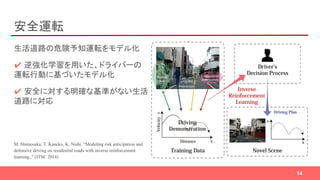
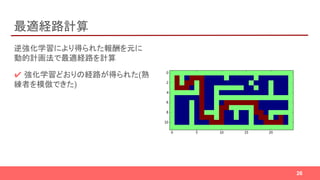
行動予測
人の行動軌跡から、「人の好む経路」を
学習
✔ 行き先を指定して、「どの経路を通る
か」を推定できる
✔ 芝生、歩道… などの属性の価値を
推定しているので、別シーンへの適用
も可能
Kris Kitani, Brian D. Ziebart, J. Andrew Bagnell, and Martial
Hebert, "Activity Forecasting," European Conference on
Computer Vision (ECCV), October, 2012.
13
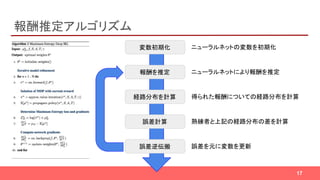
論文概要
タイトル: Maximum EntropyDeep Inverse Reinforcement Learning
著者: Markus Wulfmeier, Peter Ondruska, Ingmar Posner
✔ IRL の1手法である Maximum Entropy IRL を拡張
✔ ニューラルネットを用い、複雑で非線形な報酬関数を近似
✔ 簡単な実験で現時点で State of Art な手法(GPIRL)と同等以上の精度が、
高速に得られた
16

























![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Hindsight Experience Replay](https://cdn.slidesharecdn.com/ss_thumbnails/her-180105002310-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[DL輪読会]Learning Robust Rewards with Adversarial Inverse Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/180201dllearningrobustrewardswithadversarial3-180205170610-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Learning an Embedding Space for Transferable Robot Skills](https://cdn.slidesharecdn.com/ss_thumbnails/dlshioya201803021-180323034512-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)












