Downloaded 74 times









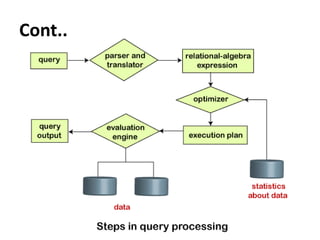







The document discusses measures of query cost in database management systems. It explains that query cost can be measured by factors like the number of disk accesses, size of the table, and time taken by the CPU. It further breaks down disk access time into components like seek time, rotational latency, and sequential vs. random I/O. The document then provides an example formula to calculate estimated query cost based on these components.























































































