Downloaded 62 times


















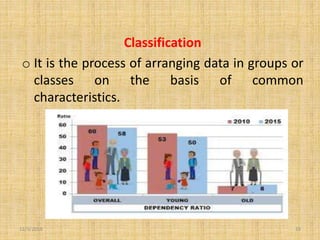











The document outlines various methods of data collection and processing, including experiments, surveys, interviews, questionnaires, and case studies. It emphasizes the importance of accurate data collection for research integrity and describes data processing operations such as editing, coding, classification, and tabulation. The conclusions highlight that effective data processing is crucial for scientific studies to facilitate relevant comparisons and analyses.



































































