Downloaded 47 times


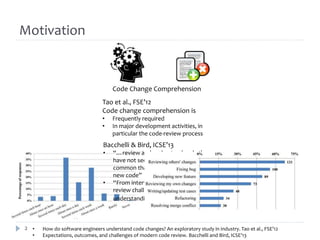


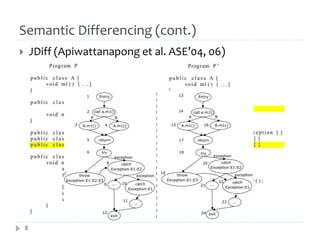



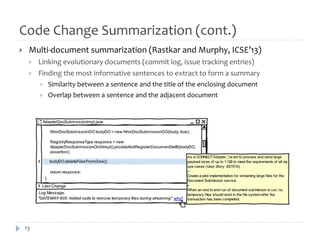



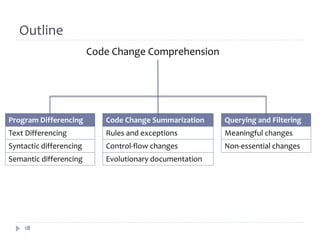








The document discusses research on assisting software engineers in comprehending source code changes. It outlines techniques for differencing code at the text, syntactic and semantic levels. It also covers summarizing code changes, explaining changes through rules and control flow analysis, and leveraging related documentation. Future work opportunities include detecting work-item specific changes, decomposing and aggregating changes, and explaining changes through differential execution of co-changed test cases.
























































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

