Download to read offline






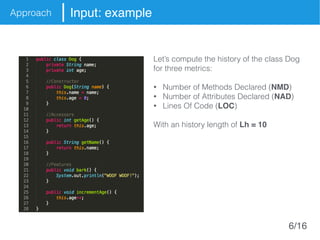
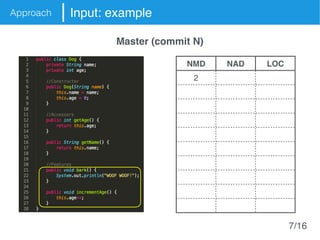
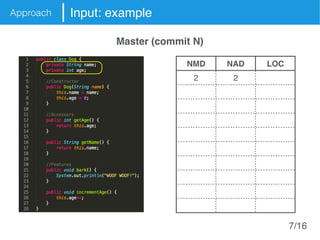
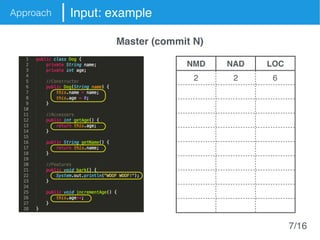
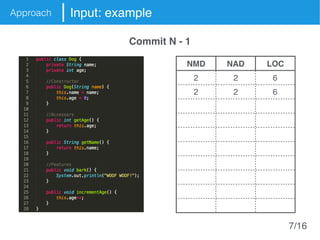
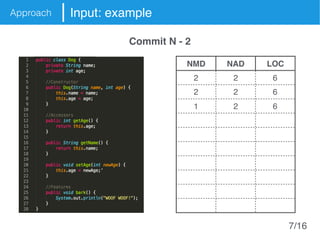

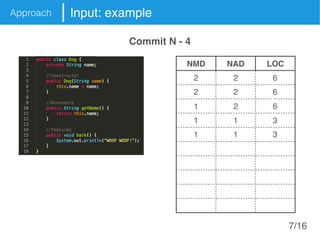

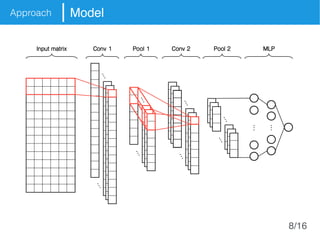


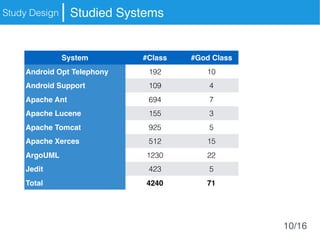
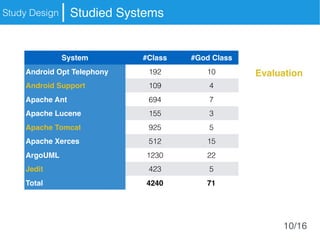
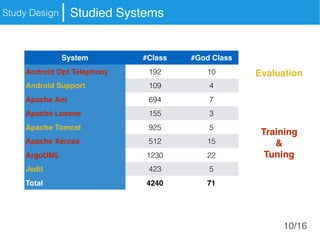

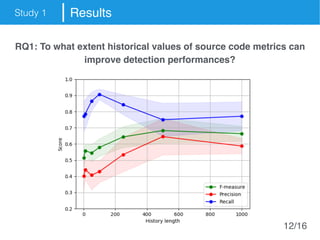



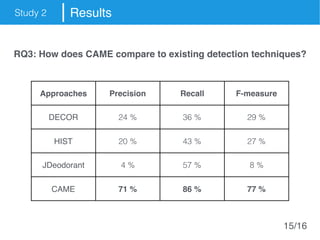


The document presents an approach called Convolutional Analysis of code Metrics Evolution (CAME) that uses a convolutional neural network to detect anti-patterns by analyzing the historical evolution of source code metrics at the class level. An evaluation on 7 open-source systems shows that considering longer histories of metrics improves detection performance and that CAME outperforms other machine learning and anti-pattern detection techniques in terms of precision, recall, and F-measure.



















































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)


