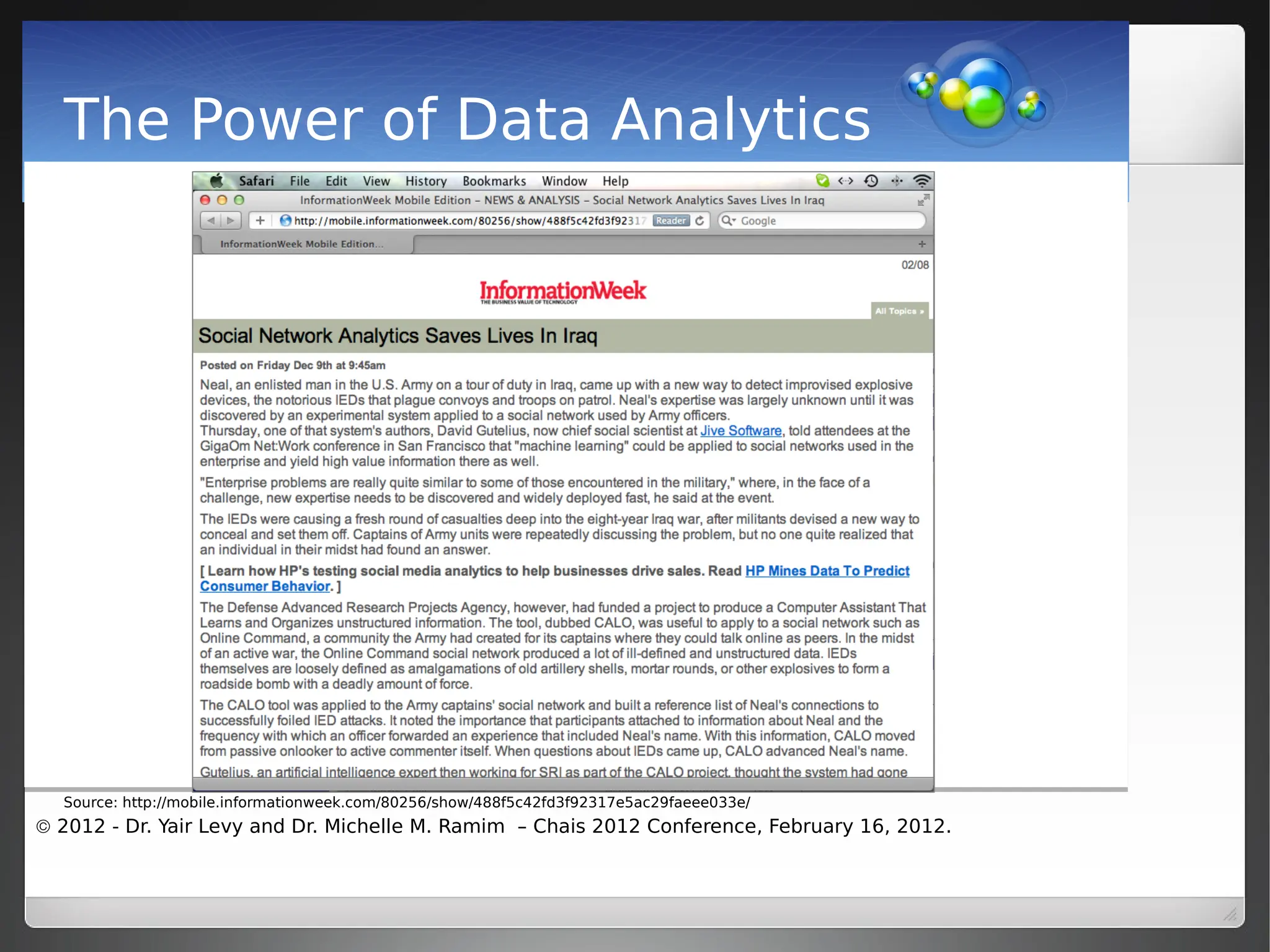
Data analytics involves collecting and analyzing raw data from various sources to uncover patterns and relationships, enabling quicker decision-making and policy changes. It differentiates from statistical analysis by using data mining techniques to visualize and identify new trends without prior hypotheses. The document also discusses the origins of data (offline vs. online), the importance of public and private data in social media analytics, and methods for data gathering such as APIs and web scraping.