Download as PDF, PPTX









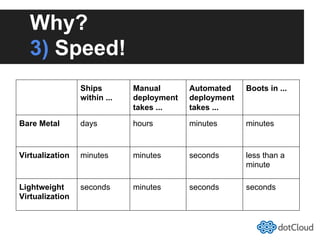











































This document provides an overview of lightweight virtualization using Linux containers (LXC) and the AUFS filesystem. It discusses how LXC containers leverage namespaces and cgroups to provide isolation between processes and control over resource usage. Namespaces partition kernel structures like processes, networking, filesystems, and users to create isolated environments. Cgroups limit, account, and isolate resource usage like CPU and memory for groups of processes. AUFS allows using a single filesystem image with copy-on-write capabilities. The document also summarizes how to set up and use LXC containers and AUFS.























































































