Download as PDF, PPTX







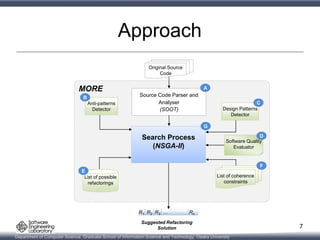






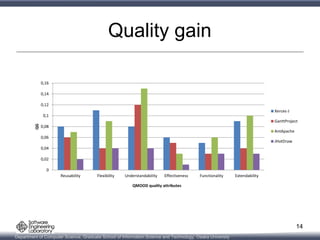





This document presents a multi-objective search-based software engineering approach to recommend refactorings that introduce design patterns, fix anti-patterns, and improve software quality attributes. The approach uses NSGA-II genetic algorithm to evolve refactoring solutions. An empirical evaluation on 4 open-source Java systems shows the approach outperforms existing techniques in fixing anti-patterns and introducing design patterns while improving quality. Future work includes expanding the types of patterns addressed and developing interactive refactoring support.



































































