More Related Content

PDF

PDF
第2.1回 ツイッターAPI勉強会 @ts_3156 発表資料 
PDF
Pythonによるソーシャルデータ分析―わたしはこうやって修士号を取得しました― 
PDF

PDF
WWW2018 論文読み会 Web Search and Mining 
PDF

PDF
🍻(Beer Mug)の読み方を考える(mecab-ipadic-NEologdのUnicode 絵文字対応) 
PPTX
データ分析スクリプトのツール化入門 - PyConJP 2016 What's hot

PDF
形態素解析器 MeCab の新語・固有表現辞書 mecab-ipadic-NEologd のご紹介 
PPTX
Python による 「スクレイピング & 自然言語処理」入門 
PDF
Big Data入門に見せかけたFluentd入門 
PDF
Web エンジニアが postgre sql を選ぶ 3 つの理由 
PDF
Rとpythonとjuliaで機械学習レベル4を目指す 
PDF

PDF
Japan.r ver1.2 20171202_ota 
PDF

PDF

PDF

PDF
mecab-ipadic-NEologd の効果的な使い方 
PDF
_gaTracker 第4回ミーティング『not providedをどうとらえるか』 いちしま泰樹 
PDF
Viewers also liked

PDF
Credential twittorebiew v1.3 
PPTX
第1回茶ッカソン in Tokyo プレゼンシート「チームNifty」 
PDF

PDF

PDF

PDF
Credential social media_live_v1_3 
PDF

PDF
第1回茶ッカソン in Tokyo プレゼンシート「FULLER」 
PDF

PDF

PDF

PDF

PDF
Python東海Vol.5 IPythonをマスターしよう 
PDF
Similar to 全文検索入門

PDF
オープンソースソフトウェア検索サーバ Solr入門 
PDF
オープンソースソフトウェア検索サーバ Solr入門 
PPT
Apache Solrで実現する共創のエコ システム ‒検索、クロール、自然言語処理‒ 
PDF

PDF

PDF
AWS Black Belt Tech Webinar 2016 〜 Amazon CloudSearch & Amazon Elasticsearch ... ![[DI08] その情報うまく取り出せていますか? ~ 意外と簡単、Azure Search で短時間で検索精度と利便性を向上させるための方法](https://cdn.slidesharecdn.com/ss_thumbnails/di08-170605024559-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DI08] その情報うまく取り出せていますか? ~ 意外と簡単、Azure Search で短時間で検索精度と利便性を向上させるための方法 
PDF
はじめての検索エンジン&Solr 第13回Solr勉強会 
PPTX

PDF
self made Fulltext search first_step 
PDF
Elasticsearch入門 pyfes 201207 
PPTX

PDF
Search on AWS - IVS CTO Night and Day 2016 Spring 
PDF
Lucene gosenの紹介 solr勉強会第7回 
PPTX

PPTX

PDF

PDF

PPTX

PDF
全文検索入門
- 1.
- 2.
- 4.
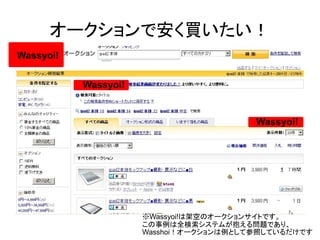
オークションで安く買いたい!
Wassyoi!
Wassyoi!
Wassyoi!
※Wassyoi!は架空のオークションサイトです。
この事例は全検索システムが抱える問題であり、
Wasshoi!オークションは例として参照しているだけです
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
自己紹介
● ID:AntiBayesian
● あんちべ!
● 専門:テキストマイニング、自然言語処理
● 職業:カジュアルにATM停止させちゃう銀行で金融
工学研究員とかいう胡散臭い素敵なことしてた記憶が
● math.empress@gmail.com
- 13.
なぜ検索が必要か
● 検索はGoogleやMSなど、超大企業だけのもの?
● 先程のケースのように、ショッピングサイトでも重要
● モノが溢れ、ニーズが多様化する時代。良いものを
作るだけではなく、簡単に商品を見つけられるよう
にしないと、お客様には届かない
● 共有情報を有効活用するにも検索が有効
● 社内事務手続集DB、肝心な情報が見つからない!
● SEO対策するにも検索エンジンの中身を知らねば
- 14.
Web検索エンジンの歴史
● 熾烈な検索エンジン戦争
● 2000年以前 AltaVista:最大ページ数を誇る
●
どれだけ多くのページを検索できるか
● 2000年以後 Google:ページランク
● どれだけ上手くランキングできているか
● 「より多くのデータ」から「よりデータを便利に」へ
- 15.
時は情報大航海時代
● どれだけ沢山のデータを持っているかではなく、
どれだけユーザーが求める情報を抽出出来るか
● データは活用出来る状態でないと何の意味も無い
● 検索とは、大規模データを有効活用するための
必要不可欠な要素
- 16.
アジェンダ
● 検索概論編
●
検索方式
● 転置インデックス
● 検索モデル
●
検索エンジンの評価
●
索引語のスコアリング
● 検索実践編
● Lucene/Solr入門
● tweet検索
- 17.
検索方式
● 順次検索:文書集合の先頭から、クエリが含まれて
いる文書を検索し、文字列が一致しているものを見
つける(grep、Ctrl + F検索をイメージ)
● 簡単にシステム構築できる
● 文書量多いと遅くなる
● 索引検索:事前に文書から作成した索引を用いる
●
文書量多くても高速(分厚い本でも、索引があれば目的
のページがすぐ引ける)
●
索引を作る手間がかかる
● 現在の主流
- 18.
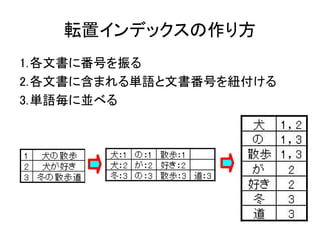
転置インデックス
● 索引方式の主流。大抵の全文検索エンジンが対応
● 各索引語が文書に出現する位置を格納した表構
造の索引
● 元の文書の2,3倍のサイズになるため、実装する
場合は高度な圧縮技法が必要
● 索引の頻繁な更新に弱い
- 19.
- 20.
検索モデル:ブーリアンモデル
● クエリと転置インデックスとの論理演算で検索
● 例:クエリが「犬」
● 番号1,2を返す
●
例:クエリ が 「散歩道」
● クエリを単語に分割{散歩 & 道}
● {散歩 & 道}を満たす番号3を返す
- 21.
検索エンジンの評価
適合率と再現率
● 適合率(precision)-精度。検索結果にどれだけ求
める情報が含まれているか
● 検索結果の適合文書数/検索された文書の数
● 検索結果100件の内、求めるデータが70件→ 70%
● 再現率(recall)-網羅性。もれなく抽出できるか
● 検索結果の適合文書数/全文書中の適合文書数
● 求めるデータが検索結果に100件、文書集合に200件
→ 50%
- 22.
検索エンジンの評価 F値
● 適合率と再現率にはトレードオフの関係がある
● 極端な話、全文書を検索結果として出せば、再現
率は100%になり、適合率は非常に低くなる
● F値で両方のバランスを考慮する
● 調和平均F = 2 / (1/再現率 + 1/適合率)が大きい
程良い
(参考)「F値に調和平均を使う理由」
http://d.hatena.ne.jp/a_bicky/20101120/129026
6655
- 23.
索引語の重み付け TF-IDF
● クエリが「ボール」では、サッカーと野球のどちらが
求められているのか解らない。「キーパー」ならサッ
カーと判断出来る→ボールよりキーパーの方が、
文書の特定にとって重要
●
各索引語の重要度を測り、重み付けしよう
● 局所的重み(TF:Term Frequency):頻度。再現率
向上に利く
● 大域的重み(IDF:inverse document frequency):
特定文書に集中して出現する索引語を重くする。
文書による索引語の偏りを表す。適合率向上に利
く。IDF = log全文書数 / 索引語を含む文書数
- 24.
Lucene/Solr入門
● Lucene:オープンソースの全文検索エンジン
● Solr:Luceneを利用した検索アプリケーション
● Wikipedia、twitterなど利用実績多数
● 転置インデックス方式
● Java製。RubyやPHPなどでの利用も可能
● 検索結果はxmlやjsonなど様々な形式で出力可能
● 今回はtweetを登録・検索してみます
- 25.
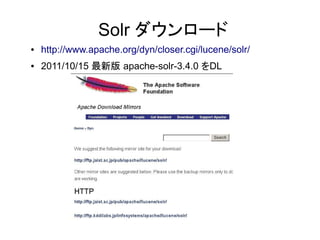
Solr ダウンロード
● http://www.apache.org/dyn/closer.cgi/lucene/solr/
● 2011/10/15 最新版 apache-solr-3.4.0 をDL
- 26.
Schema設定
● インストールしたフォルダapache-solr-
3.4.0examplesolrconf の schema.xml
●
最低限必要な設定
● types - データの型定義
● fields – データのプロパティ定義
● schema.xmlのtypes, fieldsブロックに次ページの定義を
任意の場所に挿入する
- 27.
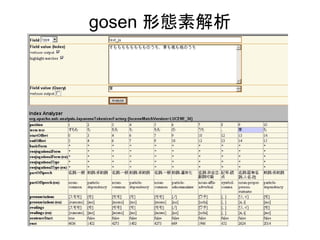
Schema - <types>
<types>
<fieldTypename="text_ja" class="solr.TextField" positionIncrementGap="100"
autoGeneratePhraseQueries="false">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory"/>
</analyzer>
</fieldType>
</types>
- 28.
Schema - <fields>
<fields>
<field name="screen_name" type="text_ja" indexed="true" stored="true"/>
<field name="tweet" type="text_ja" indexed="true" stored="true"/>
<field name="tweetDate" type="pdate" indexed="true" stored="true"/>
</fields>
- 29.
Solr 起動
● >cd example
● >java -jar start.jar
● http://localhost:8983/solr/admin/
- 30.
gosen インストール
● Lucene/Solr向け形態素解析エンジン
● http://code.google.com/p/lucene-gosen/downloads/list
● インストールしたフォルダapache-solr-
3.4.0exampleexamplesolrlibにDLしたjarを置く
● http://localhost:8983/solr/admin/analysis.jspで形態素解析を試す
- 31.
- 32.
登録用tweet形式
id,screen_name,tweet,tweetDate
1,testID,こんにちは!テスト内容だよ!,2011-10-15T15:00:00Z
2,AntiBayesian,まだスライド出来てない、やばい、眠い,2011-10-
15T4:32:14Z
3,gepuro,眠いです眠いです、もう無理です,2011-10-15T3:18:42Z
4,toilet_lunch,シャワー浴びて寝るか~,2011-10-15T5:11:22Z
- 33.
tweet登録
● >cd exampledocs
● > java
-Durl=http://localhost:8983/solr/update/csv -jar
post.jar tweet.csv
- 34.
SakuSakuTweetMining
● Streaming APIからtweetを自動収集するツール
● http://d.hatena.ne.jp/AntiBayesian/20110702
● screen_name, tweet, dateを取得。適宜加工要
- 35.
Solr 検索
● http://localhost:8983/solr/admin/form.jsp
- 36.
- 37.
まとめ
● 検索は大規模データ時代には必須
● 全文検索、転置インデックス方式が主流
● Lucene/Solrは利用実績豊富な検索エンジン
● 重要なことは、検索エンジンを利用してどのように
業務改善、売り上げ向上などに繋げられるか考え
ること
- 38.
参考文献
(難易度順)
● 検索エンジンはなぜ見つけるのか
● Apache Solr入門
● 情報検索アルゴリズム
● 情報検索と言語処理
● Introduction to Information Retrieval
● Information Retrieval: Implementing and
Evaluating Search Engines