More Related Content

PPTX
Hive on Spark の設計指針を読んでみた 
PDF
Sparkによる GISデータを題材とした時系列データ処理 (Hadoop / Spark Conference Japan 2016 講演資料) 
PDF
NetflixにおけるPresto/Spark活用事例 
PDF

PDF
20190314 PGStrom Arrow_Fdw 
PDF

PDF
SQL on Hadoop 比較検証 【2014月11日における検証レポート】 
PDF
Hive on Spark を活用した高速データ分析 - Hadoop / Spark Conference Japan 2016 What's hot

PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice 
PPTX
Hadoopトレーニング番外編 〜間違えられやすいHadoopの7つの仕様〜 
PDF
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ 
PDF
CDHの歴史とCDH5新機能概要 #at_tokuben 
PDF

PDF
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演) 
PDF
Is spark streaming based on reactive streams? 
PDF
各スペシャリストがお届け!データベース最新情報セミナー -PostgreSQL10- 
PDF
Hadoop Source Code Reading #17 
PDF

PDF
Hadoop ecosystem NTTDATA osc15tk 
PDF
SparkやBigQueryなどを用いた�モバイルゲーム分析環境 
PDF

PPTX

PDF
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会) 
PDF

PDF
DB Tech showcase Tokyo 2015 Works Applications 
PDF

PDF
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料) 
PDF
2017年5月26日 オープンソースデータベース比較セミナー「NoSQLとしても使えるMySQLとMySQL Cluster」 Similar to 今注目のSpark SQL、知っておきたいその性能とは 20151209 OSC Enterprise

PDF
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall 
PDF
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014) 
PDF
Configureing analytics system with apache spark and object storage service of... 
PPTX
The truth about SQL and Data Warehousing on Hadoop 
PPTX
SQL Server 使いのための Azure Synapse Analytics - Spark 入門 ![[db analytics showcase Sapporo 2017] B27:世界最速のAnalytic DBはHadoopの夢を見るか by 株式会...](https://cdn.slidesharecdn.com/ss_thumbnails/dbas20170701-170707082516-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db analytics showcase Sapporo 2017] B27:世界最速のAnalytic DBはHadoopの夢を見るか by 株式会... 
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料) 
PDF
DAIS2024参加報告 ~Spark中心にしらべてみた~ (JEDAI DAIS Recap 講演資料) 
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ... 
PDF
Osc2012 spring HBase Report 
PPTX
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006 ![[db tech showcase OSS 2017] A14: IoT時代のデータストア--躍進するNoSQL、拡張するRDB by OSSコンソーシア...](https://cdn.slidesharecdn.com/ss_thumbnails/20170616dbtechshowcaseossyoshida-170621081930-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db tech showcase OSS 2017] A14: IoT時代のデータストア--躍進するNoSQL、拡張するRDB by OSSコンソーシア... 
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門 - Open Source Conference2020 Online/Fukuoka... ![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ... 
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料) 
PDF
0151209 Oracle DDD OracleとHadoop連携の勘所 
PPTX
B34 Extremely Tuned Hadoop Cluster by Daisuke Hirama 
PDF
DLLAB Ignite Update Data Platform 
PDF
2019.03.19 Deep Dive into Spark SQL with Advanced Performance Tuning 
PDF
デジタル化への第一歩 「エンタープライズデータレイク構築事例のご紹介」 今注目のSpark SQL、知っておきたいその性能とは 20151209 OSC Enterprise
- 1.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
今注目のSpark SQL、
知っておきたいその性能とは
株式会社 日立ソリューションズ
オープンソース技術グループ
2015/12/9
倉又 裕輔
- 2.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
自己紹介
1
名前
倉又 裕輔 (くらまた ゆうすけ)
所属
・(株)日立ソリューションズ
研究開発部 オープンソース技術グループ
・OSSコンソーシアム DB部会
担当業務
・OSSのビッグデータ関連技術の
エンタープライズ利用に向けた調査
・調査で得られた技術情報の社内外への発信
- 3.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
OSSコンソーシアム DB部会の紹介
2
活動目的
データベース領域でのオープンソースのさらなる発展促進を図る
活動方針
・特定のプロダクトにとらわれず、第三者的な立場で
さまざまなデータベースの情報を収集し、
ユーザ・ベンダにフィードバックする機会を提供する
・データベースの垣根を越えたイベント等を開催する
参加対象
・オープンソースデータベースを活用したソリューション、
サービスを提供している企業、技術者の皆様
・上記のソリューション、サービスを活用している、
又は興味のあるユーザの皆様
参加企業
TIS株式会社
株式会社デジタル・ヒュージ・テクノロジー
特定非営利活動法人LPI-Japan
株式会社日立ソリューションズ
皆様のご参加を
お待ちしています!
http://www.osscons.jp/
- 4.
- 5.
- 6.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
1.1 ビッグデータ技術動向
5
ビッグデータ活用は年々拡大している
・ 2014年 国内ビッグデータソフトウェア市場規模は
110億9,100万円、前年比成長率39.3%
・ 大企業によるビッグデータ活用が活発化、
商用アプリケーションの採用が広がっている
・ IoTの普及やデジタルエコノミーの拡大により
市場規模は、2014年~2019年の年間平均成長率33.5%で拡大し、
2019年に470億6,100万円に達すると予測
引用 : 2015年8月12日 IDC Japan株式会社 プレスリリース
http://www.idcjapan.co.jp/Press/Current/20150812Apr.html
- 7.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
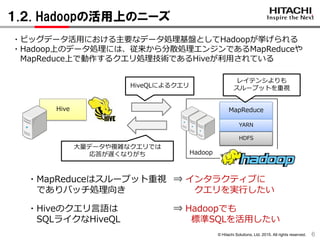
1.2. Hadoopの活用上のニーズ
6
MapReduceHive
Hadoop
レイテンシよりも
スループットを重視
・Hiveのクエリ言語は
SQLライクなHiveQL
・MapReduceはスループット重視
でありバッチ処理向き
・ビッグデータ活用における主要なデータ処理基盤としてHadoopが挙げられる
・Hadoop上のデータ処理には、従来から分散処理エンジンであるMapReduceや
MapReduce上で動作するクエリ処理技術であるHiveが利用されている
大量データや複雑なクエリでは
応答が遅くなりがち
YARN
HDFS
⇒ Hadoopでも
標準SQLを活用したい
⇒ インタラクティブに
クエリを実行したい
HiveQLによるクエリ
- 8.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
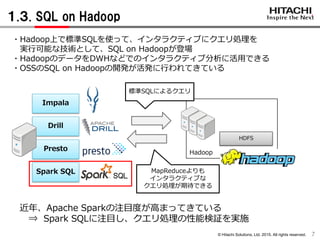
1.3. SQL on Hadoop
7
近年、Apache Sparkの注目度が高まってきている
⇒ Spark SQLに注目し、クエリ処理の性能検証を実施
・Hadoop上で標準SQLを使って、インタラクティブにクエリ処理を
実行可能な技術として、SQL on Hadoopが登場
・HadoopのデータをDWHなどでのインタラクティブ分析に活用できる
・OSSのSQL on Hadoopの開発が活発に行われてきている
HDFS
MapReduceよりも
インタラクティブな
クエリ処理が期待できる
Spark SQL
SQL
Hadoop
標準SQLによるクエリ
Impala
Drill
Presto
- 9.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
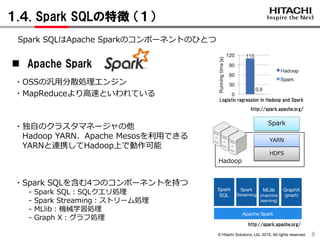
1.4. Spark SQLの特徴 (1)
8
Apache Spark
・Spark SQLを含む4つのコンポーネントを持つ
- Spark SQL:SQLクエリ処理
- Spark Streaming:ストリーム処理
- MLlib:機械学習処理
- Graph X:グラフ処理
Spark SQLはApache Sparkのコンポーネントのひとつ
・OSSの汎用分散処理エンジン
・MapReduceより高速といわれている
・独自のクラスタマネージャの他
Hadoop YARN、Apache Mesosを利用できる
YARNと連携してHadoop上で動作可能
Spark
Hadoop
YARN
HDFS
Logistic regression in Hadoop and Spark
http://spark.apache.org/
http://spark.apache.org/
- 10.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
1.5. Spark SQLの特徴 (2)
9
Spark SQL
Spark SQL
開発元 The Apache Software Foundation
ライセンス Apache License Version 2.0
開発言語 Scala
ユースケース 大規模データのインタラクティブ クエリ処理など
・Sparkの他コンポーネント(Spark StreamingやMllib)
と連携し、ストリーム処理や機械学習処理に
標準SQLを利用可能
・標準SQLを利用して、さまざまなデータにアクセス可能
- HDFS上のファイル(CSV, JSON, Parquet, ORC, Avroなど)
- Hiveテーブル
- RDBMS(JDBCを利用してアクセス)
http://spark.apache.org/sql/
・JDBC/ODBCを利用して、BIツールから利用可能
SQL
- 11.
- 12.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
2.1. 検証の目的と観点
11
Spark SQLの活用のためには、性能について把握が必要
検証の目的
Spark SQLはスケールアウトで性能向上するアーキテクチャ
Spark SQLは大規模データ処理を想定している
検証の観点
Spark SQLのクエリ処理速度の基礎性能を計測し
性能見積もりのための基礎データを得る
(1)ノード数の増加によるクエリ処理速度の向上
(2)処理データ量の増加によるクエリ処理速度の変化
- 13.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
2.2. 性能の評価方法
12
性能の比較対象
以下の2つのOSSを対象として、クエリ処理速度を比較
・Hive
MapReduce上で動作するクエリ処理ソフトウェア
・PostgreSQL
代表的なOSSのリレーショナルデータベース
性能の評価指標
以下の2つをクエリ処理速度の指標とする
・レイテンシ(=クエリ処理時間)
・スループット(=データ量(データ件数)÷レイテンシ)
Spark SQL・Hive・PostgreSQLで同一のクエリを実行し
レイテンシとスループットを比較する
- 14.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
YARN
HDFS
AWS
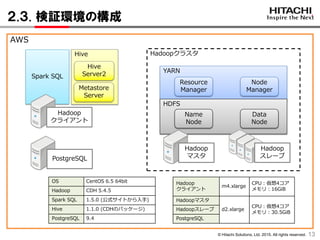
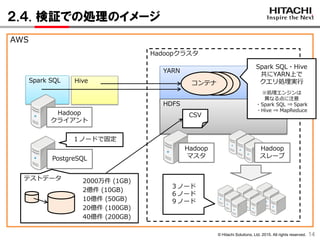
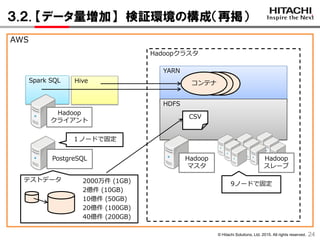
2.3. 検証環境の構成
1313
Hadoop
マスタPostgreSQL
Hadoop
クライアント
m4.xlarge
CPU:仮想4コア
メモリ:16GiB
Hadoopマスタ
d2.xlarge
CPU:仮想4コア
メモリ:30.5GiB
Hadoopスレーブ
PostgreSQL
Hadoopクラスタ
Name
Node
Resource
Manager
Node
Manager
Data
Node
Hadoop
スレーブ
Hive
Metastore
Server
Hive
Server2Spark SQL
Hadoop
クライアント
OS CentOS 6.5 64bit
Hadoop CDH 5.4.5
Spark SQL 1.5.0 (公式サイトから入手)
Hive 1.1.0 (CDHのパッケージ)
PostgreSQL 9.4
- 15.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
YARN
HDFS
AWS
2.4. 検証での処理のイメージ
1414
Hadoop
マスタPostgreSQL
Hadoopクラスタ
Hadoop
スレーブ
HiveSpark SQL
Hadoop
クライアント
CSV
テストデータ
コンテナ
3ノード
6ノード
9ノード
Spark SQL・Hive
共にYARN上で
クエリ処理実行
※処理エンジンは
異なる点に注意
・Spark SQL ⇒ Spark
・Hive ⇒ MapReduce
1ノードで固定
2000万件 (1GB)
2億件 (10GB)
10億件 (50GB)
20億件 (100GB)
40億件 (200GB)
- 16.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
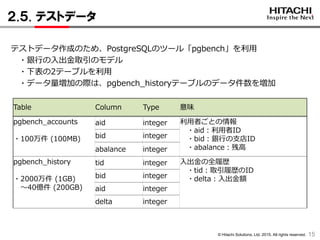
2.5. テストデータ
15
テストデータ作成のため、PostgreSQLのツール「pgbench」を利用
・銀行の入出金取引のモデル
・下表の2テーブルを利用
・データ量増加の際は、pgbench_historyテーブルのデータ件数を増加
Table Column Type 意味
pgbench_accounts
・100万件 (100MB)
aid integer 利用者ごとの情報
・aid:利用者ID
・bid:銀行の支店ID
・abalance:残高
bid integer
abalance integer
pgbench_history
・2000万件 (1GB)
~40億件 (200GB)
tid integer 入出金の全履歴
・tid:取引履歴のID
・delta:入出金額bid integer
aid integer
delta integer
- 17.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
2.6. 実行クエリ
16
クエリ処理速度の基礎性能値を計測するため
以下の3種類の基本的なクエリを実行
(1)SELECT:入出金履歴から利用者IDと入出金額を指定して検索
SELECT bid, aid, delta FROM pgbench_history
WHERE aid = 1 AND delta = 2898;
(2)SUM:入出金履歴から支店ごとの入出金額を集計
SELECT bid, SUM(delta) FROM pgbench_history GROUP BY bid;
(3)JOIN:入出金履歴の内、利用者が自身の口座に対して行った取引のみを
抽出し、その入出金額を支店ごとに集計
SELECT c.abid, SUM(c.adelta)
FROM (SELECT a.aid AS aaid, a.bid AS abid,
a.delta AS adelta, b.bid AS bbid FROM history AS a
INNER JOIN account AS b ON a.aid = b.aid) AS c
WHERE c.abid = c.bbid GROUP BY c.abid;
aidとdeltaの指定により
出力処理件数を削減し
不要な負荷を低減
- 18.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
2.7. 性能計測の手順
17
(1)キャッシュの削除
テストデータの読み込みキャッシュが効いていない状態での性能を計測
・Spark SQL・Hive・PostgreSQLの再起動
・OSのキャッシュ上のデータ削除
(2)クエリの実行
以下の各プロダクトのシェルからクエリを実行
・Spark SQL:spark-shell
・Hive:Beeline
・PostgreSQL:psql
※キャッシュ削除後の初回の計測値のみ採用し
複数回計測した平均値の算出などは実施していない
(3)レイテンシとスループットの計測
各プロダクトのログからクエリの処理時間=レイテンシを取得
得られた処理時間と処理データ量からスループットを算出
以下を1クエリの実行ごとに実施
- 19.
- 20.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
YARN
HDFS
AWS
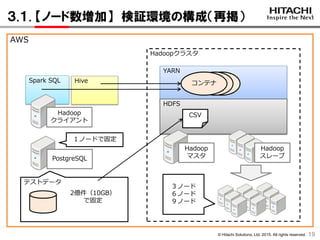
3.1. 【ノード数増加】 検証環境の構成(再掲)
1919
Hadoop
マスタPostgreSQL
Hadoopクラスタ
Hadoop
スレーブ
HiveSpark SQL
Hadoop
クライアント
CSV
コンテナ
3ノード
6ノード
9ノード
テストデータ
2億件(10GB)
で固定
1ノードで固定
- 21.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
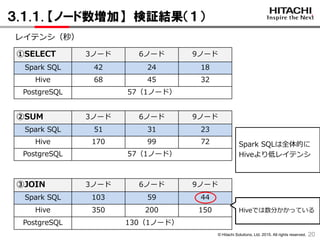
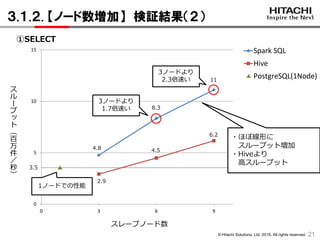
3.1.1. 【ノード数増加】 検証結果(1)
20
①SELECT 3ノード 6ノード 9ノード
Spark SQL 42 24 18
Hive 68 45 32
PostgreSQL 57(1ノード)
レイテンシ(秒)
②SUM 3ノード 6ノード 9ノード
Spark SQL 51 31 23
Hive 170 99 72
PostgreSQL 57(1ノード)
③JOIN 3ノード 6ノード 9ノード
Spark SQL 103 59 44
Hive 350 200 150
PostgreSQL 130(1ノード)
Hiveでは数分かかっている
Spark SQLは全体的に
Hiveより低レイテンシ
- 22.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
3.1.2. 【ノード数増加】 検証結果(2)
21
スレーブノード数
0
5
10
15
0 3 6 9
Spark SQL
Hive
PostgreSQL(1Node)
4.8 4.5
2.9
3ノードより
1.7倍速い
3ノードより
2.3倍速い 11
3.5
6.2
8.3
ス
ル
ー
プ
ッ
ト
(
百
万
件
/
秒
)
・ほぼ線形に
スループット増加
・Hiveより
高スループット
①SELECT
1ノードでの性能
- 23.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
0
5
10
0 3 6 9
Spark SQL
Hive
PostgreSQL(1Node)
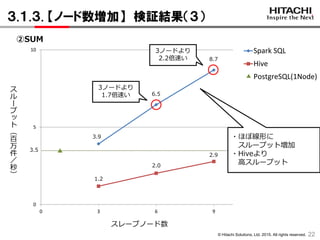
3.1.3. 【ノード数増加】 検証結果(3)
22
1.2
2.0
2.9
3ノードより
2.2倍速い
3ノードより
1.7倍速い
3.5
3.9
6.5
8.7
②SUM
ス
ル
ー
プ
ッ
ト
(
百
万
件
/
秒
)
スレーブノード数
・ほぼ線形に
スループット増加
・Hiveより
高スループット
- 24.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
0
5
10
0 3 6 9
Spark SQL
Hive
PostgreSQL(1Node)
3.1.4. 【ノード数増加】 検証結果(4)
23
1.9
1.0
1.4
3ノードより
2.4倍速い
3ノードより
1.8倍速い
0.58
3.4
4.5
1.5
・ほぼ線形に
スループット増加
・Hiveより
高スループット
③JOIN
ス
ル
ー
プ
ッ
ト
(
百
万
件
/
秒
)
スレーブノード数
- 25.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
YARN
HDFS
AWS
3.2. 【データ量増加】 検証環境の構成(再掲)
2424
Hadoop
マスタ
PostgreSQL
Hadoopクラスタ
HiveSpark SQL
Hadoop
クライアント
CSV
コンテナ
テストデータ
1ノードで固定
9ノードで固定
Hadoop
スレーブ
2000万件 (1GB)
2億件 (10GB)
10億件 (50GB)
20億件 (100GB)
40億件 (200GB)
- 26.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
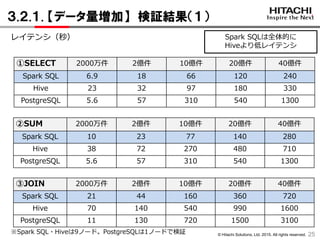
3.2.1. 【データ量増加】 検証結果(1)
25
①SELECT 2000万件 2億件 10億件 20億件 40億件
Spark SQL 6.9 18 66 120 240
Hive 23 32 97 180 330
PostgreSQL 5.6 57 310 540 1300
レイテンシ(秒)
②SUM 2000万件 2億件 10億件 20億件 40億件
Spark SQL 10 23 77 140 280
Hive 38 72 270 480 710
PostgreSQL 5.6 57 310 540 1300
③JOIN 2000万件 2億件 10億件 20億件 40億件
Spark SQL 21 44 160 360 720
Hive 70 140 540 990 1600
PostgreSQL 11 130 720 1500 3100
Spark SQLは全体的に
Hiveより低レイテンシ
※Spark SQL・Hiveは9ノード。PostgreSQLは1ノードで検証
- 27.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
0
5
10
15
20
0 1000 2000 3000 4000
Spark SQL
Hive
PostgreSQL(1Node)
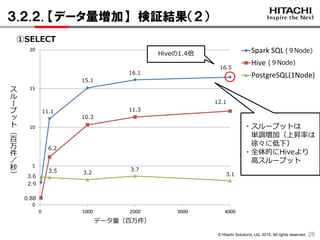
3.2.2. 【データ量増加】 検証結果(2)
26
2.9
11.1
16.1
0.88
6.2
3.5 3.7
Hiveの1.4倍
3.6
16.5
3.2 3.1
15.1
10.3
11.3
12.1
データ量(百万件)
・スループットは
単調増加(上昇率は
徐々に低下)
・全体的にHiveより
高スループット
ス
ル
ー
プ
ッ
ト
(
百
万
件
/
秒
)
①SELECT
(9Node)
(9Node)
- 28.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
0
5
10
15
20
0 1000 2000 3000 4000
Spark SQL
Hive
PostgreSQL(1Node)
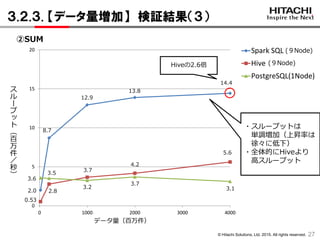
3.2.3. 【データ量増加】 検証結果(3)
27
2.0
8.7
13.8
3.6
3.5
3.7
0.53
2.8
4.2
Hiveの2.6倍
12.9
14.4
5.6
3.2
3.7
3.1
データ量(百万件)
・スループットは
単調増加(上昇率は
徐々に低下)
・全体的にHiveより
高スループット
②SUM
ス
ル
ー
プ
ッ
ト
(
百
万
件
/
秒
)
(9Node)
(9Node)
- 29.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
0
5
10
0 1000 2000 3000 4000
Spark SQL
Hive
PostgreSQL(1Node)
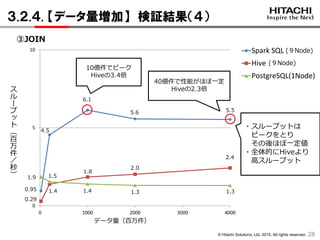
3.2.4. 【データ量増加】 検証結果(4)
28
0.95
4.5
5.6
1.9 1.5
1.3
0.29
1.4
2.0
40億件で性能がほぼ一定
Hiveの2.3倍
6.1
5.5
2.4
1.8
1.4 1.3
10億件でピーク
Hiveの3.4倍
データ量(百万件)
・スループットは
ピークをとり
その後ほぼ一定値
・全体的にHiveより
高スループット
③JOIN
ス
ル
ー
プ
ッ
ト
(
百
万
件
/
秒
)
(9Node)
(9Node)
- 30.
- 31.
© Hitachi Solutions,Ltd. 2015. All rights reserved.
4. まとめ
30
■ Spark SQLはHiveと比較して、大量データを低レイテンシに
クエリ処理できることがわかった
Spark SQLの活用により、インタラクティブに分析可能な
データ規模を拡大することが可能である
■ Spark SQLはノード増加によりほぼ線形に性能向上することがわかった
だだし、メモリサイズを超える規模のデータに対しては
性能が低下するため、想定するデータ量に応じた
メモリサイズ・ノード数の検討が必須である
- 32.