))
14. ちょっとだけコード(集計処理の抜粋)
//中間データからPVを数えるよ!
val pv = middle_data
.filter(_._1.contains("_pv_"))
.map(x => x._1.substring(0,x._1.lastIndexOf("_")))
.countByValue()
//pvの移動平均用
val window_pv = middle_data
.filter(_._1.contains("_pv_"))
.map(x => "window_" + x._1.substring(0,x._1.lastIndexOf("_")))
.countByValueAndWindow(Seconds(60),Seconds(5))
//中間データからuuの重複排除
var uu = middle_data
.filter(_._1.contains("_uu_"))
.map(x => x._1)
.transform(rdd => rdd.distinct())
.map(x => x.substring(0,x.lastIndexOf("_")))
.countByValue()
15. ちょっとだけコード(Streamingからの書き出し抜粋)
class KafkaProducer private(brokerList:String){
val props:Properties = new Properties()
props.put("metadata.broker.list",brokerList)
props.put("serializer.class", "kafka.serializer.StringEncoder")
props.put("request.required.acks", "1")
val config:ProducerConfig = new ProducerConfig(props)
val producer:Producer[String,String] = new Producer[String,String](config)
def send(topicName:String,msg:String){
val data:KeyedMessage[String,String] = new KeyedMessage[String,String](topicName,msg)
producer.send(data)
}
def close(){}
}
object KafkaProducer{
private val kProducer = new KafkaProducer(“172.27.100.14:9092,・・・ ")
def getInstance():KafkaProducer ={ kProducer }
def apply():KafkaProducer ={ getInstance }
}
16. 17. 18. 19. 20. 21. 22. 23. Editor's Notes #6 皆知ってるSparkCore。
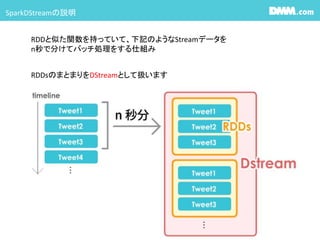
今回はSparkStreamingの話
リソースマネージャーとしてYARNとMesos
DataSourceとしてStream,HDFS,Cassandraとかが上げられます。
DMMではYarnの上で動かしてます。
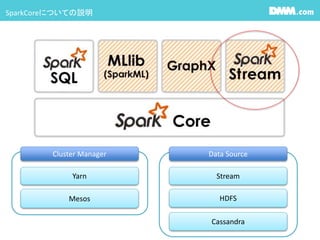
#7 その他のSparkのライブラリとの違いはデータ操作の基本がRDDかDstreamかの違い。
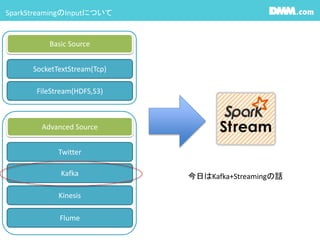
#8 SparkStreamingはInputとして
Basic Source:SocketTestStream,FileStream
AdvancedSource,Twitter,Kafka,Kinesis,Flumeが用意されていて、様々なSourceに合わせて簡単にStreamingを始めることができます。
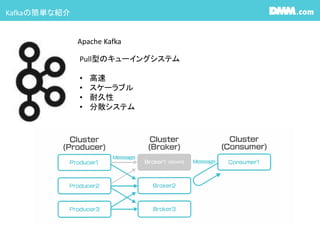
#9 Kafkaの話
Kafkaのメッセージングの仕組みとして
メッセージを投入するProducer
メッセージを処理するBroker
メッセージを受け取るConsumerに分かれます。
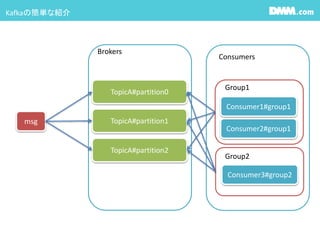
#10 Kafkaの話
メッセージはTopic単位に入れることができ、TopicからConsumerがデータを取得します。
ConsumerはGroupを作る事ができ、Group毎に一貫したデータを取得できます。
さらにpartitionを分ける事ができ、msgをpartition毎に入れる事が出来ます。
また、ConsumerはGroupを作る事ができ、Group毎に一貫したデータを取得できます。 #11 じゃぁ、これらを組み合わせて何をやってるのかと言うと、
こんな感じ
#12 すごい余談ですが、
DMMが行動解析やってる話をすると、良く「え“」って言われます。
大丈夫です。世の男性の皆様安心して下さい。
弊社のビッグデータ基盤に個人が特定出来るデータ乗ってません。あと今後ものせません。
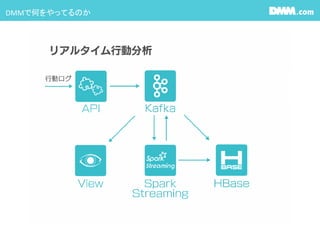
安心して使ってください。 #13 行動ログ(JS) -> apiで受け取りKafkaに入れる
kafka -> sparkStreamingで集約・計算処理を行い、HBaseとKafkaに書き込みを行う
kafka -> websocketで垂れ流し、例えばviewに流し込み描画する
Kafkaから見ると
APIがProducer,SparkStreamingがConsumer
SparkStreamingがProducer、ViewerがConsumer
になります。
#14 Seconds(5)の部分:まず、このStreaming処理は5秒に1度処理されます。(5秒間隔のマイクロバッチ処理)
kafkaParameterとして、KafkaのBrokerListを渡してます。
raw_trackingというtopicからデータを取ってきてます。
KafkaUtils.createDirectStreamを今回つかってます。
#15 FilterやMap等、RDDでおなじみの物や、transform、countByValueAndWindow等Dstream特有の物と様々な操作が用意されてます。
#16 Kafkaから取得して、集計したデータを再度Kafkaに戻す部分
topic名とデータを受け取ってkafkaに投げてるだけの簡単仕様になってます。 #17 おなじみのSparkUI
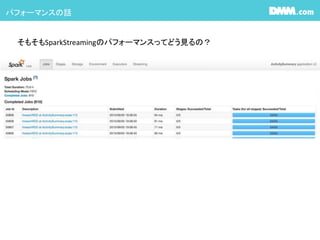
各マイクロバッチ処理をドリルダウンして行くとdurationや各stageでの詳細な情報が見れます #18 SparkStreamingを使う場合はSparkUIのStreaming部分に情報が表示されます。
マイクロバッチの間隔が表示されてます。
Last Batchに最後に動いたバッチの時間が表示されてます。
ちなみに75%値がBatchInterval超える場合はどんどんDelayが溜まって行き取り返しがつかなくなるので注意
こちらはReceiverの情報で、どのくらいのレコード数を処理したか等が見れます
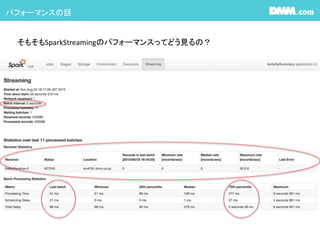
#19 Sparkのみの構築だと今更1.3を使う事はないだろうけど、CDH使うときは1.3が入るので気をつけて。
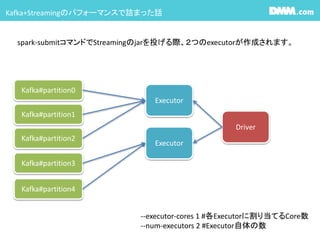
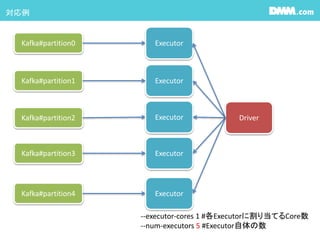
ReceiverStatisticsが見れないので、maxRateの設定がし辛い #20 1つのexecutorにどれだけのcoreが割り当てられるか?はClusterのSpec次第ですが、
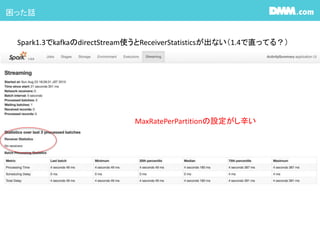
少なくともStreamingのCore数がKafkaのPartition数を下回るとすごく処理が遅いです。DirectStreamを使う場合kafkaとRDDのpartitionが1:1になるので
それを処理できるcore数又はexecutor数を当てて上げましょう
YARNの場合はcoreはディフォルト1です。 #21 1つのexecutorにどれだけのcoreが割り当てられるか?はClusterのSpec次第ですが、
少なくともStreamingのCore数がKafkaのPartition数を下回るとすごく処理が遅いです。DirectStreamを使う場合kafkaとRDDのpartitionが1:1になるので
それを処理できるcore数又はexecutor数を当てて上げましょう
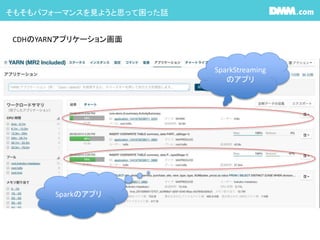
YARNの場合はcoreはディフォルト1です。 #22 CDHとっても便利です。
どのくらいCPU使ってるか?メモリの割当どうか?Mapperがどのくらい終わってるか?Reducerがどのくらい終わってるかを見る事が出来る
でもSparkStremingは出力されない #23 CDHはチャートも見れてとっても便利です。
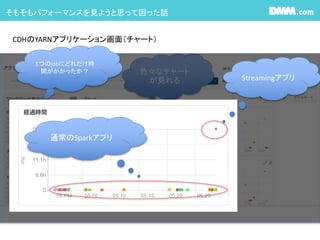
CPU時間とかメモリの割当とかHDFSのバイト数とかどのくらいの時間がかかったとか見れる
でも此処に中途半端にSparkStreamingのアプリケーションも入っちゃう
経過時間の分布でチューニング対象のSparkアプリケーション調べようとすると
SparkStreamingのアプリが邪魔して使い物にならない・・・・





![ちょっとだけコード(KafkaのStream作成部分)
object ActivitySummary{
def main(args: Array[String]){
val conf = new SparkConf().setAppName("ActivitySummary")
val ssc = new StreamingContext(conf,Seconds(5))
val kafkaParams = Map[String,String](“metadata.broker.list” -> “172.27.xxx.xx:9092,・・・")
val kafkaStream =
KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,Se
t("raw_tracking"))](https://image.slidesharecdn.com/sparkstreamingkafkasparkstreaming-150910015358-lva1-app6892/85/Spark-streaming-kafka-sparkstreaming-13-320.jpg)

![ちょっとだけコード(Streamingからの書き出し抜粋)
class KafkaProducer private(brokerList:String){
val props:Properties = new Properties()
props.put("metadata.broker.list",brokerList)
props.put("serializer.class", "kafka.serializer.StringEncoder")
props.put("request.required.acks", "1")
val config:ProducerConfig = new ProducerConfig(props)
val producer:Producer[String,String] = new Producer[String,String](config)
def send(topicName:String,msg:String){
val data:KeyedMessage[String,String] = new KeyedMessage[String,String](topicName,msg)
producer.send(data)
}
def close(){}
}
object KafkaProducer{
private val kProducer = new KafkaProducer(“172.27.100.14:9092,・・・ ")
def getInstance():KafkaProducer ={ kProducer }
def apply():KafkaProducer ={ getInstance }
}](https://image.slidesharecdn.com/sparkstreamingkafkasparkstreaming-150910015358-lva1-app6892/85/Spark-streaming-kafka-sparkstreaming-15-320.jpg)





![SparkとJupyterNotebookを使った分析処理 [Html5 conference]](https://cdn.slidesharecdn.com/ss_thumbnails/html5conference-160903045852-thumbnail.jpg?width=640&height=640&fit=bounds)






























