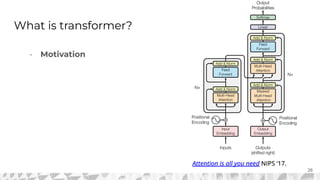
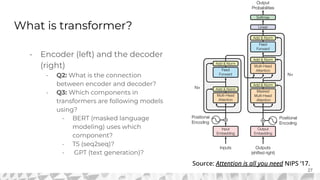
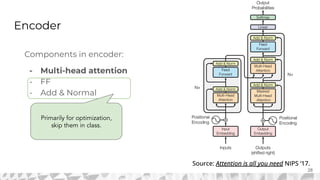
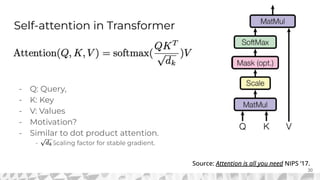
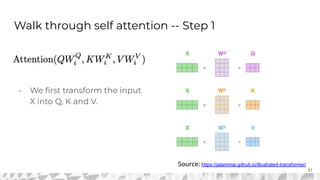
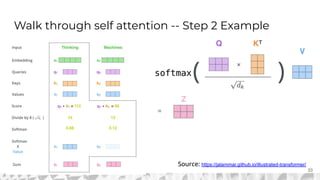
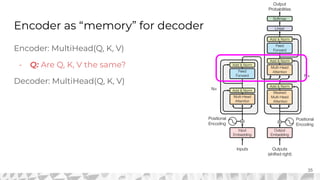
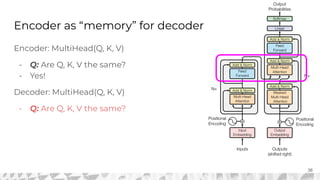
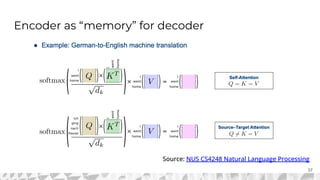
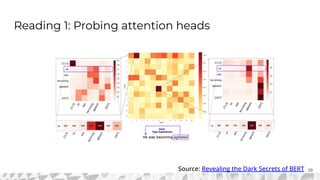
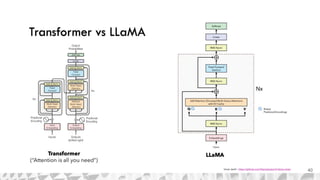
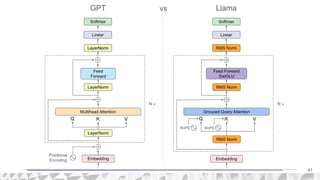
The document outlines various models for language representation, including n-gram, MLP, RNNs, LSTMs, and transformers, with a focus on the transition from count-based models to neural probabilistic approaches. It highlights the limitations of n-gram models regarding context and proposes using embeddings to better capture semantic similarities between words. Additionally, the document discusses the architecture of transformers, emphasizing the roles of self-attention mechanisms and multi-head attention in improving natural language processing tasks.





![In the first place, what are language models?
Language models determine the probabilities of a series of words
Example: Find the probability of a word w given some sample text history h
W = “the”, h = “its water is so transparent that”
“Chain rule of probability” - Conditional probability of a word given previous words
P(“its water is so transparent that the”) = P(“its”) x “P(“water”|”its”) x P(“is” | “its water”).... x
P(“the”|”its water is so transparent that”)
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-6-320.jpg)
![bi-gram
Approximates conditional probability of a word given by using only
the conditional probability of the preceding word
P(“its water is so transparent that the”) = P(“its”) x “P(“water”|”its”) x P(“is” |
“water”).... x P(“the”| that”)
P(“the|the water is so transparent that”) = P(“the”|”that”)
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-7-320.jpg)
![bi-gram
Approximates conditional probability of a word given by using only
the conditional probability of the preceding word
We assume we can predict the probability of a future unit without
looking far into the past
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-8-320.jpg)
![n-gram
Approximates conditional probability of a word given by using only the
conditional probability of the (n-1) words
To estimate these probabilities, we use maximum likelihood estimation:
1) Getting counts of the n-grams from a given corpus
2) Normalizing the counts so they lie between 0 and 1
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-9-320.jpg)
![Issues with “count-based” approximations
Language is a creative exercise, many different permutations of
words could have the same meaning.
Probability would be zero if n-gram is absent in the corpus and not
dealt with (Sparse data problem).
Large amount of memory required - for a language with a
vocabulary of words with an -gram language model, we would
need to store values
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-10-320.jpg)
![A neural probabilistic language model
1) Take into consideration words of similar meaning
2) Should be able to take into consideration “longer” contexts
without incurring large memory resources
Ex: “The cat is walking in the bedroom” should be similar to ‘A dog
was running in a room”
TLDR: Instead of storing the permutations, lets learn an embedding of each token in the
vocab given the context.
[Bengio03]: Benjio et. al. (2003) “A Neural Probabilistic Language Model”
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-11-320.jpg)
![A neural probabilistic language model
Main ideas:
1) Associating each word in the vocabulary with a word feature
vector
2) Expressing the joint probability function of word sequences in
terms of the word feature vectors
[Bengio03]: Benjio et. al. (2003) “A Neural Probabilistic Language Model”
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-12-320.jpg)
![A neural probabilistic language model
Ex: “The cat is walking in the bedroom” should be similar to ‘A dog
was running in a room”
“the” should be similar to “a”
“Bedroom” should be similar to “room”
“Running” should be similar to “walking”
Hence, we should be able to generalize from “The cat is walking in
the bedroom” to “A dog was running in a room”, as similar words are
expected to have similar feature vectors
[Bengio03]: Benjio et. al. (2003) “A Neural Probabilistic Language Model”
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-13-320.jpg)
![Neural network architecture proposed by Bengio et al., 2003
Embedding Layer
Hidden Layer
Probability Layer
[Bengio03]: Benjio et. al. (2003) “A Neural Probabilistic Language Model”
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”
A neural probabilistic language model](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-14-320.jpg)
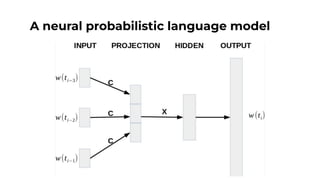
![Embedding Layer
A mapping from a word to a vector that describes it
Represented by a matrix, where represents the size of
vocabulary and represents the size of vector (30 - 100 in Bengio et
al., 2003)
Embeddings here are trained via the task at hand (predicting the
next word given a context)
[Bengio03]: Benjio et. al. (2003) “A Neural Probabilistic Language Model”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-16-320.jpg)
![Hidden Layer
It transforms input sequences of feature vectors and capture
contextual information
In the paper, a multi-layered perceptron was used, with hyperbolic
tangent functions included if hidden layers are used
[Bengio03]: Benjio et. al. (2003) “A Neural Probabilistic Language Model”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-17-320.jpg)
![Probability Layer
Produces a probability distribution over the words in the vocabulary
through the use of the softmax function
Output is a vector, where the i-th index of the vector represents
[Bengio03]: Benjio et. al. (2003) “A Neural Probabilistic Language Model”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-18-320.jpg)
![Effectiveness of the model
Test perplexity improvement of 24% compared to n-gram models
Able to take advantage of more contexts (2-gram to 4-gram contexts
benefitted the MLP approach, but not for the n-gram approach)
Inclusion of the hyperbolic tangent functions as hidden units
improved the perplexity of a given model
[Bengio03]: Benjio et. al. (2003) “A Neural Probabilistic Language Model”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-19-320.jpg)
![Limitations of N-gram models
Not able to grasp relations longer than window size (learning a 6
word relation with a 5-gram neural network is not possible)
Cannot model “memory” in the network (n-gram would only have
the context of (n-1) words.
The man went to the bank to deposit a check.
The children played by the river bank.
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-20-320.jpg)
![Need for Sequential modelling
In N-gram: For one word only one embedding. Does not take
context (memory) into account.
[Kaduri22]: Kaduri (2022) “From N-grams to CodeX”
[Jurafsky23]: Jurafsky et al. (2023) “Speech and Language Processing”](https://image.slidesharecdn.com/lectures10-11representationcapacitylargelanguagemodels-241217174626-00562243/85/Lectures-10-11_-Representation-Capacity-Large-Language-Models-pdf-21-320.jpg)