Download as PDF, PPTX










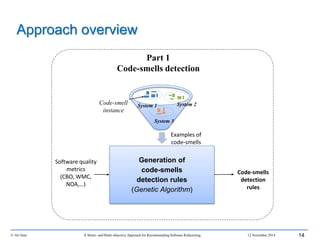
![© Ali Ouni A Mono- and Multi-objective Approach for Recommending Software Refactoring 12 November 2014
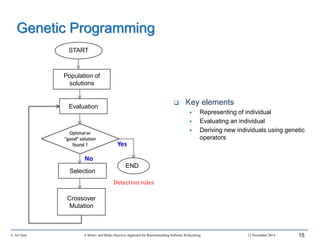
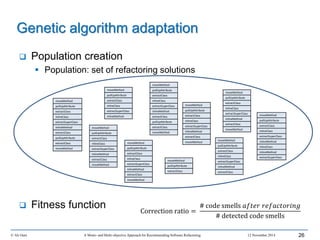
GP adaptation
WMC
LCOM
NOM
CBO
[1..500]
[1..100]
Quality metrics
NOA
Solution representation
16
1 : Blob
2 : Spaghetti code
3 : Functional decomposition
Base of examples
Code-smell
instance
3 : If (NOA≥4) AND (WMC<3) Then Functional decomposition
2 : If (CBO≥ 151) Then Spaghetti code
1 : If (LOCCLASS≥1500) AND (NOM≥20) OR (WMC>20) Then Blob
R1: Blob
R2: SC
R3: FD
OR
OR AND
AND
LOCClASS
≥ 1500
NOM ≥ 20
CBO ≥ 151
NOA ≥ 4
CBO<3
MWC ≥
20
N6
N1
N2
N3
N4
N5 N7
N8
N10
N9
Tree representation
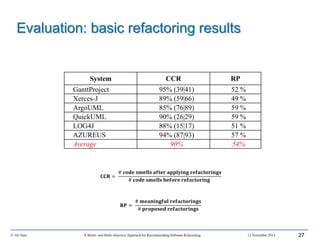
Fitness function
𝑅𝑒𝑐𝑎𝑙𝑙 =
𝑡𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒𝑠
𝑡𝑜𝑡𝑎𝑙 𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑐𝑜𝑑𝑒 𝑠𝑚𝑒𝑙𝑙𝑠
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =
𝑡𝑟𝑢𝑒 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒𝑠
𝑛𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑑𝑒𝑡𝑒𝑐𝑡𝑒𝑑 𝑐𝑜𝑑𝑒 𝑠𝑚𝑒𝑙𝑙𝑠](https://image.slidesharecdn.com/phddefensealiounif-150422015536-conversion-gate02/85/A-Mono-and-Multi-objective-Approach-for-Recommending-Software-Refactoring-16-320.jpg)
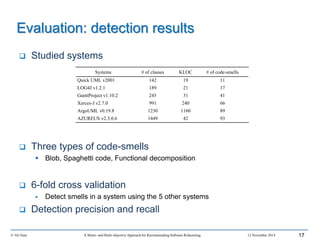
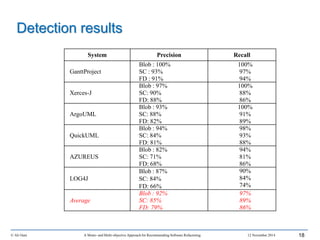
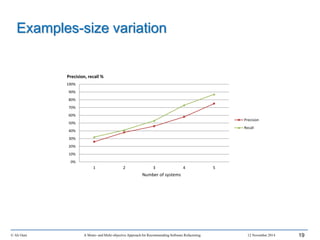
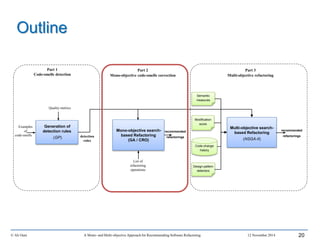


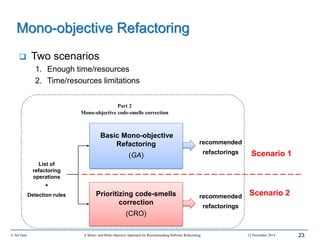
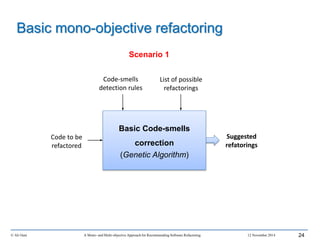

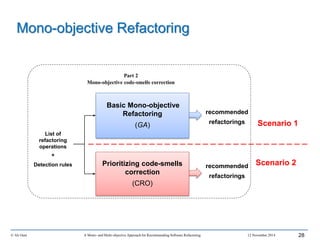
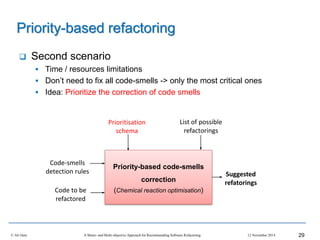


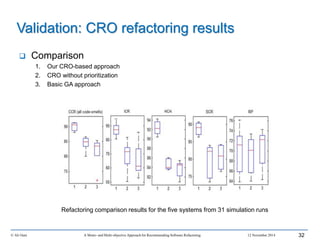

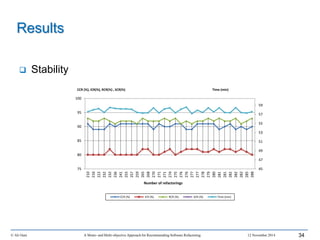
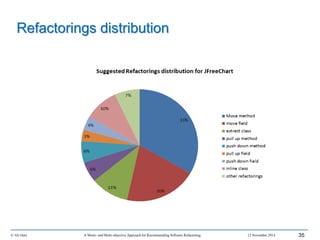

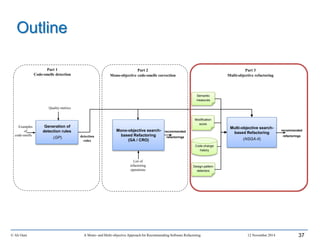
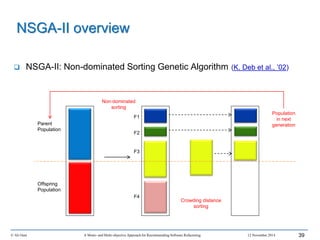
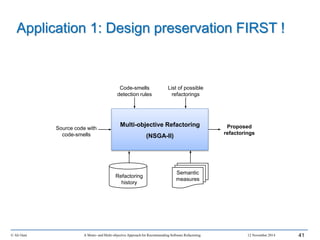



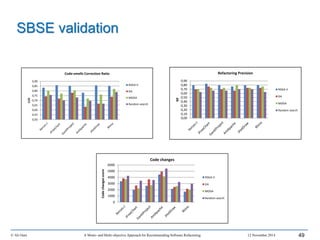
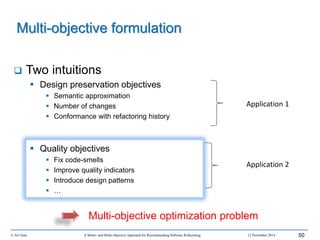

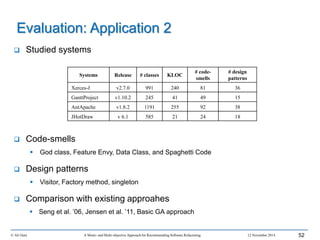
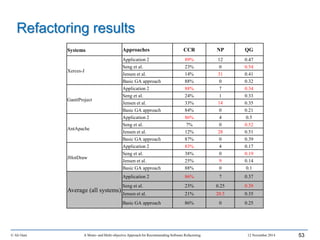
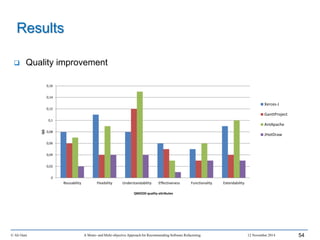
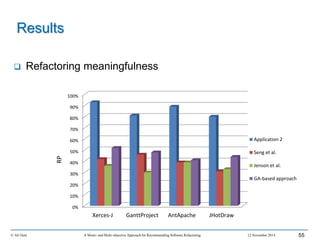








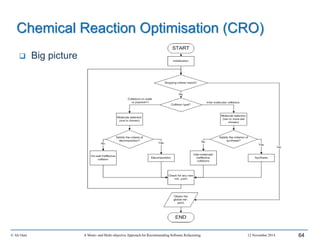


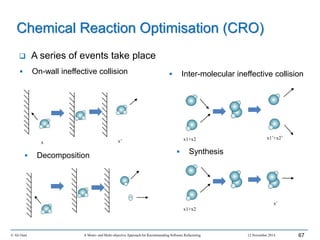

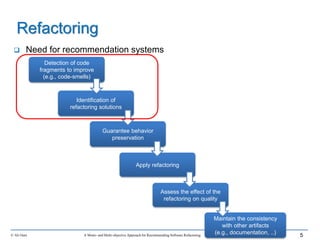
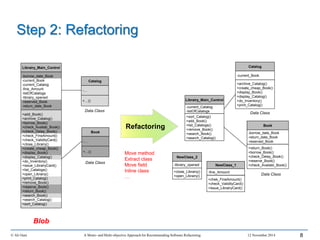
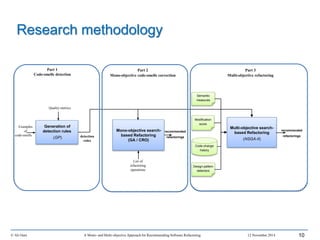
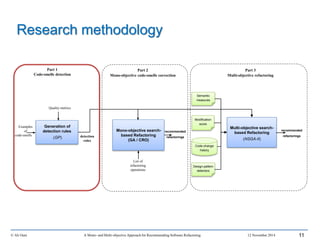
This document outlines Ali Ouni's Ph.D. defense presentation on recommending software refactoring using mono-objective and multi-objective approaches. The presentation includes the following key points: 1. It provides context on the need for automated software refactoring recommendation systems to address challenges in manually refactoring code. 2. It describes Ouni's research methodology which involves detecting code smells, generating refactoring recommendations using mono-objective and multi-objective search-based techniques, and evaluating the approaches. 3. It covers code smell detection including generating detection rules using genetic programming from code smell examples, and evaluating the detection approach on several systems. 4. It outlines the presentation including discussing



































































