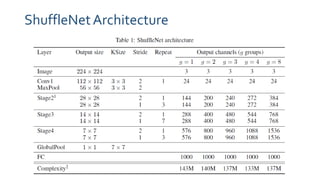
ShuffleNet is an efficient convolutional neural network designed for mobile devices, employing techniques such as depthwise separable convolutions, grouped convolutions, and channel shuffling to optimize performance. Experimental results show that ShuffleNet outperforms existing architectures like MobileNet and achieves higher accuracy with lower computation complexity. The architecture allows customization of network complexity through a scale factor, leading to significant performance improvements in smaller models.