Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
A俺
Uploaded by
antibayesian 俺がS式だ
10,116 views
あんちべのすべらない話~俺のツイートがこんなにウケないはずがない~
Rを用いたtwitterテキストマイニング
Technology
◦
Business
◦
Read more
23
Save
Share
Embed
Embed presentation
Download
Downloaded 73 times
1
/ 20
2
/ 20
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
8
/ 20
9
/ 20
10
/ 20
11
/ 20
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
20
/ 20
More Related Content
PDF
Sakusaku svm
by
antibayesian 俺がS式だ
PDF
言語処理学会へ遊びに行ったよ
by
antibayesian 俺がS式だ
PDF
全文検索入門
by
antibayesian 俺がS式だ
PDF
協調フィルタリング with Mahout
by
Katsuhiro Takata
PDF
RでTwitterテキストマイニング
by
Yudai Shinbo
PDF
RではじめるTwitter解析
by
Takeshi Arabiki
PDF
チームラボ忘年会
by
antibayesian 俺がS式だ
PDF
Kuzu
by
Atsushi Hayakawa
Sakusaku svm
by
antibayesian 俺がS式だ
言語処理学会へ遊びに行ったよ
by
antibayesian 俺がS式だ
全文検索入門
by
antibayesian 俺がS式だ
協調フィルタリング with Mahout
by
Katsuhiro Takata
RでTwitterテキストマイニング
by
Yudai Shinbo
RではじめるTwitter解析
by
Takeshi Arabiki
チームラボ忘年会
by
antibayesian 俺がS式だ
Kuzu
by
Atsushi Hayakawa
Similar to あんちべのすべらない話~俺のツイートがこんなにウケないはずがない~
ZIP
problemsolved.key
by
Yutaro Ikeda
PDF
Uec.R#3 YjdnJlpを使ってみた
by
Atsushi Hayakawa
PDF
EMNLP 2011 reading
by
正志 坪坂
PPTX
RでKaggleの登竜門に挑戦
by
幹雄 小川
PDF
Bnlearn tokyo r29th
by
Kentaro Taguchi
PDF
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
PDF
clustering of user
by
Atsushi Hayakawa
PDF
R による文書分類入門
by
Takeshi Arabiki
PDF
Hadoopエンタープライズソリューションセミナー2012: Hadoop&RabbitMQを利用したTwitter全量リアルタイム解析
by
Kenji Hara
problemsolved.key
by
Yutaro Ikeda
Uec.R#3 YjdnJlpを使ってみた
by
Atsushi Hayakawa
EMNLP 2011 reading
by
正志 坪坂
RでKaggleの登竜門に挑戦
by
幹雄 小川
Bnlearn tokyo r29th
by
Kentaro Taguchi
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました―
by
Hisao Soyama
clustering of user
by
Atsushi Hayakawa
R による文書分類入門
by
Takeshi Arabiki
Hadoopエンタープライズソリューションセミナー2012: Hadoop&RabbitMQを利用したTwitter全量リアルタイム解析
by
Kenji Hara
More from antibayesian 俺がS式だ
PDF
企業における統計学入門
by
antibayesian 俺がS式だ
PDF
SPSSで簡単テキストマイニング
by
antibayesian 俺がS式だ
PDF
ガチャとは心の所作
by
antibayesian 俺がS式だ
PDF
テキストマイニングのイメージと実際
by
antibayesian 俺がS式だ
PDF
さくさくテキストマイニング入門セッション
by
antibayesian 俺がS式だ
PDF
神の言語による自然言語処理
by
antibayesian 俺がS式だ
PDF
Pythonで簡単ネットワーク分析
by
antibayesian 俺がS式だ
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
by
antibayesian 俺がS式だ
企業における統計学入門
by
antibayesian 俺がS式だ
SPSSで簡単テキストマイニング
by
antibayesian 俺がS式だ
ガチャとは心の所作
by
antibayesian 俺がS式だ
テキストマイニングのイメージと実際
by
antibayesian 俺がS式だ
さくさくテキストマイニング入門セッション
by
antibayesian 俺がS式だ
神の言語による自然言語処理
by
antibayesian 俺がS式だ
Pythonで簡単ネットワーク分析
by
antibayesian 俺がS式だ
第三回さくさくテキストマイニング勉強会 入門セッション
by
antibayesian 俺がS式だ
あんちべのすべらない話~俺のツイートがこんなにウケないはずがない~
1.
あんちべの すべらない話 ~俺のツイートがこんなにウケないはずがない~
2.
目的
3.
twitter 渾身のネタが スルーされたり 何気ない呟きが めっちゃウケたり
4.
滑ったときの 恥ずかしさ マジパネェ
5.
tweetする前に ウケルかどうか 予測できれば!
6.
それ、Rなら 簡単ですよ!
7.
発表の目的 Rで自分のtweetが ウケるかどうか 予測をしよう!
8.
自己紹介 ●
ID:AntiBayesian ● あんちべ!とお呼び下さい ● 専門:テキストマイニング、自然言語処理 ● 職業:某ATMが○○な銀行で金融工学研究員とか いう胡散臭い素敵なことしてる ● 自然言語処理職大絶賛募集中!!!! ● math.empress@gmail.com
9.
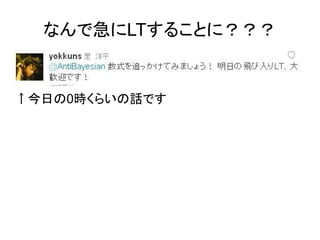
なんで急にLTすることに??? ↑今日の0時くらいの話です
10.
分析手順 1.訓練データ(正例、負例)を用意する 2.訓練データから予測モデルを立てる 3.自分のtweetを予測モデルに放り込んで判定
11.
訓練データを集めよう ●
正例:favstarから人気tweetを取得 ● 負例:twitter Streaming APIから適当にサンプリン グ ● 6月中のtweetを各々約1500件ずつチョイス ● 正例にはfav、負例にはnonタグを付ける ※Tweetを取得するツール作ったよ! http://d.hatena.ne.jp/AntiBayesian/20110702
13.
さくさくツイートマイニング こんな感じ→
14.
訓練データの加工
ttmの紹介 ● TinyTextMiner ● テキストを形態素解析に掛け、さらに分析ツールに 投げやすいよう整形してくれるフリーソフト ● ここからDL http://mtmr.jp/ttm/ ※MeCabもインストールしてね
15.
加工済みデータ ●
1行目が各単語。2行目以降は、各文章から表頭 の単語が何回出現したか ● 右端のTAG列がクラス。fav=正例、non=負 例、test=検証するtweet。 ● 要するに、testテキストがfav、nonどちらに分類さ れるか知りたい
16.
予測モデルを立てよう ●
RandomForestを使おう! ● 精度高いし汚いデータにも強い!Googleも利用! ● 詳細は下記ブログを参考に http://d.hatena.ne.jp/hamadakoichi/20110130/
17.
Rのコード twit <- read.csv(file="twit.csv") library(randomForest) train.data
<- twit[1:2877,]#訓練データが2877ある test.data <- twit[2878:2911,]#テストデータは33 rf.model <- randomForest(TAG~., data=train.data, na.a="na.omit", ntree=10)
18.
精度はどう??? rf.predict <- predict(rf.model,
train.data) (result <- table(train.data$TAG, rf.predict)) ● 緑色のセル=正しく分類 ● 行:予測 ● 列:実際 2*result[2,2] / (2*result[2,2]+result[1,2]+result[2,1]) ● F値:0.9019064 ※訓練データで高精度は当たり前。ただの目安
19.
学習結果 rf.predict <- predict(rf.model,
test.data) ● 2878行目のデータはfav、2879行目はnonと予測 ● favと予測されたtweetはウケルのでは???
20.
まとめ ●
人気tweetを収集し、人気tweetを判別するモデル を作る ● 自分のtweetをモデルで評価して、ウケル内容だ けtweetする ● これで広瀬香美や孫正義を超える人気ついっ たったーになれる!
Download















![Rのコード
twit <- read.csv(file="twit.csv")
library(randomForest)
train.data <- twit[1:2877,]#訓練データが2877ある
test.data <- twit[2878:2911,]#テストデータは33
rf.model <- randomForest(TAG~., data=train.data,
na.a="na.omit", ntree=10)](https://image.slidesharecdn.com/random-110702031140-phpapp01/85/slide-17-320.jpg)
![精度はどう???
rf.predict <- predict(rf.model, train.data)
(result <- table(train.data$TAG, rf.predict))
● 緑色のセル=正しく分類
● 行:予測
● 列:実際
2*result[2,2] / (2*result[2,2]+result[1,2]+result[2,1])
● F値:0.9019064
※訓練データで高精度は当たり前。ただの目安](https://image.slidesharecdn.com/random-110702031140-phpapp01/85/slide-18-320.jpg)


























